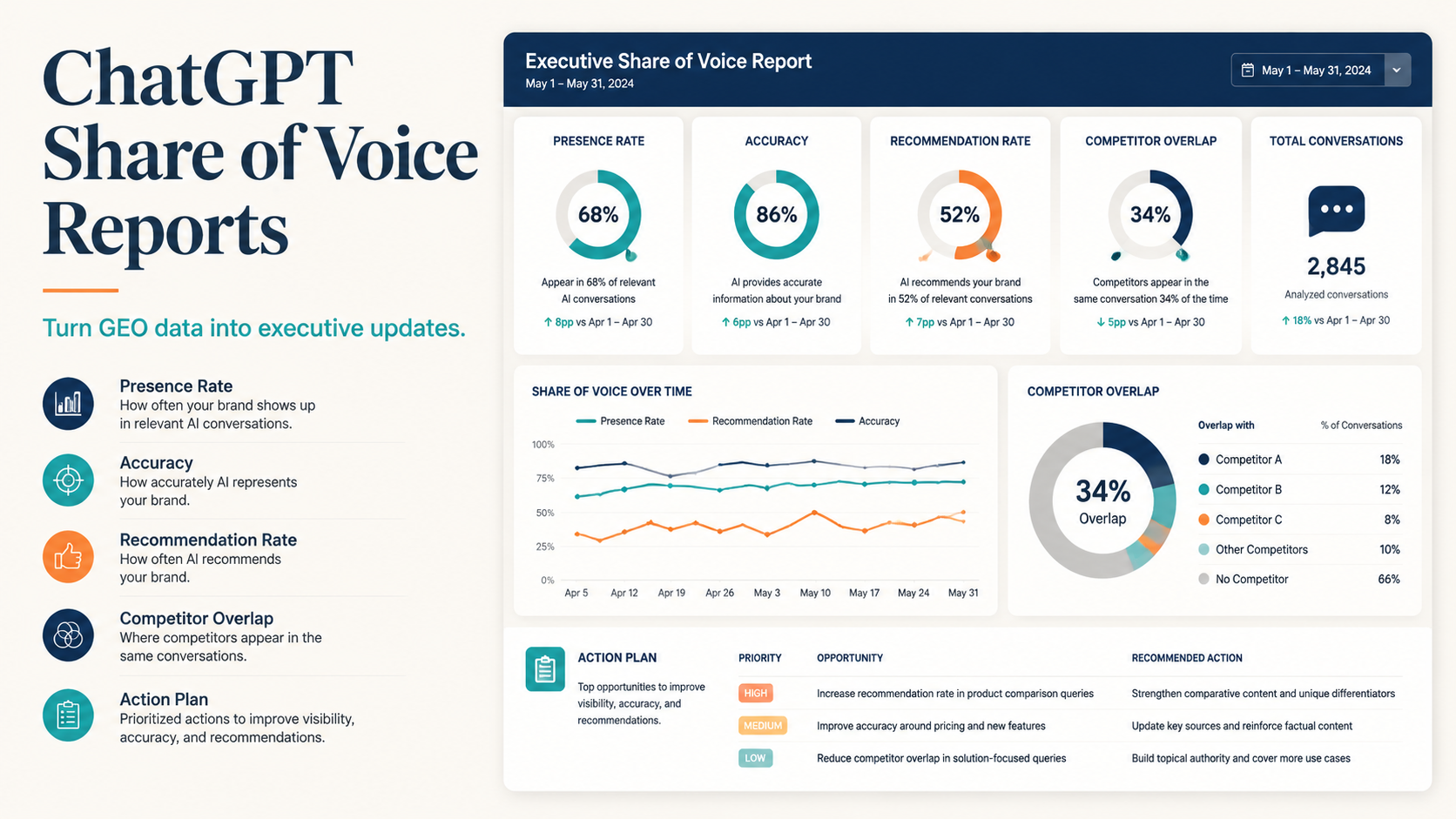
Rankings are not enough
You cannot measure Perplexity SEO with a normal rank tracker alone.
Google SEO reporting asks, "Where do we rank, how often do people see us, and how many clicks did we earn?" Perplexity SEO asks a different set of questions:
| Measurement question | Why it matters |
|---|---|
| Are we mentioned in AI answers? | Brand exposure can happen before a click. |
| Are our URLs cited? | Citations show whether Perplexity uses your pages as sources. |
| Which claim is attached to our brand? | Bad or vague descriptions can hurt trust. |
| Which competitors appear near us? | AI answers create shortlists, not just traffic. |
| Do cited pages earn referral traffic? | Citation value should connect back to business outcomes. |
| What changed after our updates? | GEO needs a repeatable learning loop. |
A good Perplexity SEO report blends prompt testing, citation tracking, answer-quality review, referral analytics, and conversion notes. It will never be as clean as a simple ranking chart. That is fine. The goal is directionally useful evidence, not fake precision.
Build a prompt library first
Perplexity measurement starts with prompts, not keywords.
Keywords are still useful for Google search demand, but Perplexity users ask full questions. A prompt library captures those questions and lets you test visibility consistently over time.

A simple prompt library should include:
| Field | Example |
|---|---|
| Prompt group | Category discovery |
| Prompt | "What are the best tools to measure AI search visibility?" |
| User intent | Build a shortlist |
| Target page | AI Search Visibility Checker page |
| Desired brand claim | Auspia helps teams track AI search mentions and citations |
| Competitors to watch | Other AI SEO or GEO tools |
| Test cadence | Weekly or biweekly |
| Notes | Check whether cited URLs are product pages, blogs, or third-party pages |
Do not overload the library. Start with 20-40 prompts that map to real buyer behavior.
Choose prompt groups that match the buyer journey
A useful prompt set covers more than one query type.
| Prompt group | Example prompt | What to measure |
|---|---|---|
| Problem diagnosis | "Why is my brand not showing up in AI search results?" | Whether your brand appears as a solution or source |
| Category discovery | "Best tools for tracking Perplexity citations" | Mentions, competitors, cited sources |
| Technical implementation | "How do I allow AI crawlers in robots.txt?" | Whether your technical guide or tool page is cited |
| Comparison | "Perplexity SEO vs Google SEO" | Whether your comparison page is cited or summarized |
| Vendor shortlist | "Which GEO tools should a SaaS company compare?" | Brand inclusion, position, sentiment |
| Use-case | "How can content teams write pages for AI citations?" | Source fit and content-structure visibility |
| Branded validation | "Is Auspia useful for AI search visibility?" | Accuracy, sources, competitor context |
Avoid prompts that force the answer to mention you. "Tell me about Auspia" is useful for brand accuracy, but it does not test category visibility. You need both branded and non-branded prompts.
Track the citation metrics that matter
A Perplexity SEO report should capture what the answer says and what it cites.
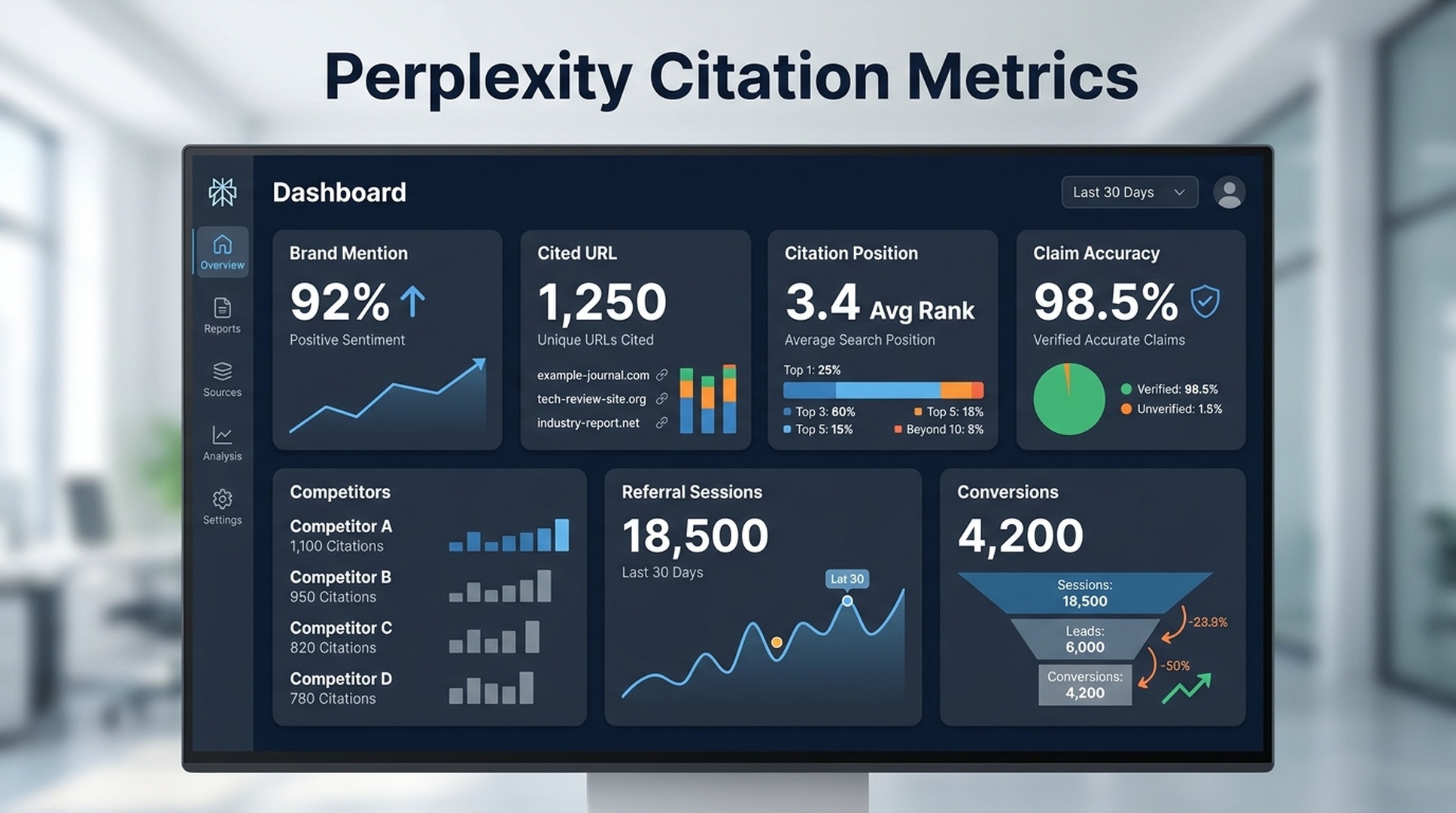
Use these fields:
| Metric | What to record |
|---|---|
| Brand mentioned | Yes/no and exact brand wording |
| Mention position | Early answer, middle, buried, or follow-up only |
| URL cited | Exact cited URL, if present |
| Source type | Owned page, third-party article, docs, review page, directory, report |
| Citation position | First citation, supporting citation, or low-visibility citation |
| Claim attached | What the answer says your page proves |
| Answer accuracy | Accurate, partially accurate, vague, or wrong |
| Competitors present | Brands or domains appearing in the same answer |
| Sentiment | Positive, neutral, mixed, or inaccurate |
| Follow-up behavior | Whether follow-up prompts keep or drop your brand |
The "claim attached" field is underrated. A citation is not automatically good. If Perplexity cites your page but describes the product incorrectly, that is an entity or content clarity problem.
Measure referral traffic without overclaiming
Referral traffic from Perplexity can be valuable, but it will not tell the whole story.
Check analytics for:
- referrals from Perplexity domains
- landing pages that receive those sessions
- engagement time
- next page path
- tool usage
- demo or signup events
- assisted conversions
- later branded search or direct return patterns
Expect gaps. Some users will read the answer and not click. Some will later search your brand on Google. Some may visit directly from another browser or device. That does not make Perplexity invisible. It means your report should combine qualitative answer tracking with quantitative traffic data.
A practical table:
| Signal | How to interpret it |
|---|---|
| More mentions, no traffic | Brand awareness is rising, but sources may not earn clicks yet |
| More citations, low engagement | The cited page may not match visitor intent |
| Referrals to blog pages only | Add stronger internal paths to tools, demos, or checklists |
| Branded search rises after visibility gains | Possible assisted discovery, not proof by itself |
| Competitors cited more often | Content, evidence, or entity gap to investigate |
Do not call every branded visit a Perplexity conversion. Be honest. The report is stronger when it separates evidence from interpretation.
Create a weekly reporting template
A Perplexity SEO report should be short enough for a growth team to read and specific enough to drive action.
Use this format:
| Section | What to include |
|---|---|
| Executive summary | 3-5 bullet points on what changed |
| Prompt coverage | Number of prompts tested and prompt groups |
| Brand visibility | Mention rate, citation rate, answer accuracy |
| Cited pages | Top owned URLs cited and missing target URLs |
| Competitor view | Brands/domains appearing most often |
| Referral quality | Sessions, landing pages, events, assisted notes |
| Fix backlog | Technical, content, entity, and evidence actions |
| Next test | Prompt groups and pages to retest next cycle |
A simple scorecard can work well:
| Area | Score | Notes |
|---|---|---|
| Prompt visibility | 2/5 | Brand appears in 8 of 30 prompts, mostly branded prompts |
| Citation quality | 3/5 | Two owned URLs cited, but one claim is vague |
| Answer accuracy | 4/5 | Product category mostly correct |
| Competitive presence | 2/5 | Three competitors appear more often in category prompts |
| Referral path | 2/5 | Blog referrals do not reach tool pages often enough |
| Fix priority | High | Rewrite comparison page and add tool CTA to cited guide |
This is more useful than a dashboard full of numbers no one acts on.
Set a measurement cadence
Do not test randomly every day and panic over fluctuations.
Perplexity answers can change because of source freshness, query phrasing, model behavior, retrieval differences, and personalization or location effects. You need consistency.
Recommended cadence:
| Cadence | Use case |
|---|---|
| Weekly | Active optimization sprint, new content launch, technical fixes |
| Biweekly | Normal GEO monitoring for stable topics |
| Monthly | Executive reporting and trend review |
| Same-day spot check | Major site migration, robots.txt change, WAF update, content relaunch |
Keep prompt wording stable for trend reporting. Add new prompts when user behavior changes, but do not rewrite the whole library every week.
If the report shows low citation quality, use the guide on how to get cited by Perplexity . If the report shows weak traffic or low engagement, move to Perplexity referral traffic .
Connect measurement to fixes
Measurement is only useful if it changes the work.
| Finding | Likely fix |
|---|---|
| Brand not mentioned in category prompts | Add category guide, comparison page, external evidence, and clearer entity signals |
| Page cited but claim is vague | Rewrite answer block, product description, and fact table |
| Competitors cited for technical prompts | Create or improve technical docs and crawler-access pages |
| Third-party pages describe you incorrectly | Update directories, partner pages, review profiles, and About page language |
| Perplexity referrals bounce | Improve cited-page intro, CTA, internal links, and next-step offer |
| Owned pages never cited | Check crawl access, source structure, evidence, and query fit |
This loop is the heart of Perplexity SEO: prompt, observe, diagnose, fix, retest.
Example: a measurement workflow for one page
Suppose you publish a guide about PerplexityBot access.
Target prompts might include:
- "How do I allow PerplexityBot in robots.txt?"
- "What is Perplexity-User?"
- "How can I check if AI crawlers can access my website?"
- "Why is my site not cited by Perplexity?"
- "Tools to check robots.txt rules for AI crawlers"
For each prompt, record:
| Prompt | Brand mentioned | URL cited | Claim accuracy | Competitors | Fix note |
|---|---|---|---|---|---|
| How do I allow PerplexityBot in robots.txt? | No | No | N/A | Official docs, SEO blogs | Add clearer robots examples and source links |
| Tools to check robots.txt rules for AI crawlers | Yes | Tool page | Accurate | Two crawler tools | Improve tool page CTA and comparison section |
| Why is my site not cited by Perplexity? | Yes | Blog guide | Vague | Multiple GEO blogs | Add diagnostic table and stronger entity facts |
The point is not to win every prompt. The point is to find the next fix.
FAQ
How do you measure Perplexity SEO?
Measure Perplexity SEO with a prompt library, brand mention tracking, cited URL tracking, citation position, answer accuracy, competitor presence, referral sessions, and downstream behavior. Rankings alone are not enough.
What is a prompt library?
A prompt library is a stable set of questions used to test how your brand appears in AI answers. It should include category, problem, comparison, technical, use-case, and branded prompts that match real buyer behavior.
How often should I check Perplexity visibility?
Weekly or biweekly is enough for most active programs. Use weekly checks during optimization sprints or after major technical/content changes. Use monthly summaries for executive reporting.
What is a good Perplexity citation rate?
There is no universal benchmark. Citation rate depends on category, prompt type, source competition, freshness, and brand authority. Track your own baseline first, then measure improvement by prompt group.
Should I track only owned URLs?
No. Track owned URLs, third-party pages, review profiles, directories, partner pages, and competitor sources. Perplexity may cite external pages when describing your category or brand.
How do I connect Perplexity citations to revenue?
Track referral sessions, landing pages, tool usage, demo events, assisted conversions, and later branded-search movement. Be careful with attribution. Treat Perplexity as one influence point in a research journey, not always the final click.
Sources
- Perplexity Help Center: How does Perplexity work?
- Perplexity Docs: Perplexity crawlers
- Perplexity Docs: API overview
Auspia takeaway
Perplexity SEO measurement is not a rank report with a new label. It is a visibility and evidence report.
Track prompts. Record mentions. Check citations. Read the claims. Watch competitors. Review referral quality. Then turn the gaps into technical, content, entity, and evidence fixes.
The best report is not the prettiest dashboard. It is the one that tells your team what to fix next.
Author: Ethan Marlowe, GEO Measurement Lead Across 500+ Prompts at Auspia. Ethan writes about prompt tracking, citation reporting, visibility dashboards, and AI answer quality checks.