The short answer
GEO in 2026 is mostly reverse RAG.
When a user asks ChatGPT, Perplexity, Gemini, Google AI features, or another AI answer system a commercial question, the system often does three things before it answers: it rewrites the query, retrieves candidate sources, and decides which sources deserve to shape the final answer. Generative engine optimization is the discipline of making your pages strong enough to pass those gates.
That sounds simple. It is not. The hard part is that the most important systems are black boxes. We can see our inputs, such as titles, pages, internal links, schema, page speed, and publishing cadence. We can see some outputs, such as whether a source appears in an answer, whether it is cited, and whether traffic or qualified leads follow. We do not see the exact retrieval stack, reranking model, or synthesis logic.
So the practical question is not "what is the one GEO tactic?" The better question is:
Which part of the RAG pipeline are we trying to influence, and what evidence tells us that the change worked?
Auspia's view is blunt: teams that treat GEO as a separate content hack will hit a ceiling. Teams that treat GEO as SEO plus retrieval testing, entity clarity, answer design, and citation measurement will compound faster.
For a quick diagnostic before you start, run an AI visibility check with Auspia's AI Search Visibility Checker and compare which pages, sources, and competitors are already being cited.
Why GEO changed in 2026
The old version of GEO advice was mostly page-level advice: add statistics, write in a confident tone, include quotes, use FAQ blocks, publish comparisons, and mention the target keyword. Some of that still helps. But by 2026, the field is more crowded and the answer systems are more layered.
A modern AI answer may depend on:
- the user's original prompt;
- the rewritten queries produced by the AI system;
- Google, Bing, or another commercial search layer;
- a first retrieval pass that pulls candidate pages;
- a reranking step that chooses the useful sources;
- the answer model's own judgment about trust, coverage, freshness, and usefulness;
- whether the final answer needs citations at all;
- whether the user clicks, refines, or ignores the answer.
This is why a page can rank well in Google but fail to appear in AI answers. It is also why a page can appear in the source list but never get cited in the final answer. Retrieval and citation are related, but they are not the same job.
Google's own Search documentation says site owners do not need special AI-only markup for Google's AI features; eligibility comes from the same technical and content controls used for Search, including crawlability, indexability, snippets, previews, and structured data where relevant. That is a useful reality check. GEO does not replace SEO. It makes the SEO system more answer-aware.
Think of GEO as four gates
Most GEO failures become easier to diagnose if you split the pipeline into four gates.
| Gate | What has to happen | Common failure | What to optimize |
|---|---|---|---|
| Query rewrite | The AI system expands the user's prompt into searchable queries | You optimize for the literal prompt, not the actual search terms | Prompt library, search intent mapping, query variants |
| Retrieval | Your page enters the candidate set | The page is not indexed, not relevant enough, or outranked by stronger domains | SEO basics, topical coverage, entity clarity, crawlability |
| Reranking | Your page is judged better than other candidates | The page is relevant but thin, stale, slow, or not answer-shaped | definitions, evidence, comparisons, freshness, UX blocks |
| Synthesis and citation | The answer model uses and cites your page | The page is found but not useful enough to quote or summarize | extractable claims, source quality, tables, named entities, data |
The mistake is optimizing all gates with the same move. Repeating a keyword may help crude retrieval, but it will not necessarily help synthesis. Adding a table may help answer extraction, but it will not matter if the page never enters the candidate set. Publishing a "2026" roundup may help freshness-sensitive queries, but it will not save a slow, uncrawlable, duplicate page.
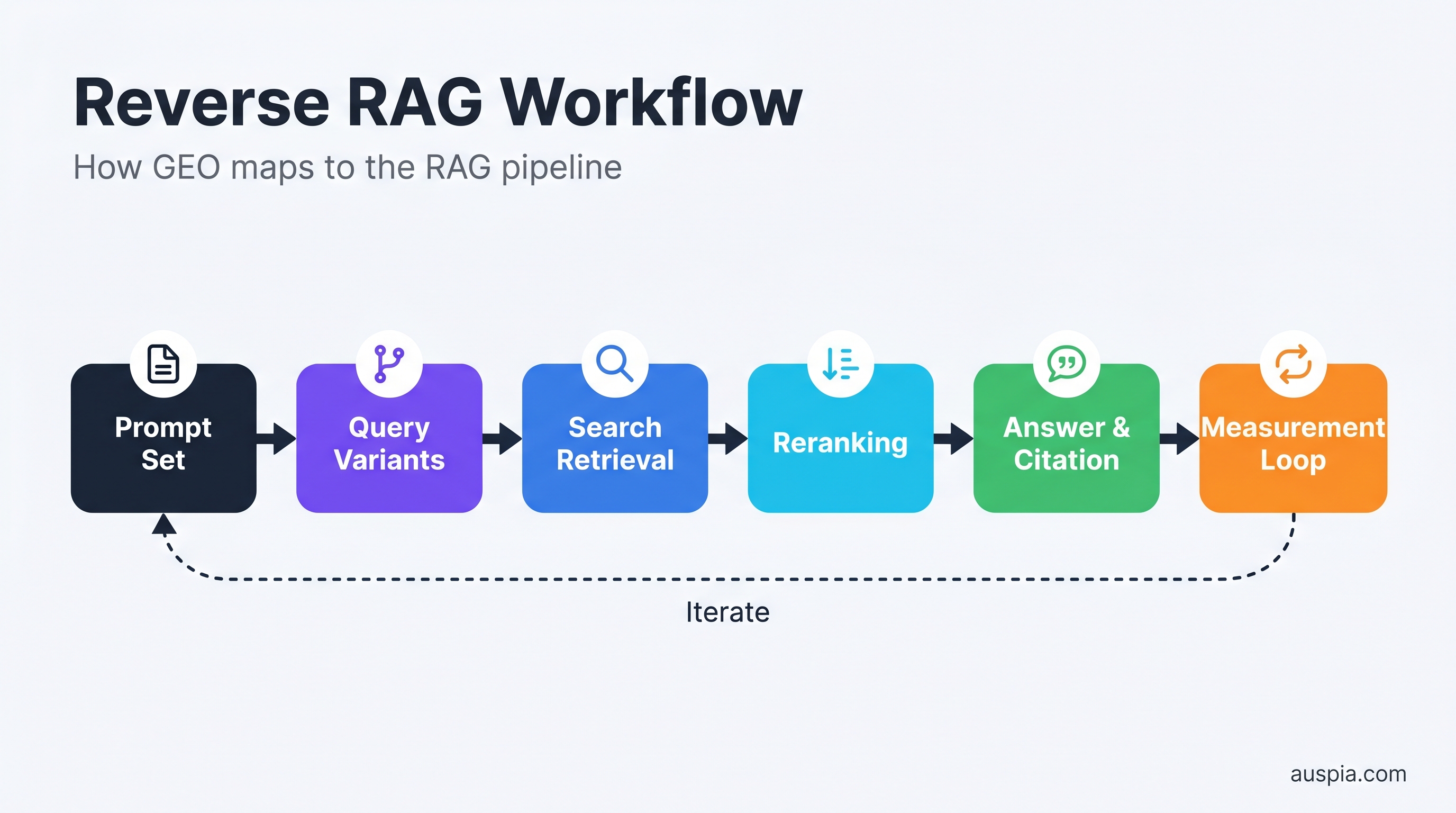
Reverse RAG workflow: map prompts, predict query variants, inspect retrieval, improve reranking signals, and measure whether the final answer cites you.
Gate 1: query rewrite is where many teams start too late
AI systems rarely search with the user's exact wording only. A buyer may ask, "What is the best platform for AI search visibility?" The system may search for variants such as:
- AI search visibility tools;
- GEO software;
- generative engine optimization platform;
- ChatGPT citation tracking;
- AI Overview optimization tools;
- brand visibility in LLM answers.
If your content only covers one phrase, you are betting that the model rewrites the query the way you would. That is a bad bet.
Build a prompt library before writing pages. For each commercial topic, collect 30 to 100 real buyer prompts. Then map them to likely search variants. You can do this manually at first: ask several AI search tools the same question, inspect visible search queries when the interface shows them, and compare the cited sources. Over time, turn the prompt library into a testing asset.
A useful query rewrite worksheet looks like this:
| Buyer prompt | Likely search variant | Needed page type | Current asset | Gap |
|---|---|---|---|---|
| "How do I know if ChatGPT recommends my brand?" | AI search visibility checker | Tool page + explainer | partial | Add measurement workflow |
| "Best GEO tools for SaaS" | GEO software comparison 2026 | Comparison page | missing | Build comparison page |
| "Why is my competitor cited in Perplexity?" | Perplexity SEO citations | Diagnostic article | weak | Add citation audit guide |
| "How to make content citable by AI?" | AI citation optimization | Playbook | present | Add examples and checklist |
This work feels boring. It is also where the leverage is. If your query map is wrong, everything downstream becomes guesswork.
Gate 2: retrieval still depends on SEO
A lot of GEO advice skips the retrieval layer because it feels less new. That is a mistake.
For AI systems that browse or use search APIs, the source pool often starts with traditional search infrastructure. Even when the AI product adds its own reranking layer, the candidate set is still shaped by the same basic questions search engines have cared about for years:
- Can the page be crawled and indexed?
- Does the title match a real search need?
- Does the page cover related terms and entities naturally?
- Is the site fast enough and stable enough to be trusted?
- Does the page sit inside a coherent topic cluster?
- Do internal links make the page easy to discover?
- Does the page have enough authority or external evidence to compete?
This is why GEO and SEO are not enemies. GEO makes weak SEO more visible. If the page cannot get retrieved, the answer model cannot cite it.
For a new GEO page, check these basics before you touch the prose:
| Check | Minimum standard |
|---|---|
| Indexability | Not blocked by robots.txt, no accidental noindex, canonical points to itself or the intended URL |
| Title | Includes the main entity, intent, and freshness signal when relevant |
| Intro | Gives a direct answer in the first 150 words |
| Topic coverage | Includes definitions, use cases, comparisons, mistakes, workflow, and FAQ when the query deserves them |
| Internal links | At least one link from a relevant hub or category page |
| Technical health | Fast mobile rendering, clean HTML, accessible headings, no broken structured data |
| Evidence | Named sources, original examples, data, screenshots, or transparent methodology |
If you need a quick first pass, Auspia's Website SEO Score Checker can catch the obvious crawl, metadata, and structure problems before you invest in GEO testing.
Gate 3: reranking rewards pages that look useful to machines and humans
After retrieval, the system still has to choose. A candidate list of 50 pages is not a citation list. Some of those pages will be ignored because they are stale, vague, duplicate, hard to parse, or too thin to answer the actual question.
This is where many GEO tactics come from. They are not magic; they are attempts to make the page score better when a smaller model or answer model evaluates usefulness.
Patterns that often help:
- a clear definition near the top;
- a visible date or year when freshness matters;
- a comparison table when the query asks for choices;
- named entities instead of generic nouns;
- examples that match the buyer's situation;
- a short answer block before the long explanation;
- a checklist that can be extracted into an answer;
- original observations or data instead of recycled advice;
- author, methodology, or editorial notes when trust matters.
The "2026" marker deserves a careful note. Freshness labels can help when the query has an implied time requirement, such as "best GEO tools in 2026" or "AI Overview optimization 2026." But stamping 2026 on every title is lazy. It works only when the content actually reflects current conditions: tools, platforms, model behavior, interface changes, measurement methods, or market examples.
Good freshness:
GEO Checklist for 2026: AI Citations, Search Retrieval, and Prompt Testing
Bad freshness:
What Is a Title Tag in 2026?
The second title may still rank, but it teaches the wrong habit. Use freshness when freshness is part of the user's need.
Gate 4: citation is different from retrieval
A page can appear in a source list and still lose the citation. This usually means the page passed retrieval but failed synthesis.
Answer models prefer material that is easy to lift into a concise response. That does not mean you should write robotic snippets. It means your page should contain quotable, verifiable, self-contained blocks:
- a one-sentence definition;
- a table with labeled criteria;
- a short method with numbered steps;
- statistics with source context;
- a named framework;
- a limitation or caveat that makes the answer more credible;
- a comparison that resolves a real buyer decision.
For example, this paragraph is weak for citation:
Our platform helps modern teams improve visibility across the changing AI ecosystem with advanced workflows and reliable optimization capabilities.
This version is easier to use:
GEO measurement should track at least four outputs: whether the brand appears in the answer, whether the page is cited, where the citation appears, and whether the cited answer matches the brand's intended positioning.
The second version has a claim, a scope, and a list. It gives the answer model something concrete to reuse.
A practical GEO workflow for 2026
Here is the workflow we recommend when a team wants to improve AI citation visibility without pretending the black box is fully knowable.
Step 1: build the prompt set
Start with prompts, not keywords. Include informational, commercial, comparison, troubleshooting, and brand-adjacent prompts. For a SaaS company, the set might include:
- "What are the best tools for tracking AI citations?"
- "How do I improve brand visibility in ChatGPT?"
- "Why does Perplexity cite my competitor instead of us?"
- "GEO vs SEO: which should we invest in first?"
- "What should a B2B marketing team measure in AI search?"
Run these prompts across the AI answer surfaces you care about. Log the cited domains, cited URLs, answer language, and whether your brand appears.
Step 2: classify the missing gate
For every prompt where you lose, ask which gate failed.
| Symptom | Likely gate | First fix |
|---|---|---|
| Your page is not indexed | Retrieval | Fix crawl/indexing/canonical issues |
| Competitors rank in Google/Bing but you do not | Retrieval | Build stronger SEO page and internal links |
| Your page ranks but is not in AI source list | Reranking | Improve answer match, structure, freshness, evidence |
| Your page appears as a source but is not cited | Synthesis | Add extractable claims, tables, named framework |
| Your brand appears with wrong description | Entity understanding | Fix about page, schema, third-party profiles, consistent wording |
This classification prevents random optimization. You stop arguing about whether to add FAQs and first ask whether the page can even be found.
Step 3: rewrite pages for answer extraction
Do not rewrite the entire site at once. Pick the pages that already sit close to the answer pipeline: pages ranking on page one or two, pages already cited occasionally, and pages that match high-value prompts.
For each page, add:
- a direct answer near the top;
- a definition block if the topic has a named concept;
- a comparison table if the query involves selection;
- a short "when to use / when not to use" section;
- a methodology note if the page ranks products, tools, or vendors;
- a FAQ with real questions, not filler;
- internal links to the relevant category, tool, or hub page.
Step 4: create supporting sources, not just supporting pages
AI answer systems often prefer corroboration. Your own landing page is useful, but third-party evidence can make the brand easier to trust.
Supporting sources may include:
- product documentation;
- comparison pages;
- case studies;
- customer reviews;
- GitHub repositories;
- app marketplace listings;
- partner pages;
- interviews or podcasts;
- credible directories;
- research pages with methodology.
The goal is not spammy PR distribution. The goal is a consistent entity footprint. If the model sees the same brand facts, product category, use cases, and proof points across reliable sources, it has less work to do.
Step 5: measure prompts weekly
A single check tells you almost nothing. AI answers vary by platform, time, location, account state, and query phrasing. Measure a stable prompt set weekly and track movement.
Use a simple scorecard:
| Metric | What it means |
|---|---|
| Brand mentioned | The answer includes the brand name |
| URL cited | A page from your site appears as a citation/source |
| Citation rank | Your source appears early enough to matter |
| Message accuracy | The answer describes the brand correctly |
| Competitor overlap | Which competitors appear in the same answer |
| Query variant sensitivity | Whether small prompt changes remove your brand |
This is also where teams should be honest. If movement only appears on one narrow prompt and disappears everywhere else, you do not have a GEO system yet. You have a lucky example.

AI citation measurement should separate visibility, citation, position, accuracy, and competitor overlap instead of collapsing everything into traffic.
What to test before scaling content
Before publishing hundreds of pages, test the factors that might actually matter in your niche.
A clean test set might compare:
- title with and without 2026;
- short definition intro vs story intro;
- table-heavy page vs prose-heavy page;
- author/methodology note vs no methodology note;
- product comparison page vs educational guide;
- first-party page vs third-party profile;
- page with original data vs page without data.
Keep the test narrow. If you change the title, intro, structure, URL, internal links, and schema at the same time, you will not know what worked.
A better test log looks like this:
| Date | Prompt | Page variant | Change | AI source result | Citation result | Notes |
|---|---|---|---|---|---|---|
| 2026-06-22 | best GEO tools for SaaS | A | Added methodology + 2026 title | Source list: yes | Citation: no | Needs clearer comparison table |
| 2026-06-29 | best GEO tools for SaaS | B | Added table and use-case fit | Source list: yes | Citation: yes, position 3 | Keep format for next cluster |
This is slower than publishing blindly. It is also cheaper than creating a large content library that never enters the answer set.
Common GEO mistakes
The most common mistakes are not subtle.
First, teams copy SEO content and call it GEO. A good SEO article may still be too broad, too slow to answer, or too vague for citation.
Second, teams chase platform tricks. A visible query rewrite or a source list pattern can be useful, but AI products change. Build a measurement loop, not a superstition.
Third, teams ignore the website. If your page is blocked, slow, duplicated, orphaned, or buried under weak internal links, no amount of answer formatting will fix the retrieval problem.
Fourth, teams write without evidence. AI systems are getting better at ignoring pages that sound confident but say nothing specific.
Fifth, teams overuse freshness. A 2026 title attached to a 2024 argument will eventually become a trust problem.
The Auspia take
GEO is not a replacement for SEO. It is SEO under a harsher evaluator.
Traditional search mainly asks, "Should this page rank for this query?" AI answer systems add harder questions: "Can this page help me answer? Can I trust the claim? Is the information easy to extract? Does another source say it better? Should I cite it or just use the idea?"
That is why strong GEO work looks more like an operating loop than a content checklist:
- map prompts;
- identify retrieval gaps;
- strengthen SEO and entity signals;
- rewrite pages for answer extraction;
- build corroborating sources;
- measure citations;
- repeat with controlled tests.
If you are starting from zero, do not begin with a 200-page content sprint. Begin with 20 prompts, 10 competitor citations, 3 rewritten pages, and one weekly measurement dashboard. That is enough to learn what your market's AI answer systems are rewarding.
2026 GEO checklist
Use this checklist before publishing a GEO-targeted page.
| Area | Question |
|---|---|
| Prompt fit | Which buyer prompts should this page answer? |
| Query variants | What rewritten search terms might AI systems use? |
| Retrieval | Is the page crawlable, indexable, fast, and internally linked? |
| Title | Does the title match intent and include freshness only when useful? |
| Direct answer | Can a model extract the answer from the first section? |
| Evidence | Does the page include data, examples, sources, or methodology? |
| Citation blocks | Are there tables, definitions, or steps worth citing? |
| Entity clarity | Are brand, product, category, and use cases stated consistently? |
| Measurement | Which prompts will be tested after publishing? |
| Iteration | What will change if the page is retrieved but not cited? |
FAQ
Is GEO just SEO with a new name?
No. GEO depends on SEO, especially retrieval, crawlability, topical authority, and page quality. But GEO adds answer-specific work: prompt testing, citation measurement, entity consistency, and extractable content design.
Does adding "2026" to the title help GEO?
It can help when the query has freshness intent. It is not a universal ranking factor. Use the year when the page includes current tools, platform behavior, updated examples, or a recent methodology.
What is reverse RAG?
Reverse RAG means studying the retrieval, reranking, synthesis, and citation behavior of AI answer systems from the outside. You cannot see the full pipeline, so you infer it through prompt tests, source tracking, page variants, and repeated measurement.
Why does my page rank in Google but not appear in AI answers?
Ranking is only one gate. The AI system may rewrite the query differently, use another search provider, rerank sources with different criteria, or decide that another page is easier to cite in the final answer.
How many pages should I publish for GEO?
Start small. Rewrite a few pages that already have search visibility or citation potential, then measure them against a stable prompt set. Scale only after you know which formats and evidence types work in your niche.
What should I measure first?
Measure brand mentions, cited URLs, citation position, message accuracy, competitor overlap, and prompt sensitivity. Traffic alone is too late in the funnel to diagnose GEO performance.