The short answer
GEO is usually sold as a visibility tactic: get mentioned by ChatGPT, Gemini, Perplexity, or Google AI Overviews, then wait for high-intent visitors to arrive.
That is the easiest value to understand, but it is not the whole prize. The larger value comes in three layers:
- Visibility: your brand enters the answer when buyers ask for options.
- Trust: AI systems repeat a fact pattern that makes your claims easier to believe.
- Standards: the market starts comparing vendors through the criteria you have taught the web to use.
The third layer is where GEO becomes strategic. You are no longer only trying to appear in an AI answer. You are trying to influence the checklist the answer uses.
This matters because AI search is no longer a side channel. Google has formal documentation for how site owners should think about AI features in Search, and Google introduced AI Mode as a more conversational way to ask complex questions. At the same time, click behavior is changing. Pew Research Center found in 2025 that users clicked traditional result links less often when Google showed an AI summary. More recent academic work has also found that AI Overviews can cite pages that do not match the classic first-page ranking set.
So if your board is still asking, "How many leads did GEO generate this month?", the question is too small. GEO affects discovery, sales confidence, and category framing. Those three effects do not show up in the same dashboard column.
Layer 1: visibility is the entry ticket
The first layer is obvious: buyers are asking AI systems what to buy, which vendors to compare, which tools fit a use case, and what risks to check before a purchase.
For a B2B team, that means an AI answer can become the new top-of-funnel surface. A buyer may never type "best workflow automation platform" into a traditional search box. They may ask:
- "Which workflow automation tools are best for a 40-person operations team?"
- "Compare Zapier, Make, and Workato for a finance approval workflow."
- "What should I check before buying an AI meeting assistant for a regulated team?"
If your brand, product page, comparison article, customer story, or third-party proof is not visible to the systems answering those questions, you are absent from a growing part of the research journey.
This layer is worth fighting for. But it is also the easiest layer for competitors to copy.
A competitor can publish comparison pages. They can improve schema. They can get listed in directories. They can answer the same prompts and try to appear beside you. Visibility is necessary, but it is not a moat by itself.
The better way to treat layer one is as an admission ticket. You need it to be in the room. You do not win the market just by entering the room.
Layer 2: trust is built by the fact chain
The second layer is where many teams undercount GEO.
The buyer does not only use AI to discover a vendor. The buyer also uses AI to check whether the vendor is believable.
That happens in two common moments.
First, a sales call. A seller explains why the product is a fit. The buyer is interested, but guarded. Then someone says, "Let's ask ChatGPT or Gemini how this compares." If the AI answer repeats the same positioning, use cases, limitations, and evidence the seller just explained, the seller is no longer asking the buyer to accept a claim on faith. A third-party-feeling system is confirming the logic.
Second, pre-call validation. A buyer already heard about your product from a friend, an event, an ad, or a community post. Before booking a demo, they ask an AI assistant, "Is this company credible? Who is it best for? What are the risks?"
If the answer is thin, vague, or inconsistent, the buyer slows down. If the answer contains specific use cases, named integrations, customer segments, known tradeoffs, and external proof, the first sales conversation starts several steps ahead.
The key is not praise. Praise is cheap. The key is a fact chain.
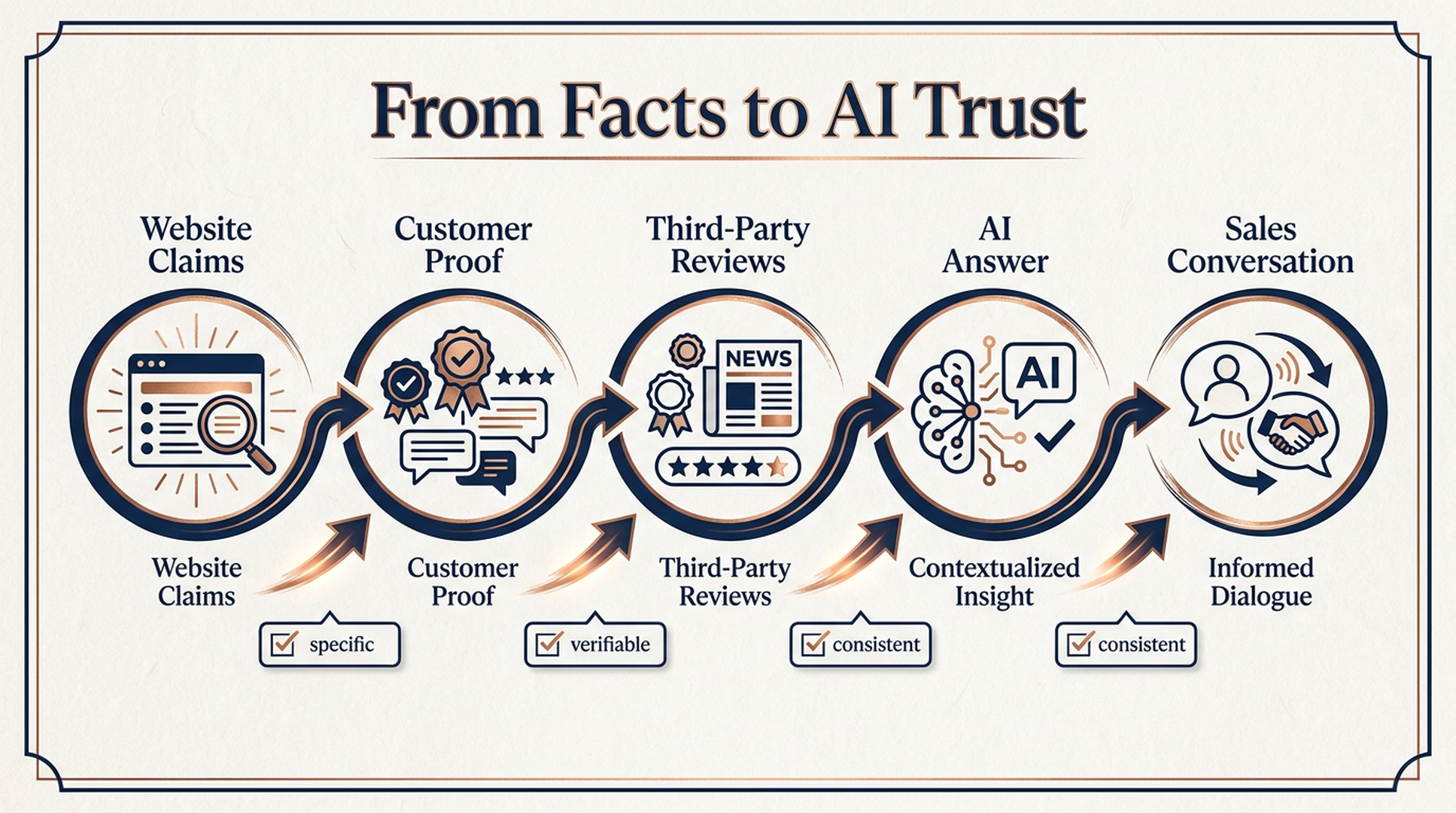
A fact chain is the public trail an AI system can use to evaluate you:
| Weak signal | Stronger signal |
|---|---|
| "We are the best platform for mid-market teams." | A product page naming the exact team size, workflow, integrations, and limits. |
| A generic testimonial. | A customer story with context, problem, implementation path, and measurable outcome. |
| A one-line comparison claim. | A comparison page that states when you are a fit and when a competitor may be better. |
| Isolated brand mentions. | Repeated third-party references that describe the same positioning in similar language. |
| A polished landing page only. | Landing pages, docs, reviews, case studies, community discussion, and analyst-style content that agree with each other. |
This is why GEO work often feels slower than paid acquisition. You are not just creating pages. You are creating public evidence that survives a skeptical query.
A practical test: ask an AI assistant to make a short list of vendors in your category, then ask it to explain why each one should or should not be shortlisted. Do not only look at whether your name appears. Look at the reason. If the reason is vague, the model has not found your fact chain yet.
Layer 3: standards are the real moat
The third layer is the least discussed and the most valuable.
Before an AI assistant recommends a vendor, it needs an evaluation frame. It has to decide what "good" means for the category.
That frame is not magic. It comes from the material the system has seen, retrieved, summarized, and learned to trust. If a certain way of judging the category appears across enough credible sources, the AI answer may start using that frame to organize its recommendations.
This is where GEO moves from "mention my brand" to "shape the question."
Take three software categories:
- For a CRM, should buyers prioritize feature depth, sales process fit, data hygiene, or ease of adoption?
- For an AI writing platform, should buyers prioritize output quality, governance, workflow integration, brand voice control, or cost per article?
- For an observability platform, should buyers prioritize logs, traces, incident response time, developer experience, or cloud spend control?
The vendor that repeatedly publishes the clearest evaluation logic has a chance to influence how AI systems explain the category.
That does not mean inventing self-serving slogans. Models are not loyal to slogans. It means teaching a durable standard with enough specificity that it can be used for comparison.
A weak standard sounds like this: "The best CRM is simple and powerful."
A useful standard sounds like this: "For a 30-person sales team, CRM fit should be judged by stage coverage, lead handoff speed, rep data-entry burden, quote-to-close visibility, integration with email and billing, and manager visibility into stalled deals."
The second version gives an AI system something to work with. It can compare vendors against it. It can explain tradeoffs. It can surface risks.
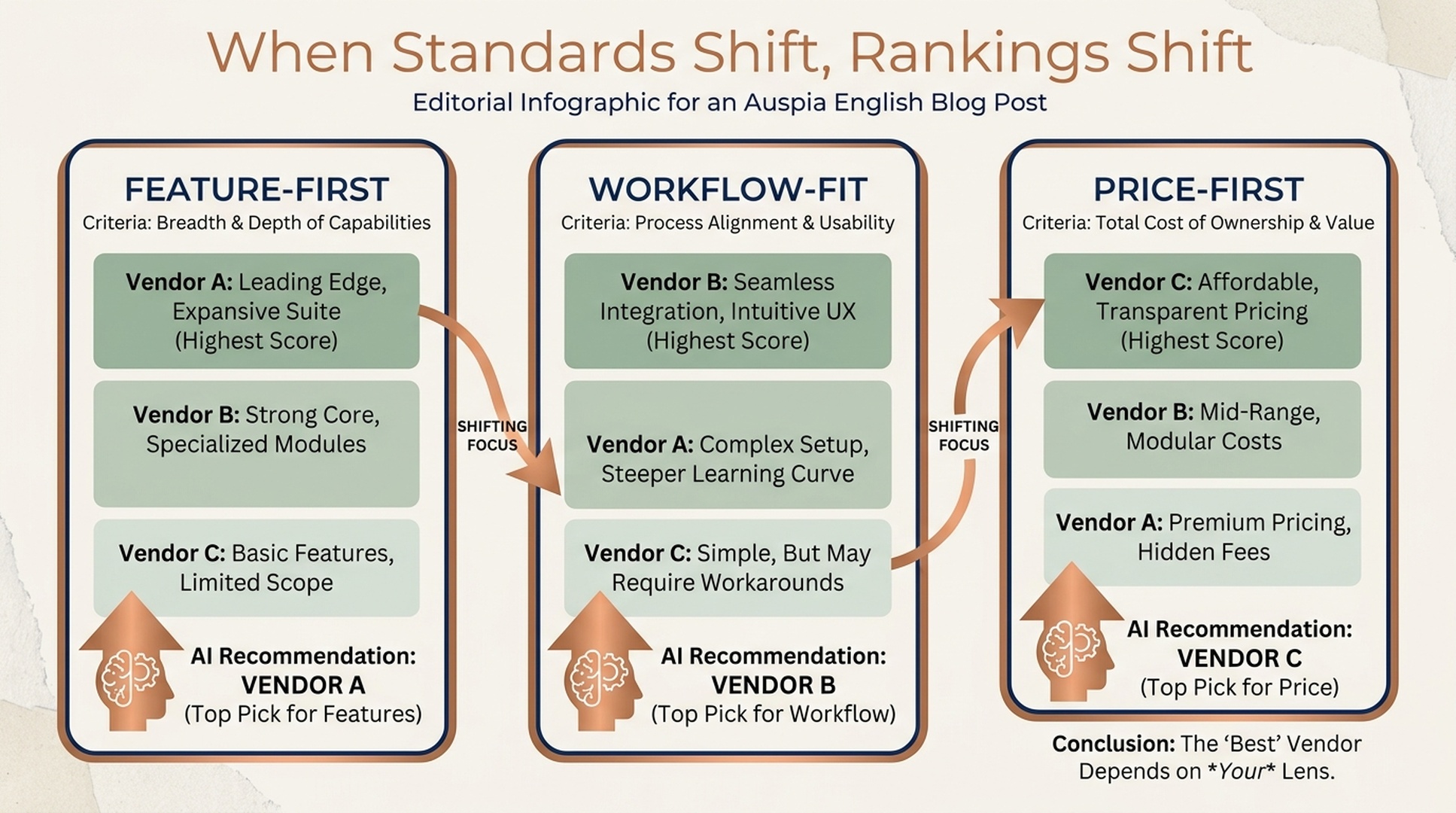
Once your standard becomes the natural checklist, competitors face an uncomfortable choice.
If they ignore the standard, they look incomplete in AI-assisted comparisons. If they respond to it, they help spread the frame. They may think they are defending themselves, but they are also teaching the market to ask your question.
That is the real GEO moat: not a single citation, but a category lens that keeps reappearing.
The three layers work together
It is tempting to separate visibility, trust, and standards into three projects. In practice, they compound.
| GEO layer | What the buyer experiences | What the business earns | What to build |
|---|---|---|---|
| Visibility | "I found this vendor in the answer." | New high-intent discovery | Prompt-aligned pages, comparison pages, answer-ready content, crawlable docs. |
| Trust | "The answer confirms what I heard elsewhere." | Shorter sales cycles and lower persuasion cost | Case studies, reviews, third-party mentions, limitations, transparent positioning. |
| Standards | "This is how I should judge the category." | A durable advantage in how options are compared | Evaluation frameworks, buyer guides, benchmark criteria, category education. |
The first layer gets you named. The second layer makes the name believable. The third layer changes the scoring system.
Most teams stop after the first layer because it is easier to measure. They track AI referrals, branded mentions, citation count, and share of answer. Those metrics are useful, but they miss the harder question: when AI mentions you, what does it believe about you?
Auspia's view: the best GEO programs should be measured at four levels:
- Presence: do AI systems include you in relevant answers?
- Accuracy: do they describe you correctly?
- Evidence: do they cite or retrieve proof that supports the description?
- Framing: do they use evaluation criteria that favor your strongest real advantages?
Presence without accuracy is noise. Accuracy without evidence is fragile. Evidence without framing is useful, but still leaves the buyer using someone else's checklist.
How to build a GEO value stack
Start with one category and one buyer journey. Do not try to boil the entire web.
1. Map the commercial prompts
Write the prompts a real buyer would ask before buying. Include discovery, comparison, objection, risk, and final decision prompts.
Examples:
- "Best tools for [use case] in a [company size] team."
- "Is [brand] credible for [industry]?"
- "[brand] vs [competitor] for [workflow]."
- "What are the risks of choosing [category] software?"
- "What should I ask on a demo before buying [category]?"
Run these prompts across the AI surfaces that matter to your market. For most global B2B teams, that means at least ChatGPT, Gemini, Perplexity, and Google AI features. If your buyers use industry-specific communities or regional assistants, include those too.
Use a tool like Auspia's AI Search Visibility Checker to turn the exercise into a repeatable audit instead of a one-off screenshot hunt.
2. Diagnose the missing layer
For each prompt, label the failure:
| If the AI answer... | Your problem is probably... |
|---|---|
| Does not mention you | Visibility gap |
| Mentions you but gets facts wrong | Accuracy gap |
| Mentions you but gives weak reasons | Evidence gap |
| Compares vendors on criteria that hide your strength | Standards gap |
| Mentions only your competitors' language | Category-framing gap |
This diagnosis prevents a common mistake: publishing more articles when the real problem is a missing proof asset or a weak evaluation framework.
3. Build proof before persuasion
A lot of GEO content fails because it tries to persuade before it proves.
Build assets in this order:
- Product truth: what the product does, who it is for, who it is not for.
- Use-case truth: workflows, industries, team sizes, constraints, integrations.
- Proof truth: case studies, customer quotes, implementation details, third-party reviews.
- Comparison truth: where you win, where you lose, and how buyers should decide.
- Standard truth: the evaluation framework you want the category to use.
The phrase "who it is not for" is important. AI systems handle bounded claims better than inflated claims. A product that admits its limits is easier to place accurately.
4. Publish the standard in reusable formats
If you want AI systems to use your criteria, do not bury them in a single blog post.
Turn the standard into multiple assets:
- a buyer guide;
- a comparison checklist;
- a scoring rubric;
- a glossary page;
- a customer story that applies the rubric;
- a benchmark or teardown;
- a third-party contributed article or podcast discussion;
- a sales enablement page that mirrors the public language.
Keep the language consistent. Not robotic, just consistent enough that the same idea can be recognized across sources.
5. Monitor the answer, not only the click
Traditional SEO taught teams to care about rankings and sessions. GEO adds a new monitoring layer: what the answer says.
Track:
- which prompts trigger your brand;
- which prompts trigger competitors;
- which sources are cited or paraphrased;
- which facts are wrong;
- which criteria the answer uses;
- whether your preferred criteria appear unprompted;
- whether sales teams hear buyers repeat AI-generated language.
That last one is underrated. If prospects begin saying, "We are evaluating vendors based on workflow fit," and that is the standard you have been publishing for six months, your GEO program is working even before attribution catches up.
Common mistakes
The first mistake is treating GEO as reputation management. The goal is not to make AI say nice things. The goal is to make accurate, verifiable, commercially useful answers more likely.
The second mistake is chasing citations without checking the reasoning. A citation can mention you while the answer still frames the category in a way that favors someone else.
The third mistake is publishing generic educational content. "What is CRM?" may be useful, but it will not define your category unless it introduces a sharper way to choose.
The fourth mistake is hiding proof inside gated PDFs. If a system cannot crawl, retrieve, or summarize the evidence, the evidence will not help much in AI answers.
The fifth mistake is changing language every quarter. Positioning experiments are normal, but AI visibility rewards stable public facts. If your site, docs, case studies, and sales pages all describe the product differently, the model has to guess.
Auspia takeaway
GEO is not one channel. It is a value stack.
Visibility brings buyers into the conversation. Trust reduces the work required to convert them. Standards shape the way the whole category is compared.
The brands that win will not be the ones that ask, "How do we get AI to mention us once?" They will be the ones that ask, "What should AI believe about this market, and what public evidence would make that belief reasonable?"
That is a slower question. It is also the question with the larger upside.
If you want a practical starting point, run a prompt audit, check how AI systems currently describe your brand, then build the missing layer first. For some teams, that means crawlable product pages. For others, it means customer proof. For the best-positioned teams, it means publishing the standard competitors will have to answer.
FAQ
Is GEO just SEO for AI search?
No. GEO uses some SEO fundamentals, including crawlability, topical clarity, structured content, and authority signals. But it also cares about how AI systems summarize, compare, and reason across sources. A page can rank in Google and still fail to appear in an AI answer, and a cited page may not be the classic top organic result.
What should we measure first?
Start with prompt coverage, answer accuracy, source evidence, and category framing. AI referral traffic is useful, but it is a late and incomplete signal. A buyer may see your brand in an answer, validate you with AI, and then convert through direct, branded search, sales outreach, or a partner link.
How long does GEO take to work?
Simple visibility fixes can show movement quickly, especially for niche prompts. Trust and standards take longer because they depend on repeated, consistent, public evidence. Think in quarters, not days.
Do we need third-party sources?
Yes, if you want durable trust. Your own site matters, but AI systems and buyers are more likely to trust claims that are supported by customer stories, reviews, partner pages, public documentation, community discussion, media mentions, or other independent references.
Can competitors copy our GEO strategy?
They can copy topics and page formats. It is harder to copy a deep fact chain, real customer proof, and a category standard that has appeared consistently across the market. That is why layer two and layer three matter more than one-off visibility wins.
Sources
- Google Search Central, "AI features and your website": https://developers.google.com/search/docs/appearance/ai-features
- Google Blog, "Expanding AI Overviews and introducing AI Mode," March 5, 2025: https://blog.google/products/search/ai-mode-search/
- Pew Research Center, "Do people click on links in Google AI summaries?", July 2025: https://www.pewresearch.org/short-reads/2025/07/22/do-people-click-on-links-in-google-ai-summaries/
- Xu, Iqbal, and Montgomery, "Measuring Google AI Overviews: Activation, Source Quality, Claim Fidelity, and Publisher Impact," arXiv, May 2026: https://arxiv.org/abs/2605.14021