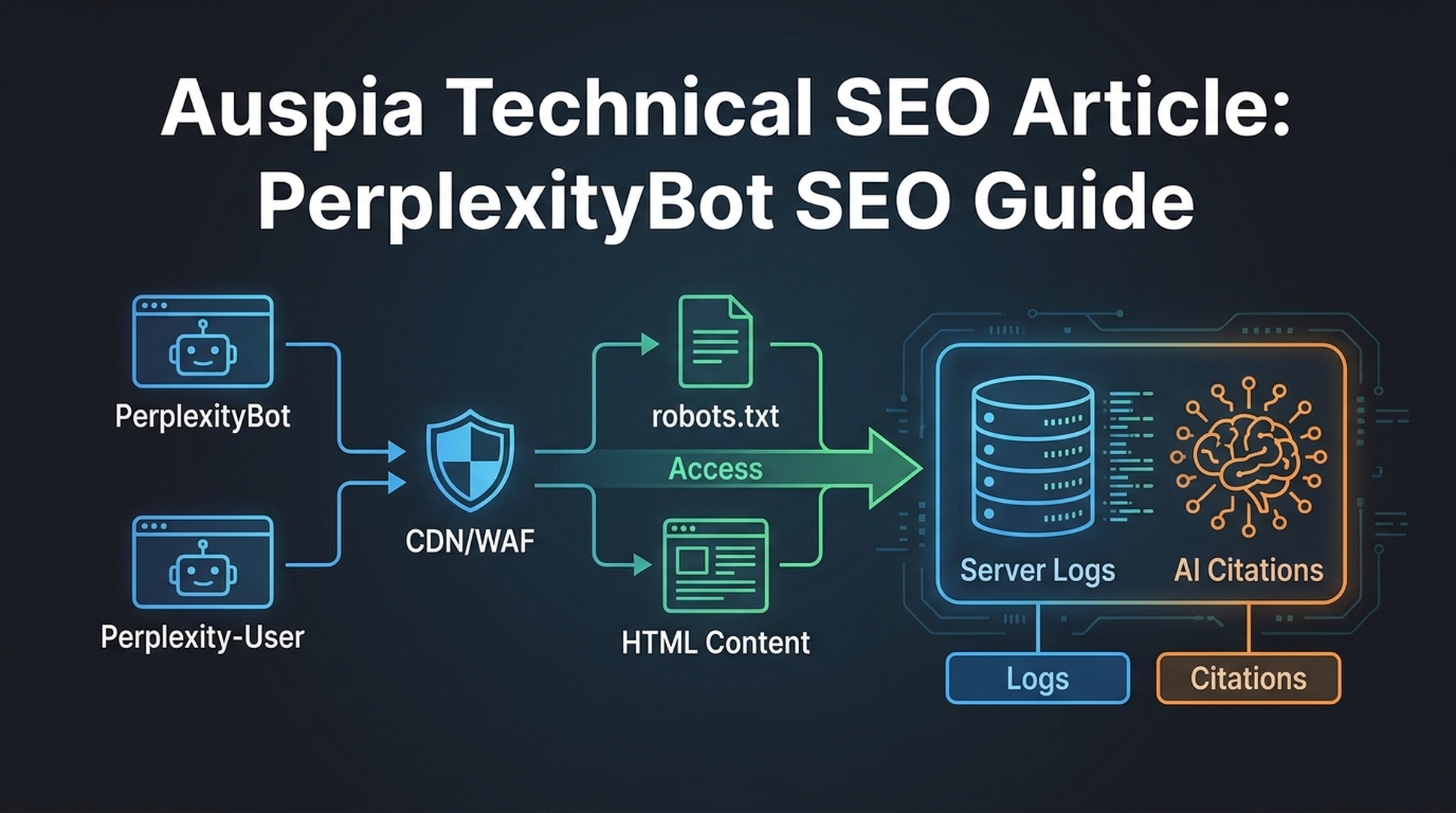
The short answer
GEO is not working just because your brand name appears in an AI answer once. In 2026, a useful GEO report should answer three harder questions: did the AI system understand what your company does, did it cite or recommend you in the right buying situations, and did that visibility turn into qualified traffic or pipeline?
That means the old comfort metrics are not enough. Screenshots, total indexed pages, raw brand mentions, and one-off "we appeared in ChatGPT" wins can be useful clues, but they are not proof. Real GEO measurement needs a scorecard that connects AI visibility, citation quality, answer accuracy, referral behavior, conversions, and commercial return.
If you only remember one thing from this guide, make it this: measure GEO as a revenue path, not a popularity contest.

The 10-metric GEO dashboard should separate surface visibility from citation quality, user behavior, conversion, and ROI.
Why vanity metrics are so tempting
Vanity metrics are popular because they are easy to show.
A vendor can send you a screenshot. A dashboard can count mentions. A crawler can say thousands of pages are "AI-ready." A report can list every prompt where your brand appeared somewhere in the answer.
None of that is useless. The problem is that these signals are often too shallow to support a business decision.
Here is the trap:
| Vanity metric | Why it looks good | What it fails to prove |
|---|---|---|
| Brand appeared once in an AI answer | Easy screenshot for a report | Whether the appearance repeats across prompts and platforms |
| Total mentions increased | Looks like visibility growth | Whether the mention was positive, accurate, or relevant |
| More pages are indexed | Feels like coverage | Whether AI systems can extract useful facts from those pages |
| Higher impression counts | Similar to SEO reporting | Whether users clicked, trusted, or converted |
| A single high-ranking prompt | Strong anecdote | Whether it maps to real buyer demand |
A serious GEO program should still track visibility. It just cannot stop there.
The 2026 GEO measurement stack
Think of GEO performance in four layers.
- AI answer visibility: Are you present in the answer set when buyers ask relevant questions?
- AI understanding quality: Does the model describe your brand, product, category, and use cases correctly?
- User behavior: Do users who arrive from AI-assisted journeys behave like qualified visitors?
- Business impact: Does the work reduce acquisition friction or create measurable pipeline?
Most weak GEO reports over-focus on the first layer. Better reports connect all four.
The 10 GEO metrics that actually matter
1. AI visibility share
This is the percentage of tracked prompts where your brand appears in the answer, recommendation list, citation set, or comparison summary.
Do not measure it with random prompts. Build a prompt library around real customer intent:
- Problem prompts: "How do I improve AI search visibility for a B2B SaaS site?"
- Category prompts: "Best tools for GEO audit and AI citation tracking"
- Comparison prompts: "Auspia vs other GEO checker tools"
- Use-case prompts: "How to measure GEO performance for enterprise SEO teams"
- Local or vertical prompts, if relevant to your market
A practical formula:
AI visibility share = prompts where brand appears / total tracked prompts
Segment it by platform: ChatGPT, Perplexity, Gemini, Google AI Overviews, and any vertical AI search product that matters to your audience.
2. Recommendation rate
A brand mention is not the same as a recommendation.
If the answer says, "Several tools exist, including X," that is weaker than, "For this use case, X is a strong option because..." Recommendation rate measures how often the AI system positions your brand as a fit for the user's task.
Track three levels:
| Level | Meaning | Example |
|---|---|---|
| Mentioned | Brand appears somewhere | "Other tools include Auspia" |
| Shortlisted | Brand appears in a list of options | "Consider Auspia, Tool B, and Tool C" |
| Recommended | Brand is matched to a need | "Use Auspia when you need a quick GEO score and citation-readiness check" |
This matters because recommendation language is closer to demand than raw awareness.
3. Citation quality
GEO teams often celebrate citations without asking whether the cited source is any good.
Measure citation quality by looking at the source that the AI system uses to support its answer. Strong citations usually come from pages that are specific, updated, structured, and aligned with the user's question.
Score each citation from 1 to 5:
| Score | Citation quality |
|---|---|
| 1 | Irrelevant or outdated source |
| 2 | Brand page is cited, but the answer pulls weak or generic facts |
| 3 | Relevant page cited with mostly accurate facts |
| 4 | Specific page cited for the right use case, feature, or evidence |
| 5 | High-intent page cited with clear facts, comparison points, and conversion path |
The goal is not just "more citations." The goal is citations that help the AI answer the right question.
4. Answer accuracy rate
If AI systems mention you but describe you badly, GEO has not succeeded.
Track how often answers correctly state:
- What your product or service does
- Who it is for
- Which use cases it supports
- Your category and differentiators
- Pricing, plans, availability, or limitations when those facts are public
- The correct URL or next step
A simple formula:
Answer accuracy rate = accurate brand answers / total brand answers reviewed
This metric is especially important for companies with complex products, multi-product websites, or fast-changing positioning.
5. Entity consistency
AI systems need stable facts. If your homepage says one thing, your docs say another, your LinkedIn profile uses a third category, and third-party listings are outdated, the model has to guess.
Entity consistency measures whether your brand facts are aligned across first-party and trusted third-party sources.
Audit these fields:
- Brand name and spelling
- Product category
- Short description
- Primary audience
- Core features
- Use cases
- Founding or company facts, if relevant
- Social profiles and organization schema
This is where traditional SEO, brand governance, and GEO meet. Messy entity data weakens AI understanding even when the content itself is good.
6. AI referral traffic quality
Referral traffic from AI surfaces is still imperfect to attribute. Some visits arrive as direct traffic. Some platforms hide referrers. Some users ask AI first, then search your brand later.
So do not rely on source/medium alone. Watch behavior patterns.
Useful indicators include:
- Sessions from known AI referrers
- Growth in branded search after AI visibility gains
- Landing pages that receive traffic after appearing in answer systems
- Time on page for AI-assisted visitors
- Pages per session
- Scroll depth
- Return visits
The key question is simple: when AI-assisted visitors land on your site, do they behave like people with intent?
7. Engagement depth on cited pages
If your GEO work is effective, the pages being cited or surfaced by AI should not behave like random blog traffic.
Measure:
- Average engagement time
- Scroll depth
- Clicks on comparison tables, calculators, demos, pricing, or docs
- Internal link movement from educational pages to product pages
- Download or signup events
For example, a GEO measurement article should not only attract readers. It should move some of them toward a GEO audit, a tool check, or a demo request.
8. Conversion path compression
One underrated GEO benefit is that AI can shorten the research journey.
If the answer already explains what your product does, who it is for, and why it fits the user's need, the user may need fewer steps on your site before taking action.
Track:
- Number of sessions before conversion
- Number of pages viewed before conversion
- Time from first visit to lead
- Number of assisted touchpoints before demo or signup
- Completion rate on mobile journeys
A good GEO program should make the buyer's next step easier, not just send more traffic.
9. Pipeline and revenue contribution
At some point, GEO has to meet the CRM.
You do not need perfect attribution to start. You need a defensible model.
Create a simple tracking view for:
- Leads who first arrived from known AI referrers
- Leads who viewed GEO-cited pages before converting
- Leads who mentioned AI tools, ChatGPT, Perplexity, Gemini, or AI search in forms or sales calls
- Branded search growth that follows AI visibility gains
- Opportunities influenced by GEO content assets
Then report both direct and assisted impact. Direct attribution will undercount GEO. Assisted attribution will be messier, but it is closer to how buyers actually behave.
10. Cost per qualified AI-assisted lead
This is the metric that keeps GEO honest.
A GEO program may increase mentions, citations, and traffic, but if the cost per qualified lead is worse than your other channels, you need to adjust the strategy.
Use this formula:
Cost per qualified AI-assisted lead = GEO program cost / qualified leads influenced by GEO
Program cost should include content work, technical fixes, tools, strategy time, and external services. Qualified leads should be defined before the campaign starts.
A practical GEO scorecard template
Use this simple scorecard once per month. The exact numbers matter less than the trend and the action that follows.
| Metric | Target | Current | Action if weak |
|---|---|---|---|
| AI visibility share | 30-60% of priority prompts | Track by platform | Improve prompt-mapped pages |
| Recommendation rate | Rising month over month | Separate mentions from recommendations | Add clearer use-case pages |
| Citation quality | Average 4/5 on key prompts | Review cited URLs | Build better evidence pages |
| Answer accuracy | 90%+ on brand facts | Sample answers weekly | Fix entity facts and outdated pages |
| Entity consistency | No major conflicts | Audit first and third-party sources | Standardize descriptions |
| AI referral quality | Better than generic blog traffic | Compare engagement | Improve landing page match |
| Cited-page engagement | Rising scroll and click depth | Track cited URLs | Add summaries, tables, CTAs |
| Path compression | Fewer steps to lead | Compare cohorts | Make next action obvious |
| Pipeline influence | Visible assisted opportunities | CRM + analytics view | Add campaign fields |
| Cost per qualified lead | Competitive with SEO or paid benchmarks | Monthly finance view | Reprioritize prompts and pages |
How to run the measurement loop
Do not wait six months to ask whether GEO worked. Run a monthly loop.
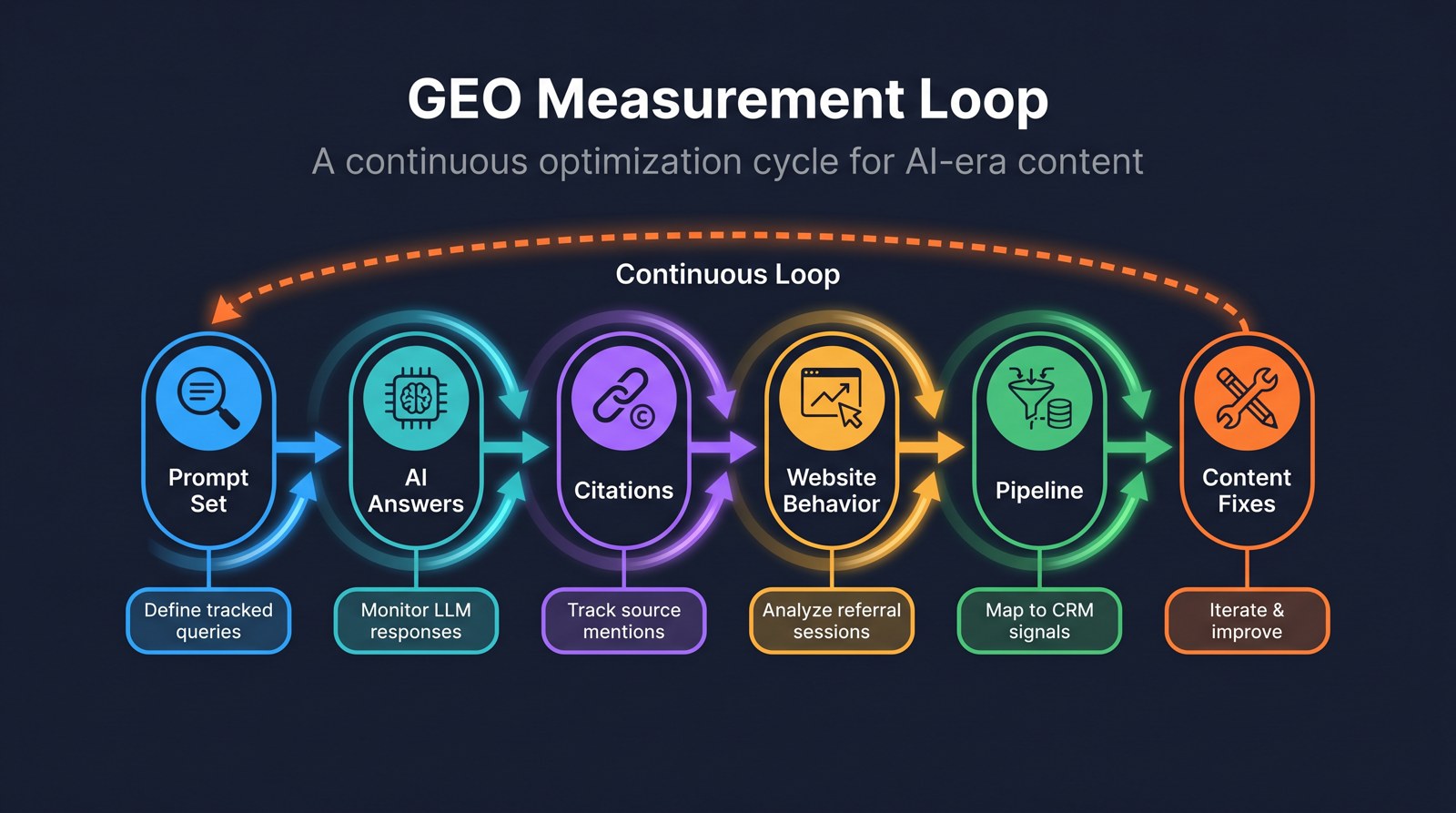
The practical GEO loop starts with tracked prompts and ends with content, entity, and conversion fixes.
Step 1: Build a prompt library
Start with 50 to 200 prompts. Group them by intent, platform, region, product, and funnel stage. Do not only test prompts where you already expect to win.
Step 2: Capture answer outputs
For each prompt, record whether your brand appears, how it appears, which sources are cited, and whether the answer is accurate.
Step 3: Map answers to pages
If an AI answer cites the wrong page, that is a content architecture problem. If it cites the right page but pulls weak facts, that is a content clarity problem. If it does not cite you at all, that may be an authority, retrieval, or coverage problem.
Step 4: Compare website behavior
Look at the pages that AI systems surface. Are users staying? Are they moving to a tool, demo, pricing page, or product page? If not, the page may be good enough for citation but not good enough for conversion.
Step 5: Connect to pipeline
Add CRM notes, form fields, and analytics segments that can capture AI-assisted discovery. Keep the model honest, but accept that GEO attribution will never be as clean as a last-click paid search report.
Step 6: Fix the asset, not just the prompt
When a metric is weak, do not simply add more content. Fix the asset that the AI system should use: the comparison page, product page, docs page, FAQ block, category definition, schema, author page, or third-party profile.
What a good GEO report should include
A useful GEO report should be boring in the best way. It should show evidence, trends, and decisions.
Include:
- The prompt set tested and why it matters
- Platform-by-platform visibility
- Mention vs recommendation rate
- Top cited URLs
- Citation quality score
- Common answer errors
- Entity consistency issues
- AI-assisted traffic and engagement trends
- Conversion and pipeline signals
- Next-month fixes
If a report is mostly screenshots, treat it as a warning sign.
Common measurement mistakes
Mistake 1: Measuring only the homepage
AI systems often cite docs, blog posts, category pages, comparison pages, help pages, and product pages. If you only watch the homepage, you miss the real retrieval surface.
Mistake 2: Treating every prompt as equal
A high-funnel education prompt is not worth the same as a comparison prompt from a buyer who is ready to choose a vendor. Weight prompts by commercial intent.
Mistake 3: Ignoring negative or inaccurate mentions
Visibility can hurt if the answer is wrong. A model that recommends you for the wrong use case may create bad-fit leads and support friction.
Mistake 4: Reporting traffic without quality
A spike in traffic means little if visitors bounce, do not read, do not click, and never return.
Mistake 5: Expecting perfect attribution
GEO is partly a discovery channel, partly a trust channel, and partly an assisted conversion channel. Measure it with a blended model.
Auspia's take
GEO measurement should feel closer to an operating dashboard than a marketing trophy wall.
The best teams in 2026 will not ask, "Did we show up in AI?" They will ask:
- Did we show up for the prompts that matter?
- Did the AI system understand us correctly?
- Did it cite the right assets?
- Did users who came through AI-assisted journeys behave like qualified buyers?
- Did the work improve pipeline efficiency?
That is a much harder standard. It is also the only standard worth paying for.
If you want a quick starting point, run your site through Auspia's GEO Score Checker . It will not replace a full measurement program, but it can help you spot weak areas in AI visibility, citation readiness, and GEO fundamentals before you build a deeper dashboard.
FAQ
What is the most important GEO metric?
For early programs, start with AI visibility share and answer accuracy. Once visibility exists, shift attention to citation quality, engagement depth, and qualified lead contribution.
How often should GEO performance be measured?
Monthly is enough for executive reporting. Weekly checks are useful for priority prompts, newly published pages, and pages that recently changed positioning or product facts.
Can GEO ROI be measured perfectly?
No. AI-assisted discovery often creates indirect paths: a user asks an AI tool, searches the brand later, visits directly, then converts after another touchpoint. Use direct attribution where possible, but also track assisted signals.
Are brand mentions still useful?
Yes, but only as a starting signal. A mention becomes meaningful when it is relevant, accurate, repeated across important prompts, supported by good citations, and connected to user behavior.
What should I do if AI answers describe my company incorrectly?
Fix the source facts first. Align your homepage, product pages, about page, schema, docs, comparison pages, and trusted third-party profiles. Then retest the prompts to see whether the answer changes.
Author: Ethan Marlowe, GEO Measurement Lead Across 500+ Prompts at Auspia. Ethan writes about prompt tracking, citation reporting, visibility dashboards, and AI answer quality checks for growth teams.