Outcome of this checklist
This checklist helps a content team answer one practical question:
Are we giving ChatGPT enough clear, verifiable, extractable information to mention our brand for the prompts that matter?
It is not a promise that ChatGPT will recommend you. No checklist can guarantee that. But it will show where your visibility system is weak: brand entity, prompt coverage, content structure, evidence, technical access, or measurement.
Use it when:
- ChatGPT recommends competitors but not your brand
- Your brand is described incorrectly in AI answers
- Your content ranks in Google but is not cited by AI tools
- Leadership wants to know whether the company is ready for GEO
- The content team needs a practical workflow, not another abstract AI SEO deck
Score each section from 0 to 2.
| Score | Meaning |
|---|---|
| 0 | Missing or unclear |
| 1 | Partially present but inconsistent |
| 2 | Clear, useful, and ready to measure |
A total score under 8 means you should fix foundations. A score from 8 to 14 means you have enough to run a focused GEO sprint. A score above 14 means you should invest in prompt tracking, evidence building, and content refresh cycles.
The checklist at a glance
| Area | What you are checking | Score |
|---|---|---|
| Prompt baseline | Do we know which prompts matter? | 0-2 |
| Brand entity clarity | Can AI systems understand who we are? | 0-2 |
| Core page coverage | Do we have pages for buyer and category prompts? | 0-2 |
| Extractable content | Can answers be lifted from our pages? | 0-2 |
| Third-party evidence | Can outside sources verify our claims? | 0-2 |
| Technical access | Can important pages be crawled and parsed? | 0-2 |
| Comparison readiness | Can AI systems compare us fairly? | 0-2 |
| Measurement loop | Are we tracking mentions, citations, and accuracy? | 0-2 |
Maximum score: 16.

Check 1: prompt baseline
Most teams skip this step and start rewriting pages. That is backwards.
Before changing content, build a small prompt set.
Use at least 25 prompts:
| Prompt group | Minimum prompts | Example |
|---|---|---|
| Brand | 5 | "What is [brand]?" |
| Category | 5 | "What are the best tools for [category]?" |
| Problem | 5 | "How do I solve [specific problem]?" |
| Comparison | 5 | "[Brand] vs [competitor] for [use case]" |
| Buyer decision | 5 | "Which [category] tool should a [specific team] choose?" |
Score yourself:
| Score | Criteria |
|---|---|
| 0 | No prompt set exists |
| 1 | A few ad hoc prompts exist, but they are not grouped or tracked |
| 2 | A reusable prompt library exists with brand, category, problem, comparison, and buyer prompts |
What to fix:
- Add prompts that sound like real buyer questions
- Include competitor and alternative prompts
- Include prompts for specific audiences and use cases
- Save answers with date, platform, prompt wording, and citations
Check 2: brand entity clarity
ChatGPT cannot reliably recommend a brand it cannot classify.
Your brand entity should answer:
| Question | Your answer |
|---|---|
| What is the brand name? | |
| What category does it belong to? | |
| Who is it for? | |
| What problem does it solve? | |
| What use cases does it support? | |
| What makes it different? | |
| Which competitors or alternatives define the market? |
Score yourself:
| Score | Criteria |
|---|---|
| 0 | Brand positioning is vague or inconsistent |
| 1 | Category and audience are stated, but not consistently across sources |
| 2 | Brand name, category, audience, use case, differentiator, and related entities are clear across key pages |
What to fix:
- Rewrite the About page with factual category language
- Add Organization schema with
sameAsprofiles - Update LinkedIn, directories, review profiles, and product listings
- Remove outdated product descriptions where possible
- Standardize one short brand entity block across owned profiles
Useful template:
[Brand] is a [category] for [audience] that helps teams [primary job]. Teams use it to [use case 1], [use case 2], and [use case 3]. It is often compared with [competitors] when buyers need [decision context].
Check 3: core page coverage
A homepage is not enough.
AI systems need pages that explain your brand from different buyer angles.
Check whether these pages exist:
| Page type | Exists? | Notes |
|---|---|---|
| About page | ||
| Product or service page | ||
| Category page | ||
| Use-case pages | ||
| Comparison pages | ||
| Alternatives pages | ||
| FAQ or glossary pages | ||
| Case studies or evidence pages | ||
| Documentation or help pages |
Score yourself:
| Score | Criteria |
|---|---|
| 0 | Mostly homepage and generic blog posts |
| 1 | Some product/use-case pages exist but coverage is incomplete |
| 2 | Core entity, category, use-case, comparison, FAQ, and evidence pages exist and are internally linked |
What to fix:
- Build one category page for the market language buyers use
- Build 2-3 use-case pages for high-value prompts
- Add one comparison or alternatives page if competitors dominate AI answers
- Add a glossary/FAQ page for recurring questions
- Link pages together naturally
Check 4: extractable content
A page can be well-written and still hard for AI systems to use.
Check whether your important pages include:
| Element | Present? |
|---|---|
| Short answer near the top | |
| Clear definition or scope | |
| Descriptive headings | |
| Comparison tables | |
| Named examples | |
| Specific product or service facts | |
| Evidence or proof points | |
| FAQ based on real questions | |
| Related internal links |
Score yourself:
| Score | Criteria |
|---|---|
| 0 | Pages rely on vague marketing copy |
| 1 | Some clear sections exist, but key facts are buried |
| 2 | Important pages include direct answers, examples, tables, FAQs, and proof points |
What to fix:
- Add a direct answer box at the top of key pages
- Replace vague claims with specific product facts
- Add tables for comparisons and criteria
- Add examples that match real buyer situations
- Turn recurring sales questions into FAQ sections
If you need a deeper explanation of this layer, read the guide to Generative Engine Optimization .
Check 5: third-party evidence
Your website defines your brand. Other sources help verify it.
Check your evidence footprint:
| Evidence source | Present? | Quality notes |
|---|---|---|
| Review profiles | ||
| Industry directories | ||
| Partner pages | ||
| Case studies | ||
| Customer stories | ||
| Integration listings | ||
| Guest articles or interviews | ||
| Independent comparisons | ||
| Documentation or changelogs | ||
| Original data or benchmarks |
Score yourself:
| Score | Criteria |
|---|---|
| 0 | Few credible sources mention the brand |
| 1 | Some evidence exists, but category or use-case signals are weak |
| 2 | Multiple credible sources confirm the brand's category, use cases, and claims |
What to fix:
- Update review and directory profiles with consistent category language
- Add partner and integration pages where relevant
- Publish case studies with specific context and constraints
- Earn category-relevant mentions instead of generic backlinks
- Build evidence around buyer questions, not only brand announcements
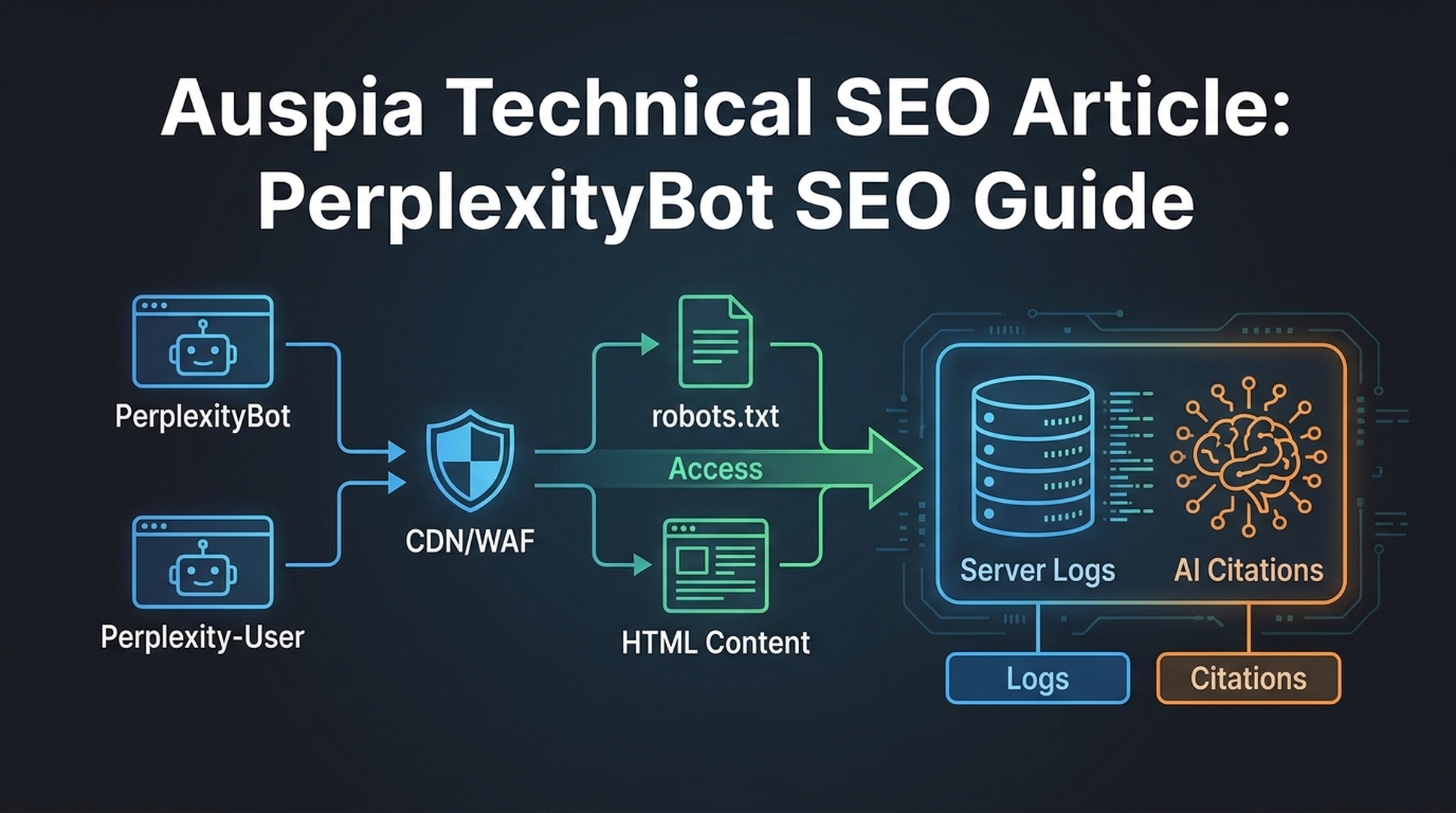
Check 6: technical access
Technical problems can block otherwise good content.
Run these checks:
| Technical check | Pass? |
|---|---|
| Important pages are not blocked in robots.txt | |
| Core pages are in the sitemap | |
| Main content is available in readable HTML | |
| Canonicals point to the correct source pages | |
| Internal links expose entity, product, and evidence pages | |
| Organization, Product, Article, FAQ, or Breadcrumb schema is used where useful | |
| Pages load reliably without server errors | |
| Important content is not only inside images or inaccessible scripts |
Score yourself:
| Score | Criteria |
|---|---|
| 0 | Crawl, rendering, or blocking issues exist |
| 1 | Most pages are accessible, but structure or discovery is inconsistent |
| 2 | Core pages are crawlable, linked, structured, and reliable |
What to fix:
- Check robots.txt for accidental blocks
- Add important pages to sitemap
- Make main text readable in HTML
- Add schema only where it clarifies meaning
- Strengthen internal links between category, product, comparison, and evidence pages
Check 7: comparison readiness
AI systems often answer buyer questions by comparing options.
If you do not provide fair comparison context, competitors and third-party pages may define your position for you.
Check whether your site answers:
| Question | Answered? |
|---|---|
| Who is this product best for? | |
| Who is it not best for? | |
| What alternatives should buyers compare? | |
| What are the decision criteria? | |
| Which use cases are strongest? | |
| What limitations should buyers know? | |
| How does pricing or setup compare? |
Score yourself:
| Score | Criteria |
|---|---|
| 0 | No useful comparison or alternatives content |
| 1 | Some comparison content exists, but it is one-sided or thin |
| 2 | Comparison assets explain fit, tradeoffs, alternatives, and buyer criteria clearly |
What to fix:
- Publish honest comparison pages
- Add alternatives pages for high-intent competitor prompts
- Include decision criteria, not just feature lists
- State who should not choose your product
- Use tables where they help users and AI systems compare options
Check 8: measurement loop
GEO work fails when nobody measures it.
Track these metrics:
| Metric | What it tells you |
|---|---|
| Brand mention rate | How often your brand appears across prompts |
| Competitor mention rate | Which competitors dominate answers |
| Citation rate | Whether your site or third-party sources are cited |
| Answer accuracy | Whether your brand is described correctly |
| Source mix | Which domains shape the answer |
| Prompt coverage | Which buyer questions include or exclude you |
| Sentiment | Whether the answer frames you positively, neutrally, or negatively |
Score yourself:
| Score | Criteria |
|---|---|
| 0 | No repeatable tracking exists |
| 1 | Manual checks happen, but not on a fixed prompt set |
| 2 | Prompt tracking, competitor overlap, citations, and answer accuracy are reviewed on a schedule |
What to fix:
- Track the same prompt set every two to four weeks
- Save answer text, citations, and screenshots where useful
- Record model/platform, date, location, and prompt wording
- Compare competitor overlap over time
- Connect findings to content and evidence updates

Score interpretation
Add your scores.
| Total score | What it means | Next action |
|---|---|---|
| 0-4 | Not ready | Fix brand entity and technical access first |
| 5-8 | Early foundation | Build core pages and extractable answer sections |
| 9-12 | Ready for a GEO sprint | Run prompt tracking and rebuild priority assets |
| 13-16 | Strong foundation | Invest in evidence, comparisons, and measurement cadence |
Do not treat the score as a vanity metric. Use it to choose the next sprint.
A 7-day action plan
If you want to move quickly, use this first sprint.
| Day | Task | Output |
|---|---|---|
| 1 | Build 25-prompt baseline | Prompt library and initial answers |
| 2 | Audit brand entity | Correct brand facts and profile gaps |
| 3 | Review top five pages | Extractability notes and missing sections |
| 4 | Check competitor evidence | Evidence gap table |
| 5 | Fix one core page | Short answer, table, FAQ, proof points |
| 6 | Update profiles and internal links | Cleaner entity and discovery signals |
| 7 | Rerun key prompts | Before/after notes and next sprint priorities |
This is enough to find the real bottleneck.
It may be content. It may be evidence. It may be entity clarity. It may be technical access. The point is to stop arguing in the abstract.
Common mistakes
| Mistake | Why it hurts |
|---|---|
| Starting with 50 new blog posts | You may multiply unclear positioning |
| Tracking only brand-name prompts | Buyers often ask category and comparison prompts |
| Ignoring third-party evidence | AI systems need more than your own claims |
| Writing fake-neutral comparison pages | Users and AI systems both need real tradeoffs |
| Treating schema as the whole fix | Markup clarifies content; it does not create trust by itself |
| Checking ChatGPT once and declaring success | AI answers vary. Track a prompt set over time |
Auspia take
The best ChatGPT visibility checklist is not a list of hacks.
It is a way to find the weakest layer in your AI search visibility system.
If ChatGPT does not know who you are, fix the entity. If it knows who you are but does not recommend you, fix category association and evidence. If it cites competitors instead, rebuild the pages and sources that answer buyer prompts. If you cannot tell whether anything changed, fix measurement.
That is the work.
Not glamorous. Very useful.
FAQ
What is a ChatGPT visibility checklist?
A ChatGPT visibility checklist is a practical audit of the signals that help a brand appear in AI answers: prompt coverage, brand entity clarity, core pages, extractable content, third-party evidence, technical access, comparison readiness, and measurement.
Can this checklist guarantee that ChatGPT recommends my brand?
No. It can show whether your brand gives AI systems enough clear and verifiable information to work with. Recommendations still depend on the prompt, model, retrieval behavior, sources, and competition.
How often should we run this checklist?
Run it before a GEO sprint, after major website updates, and at least once per quarter if AI search visibility matters to your growth strategy.
What is the most important section?
Start with prompt baseline and brand entity clarity. If you do not know which prompts matter, or AI systems cannot classify your brand, the rest of the work becomes less focused.
Should content teams or SEO teams own this?
Both should be involved. Content teams usually own answer structure and page coverage. SEO teams own crawlability, internal links, and search intent. Brand, PR, product marketing, and analytics often need to support evidence and measurement.
How many prompts should we track?
Start with 25. Use five brand prompts, five category prompts, five problem prompts, five comparison prompts, and five buyer decision prompts. Expand once the process is repeatable.
Author: Martin Hayes, GEO Playbook Builder for 200+ Execution Checklists at Auspia. Martin writes step-by-step GEO workflows, tactical audits, and operating checklists for search and content teams.