The practical answer
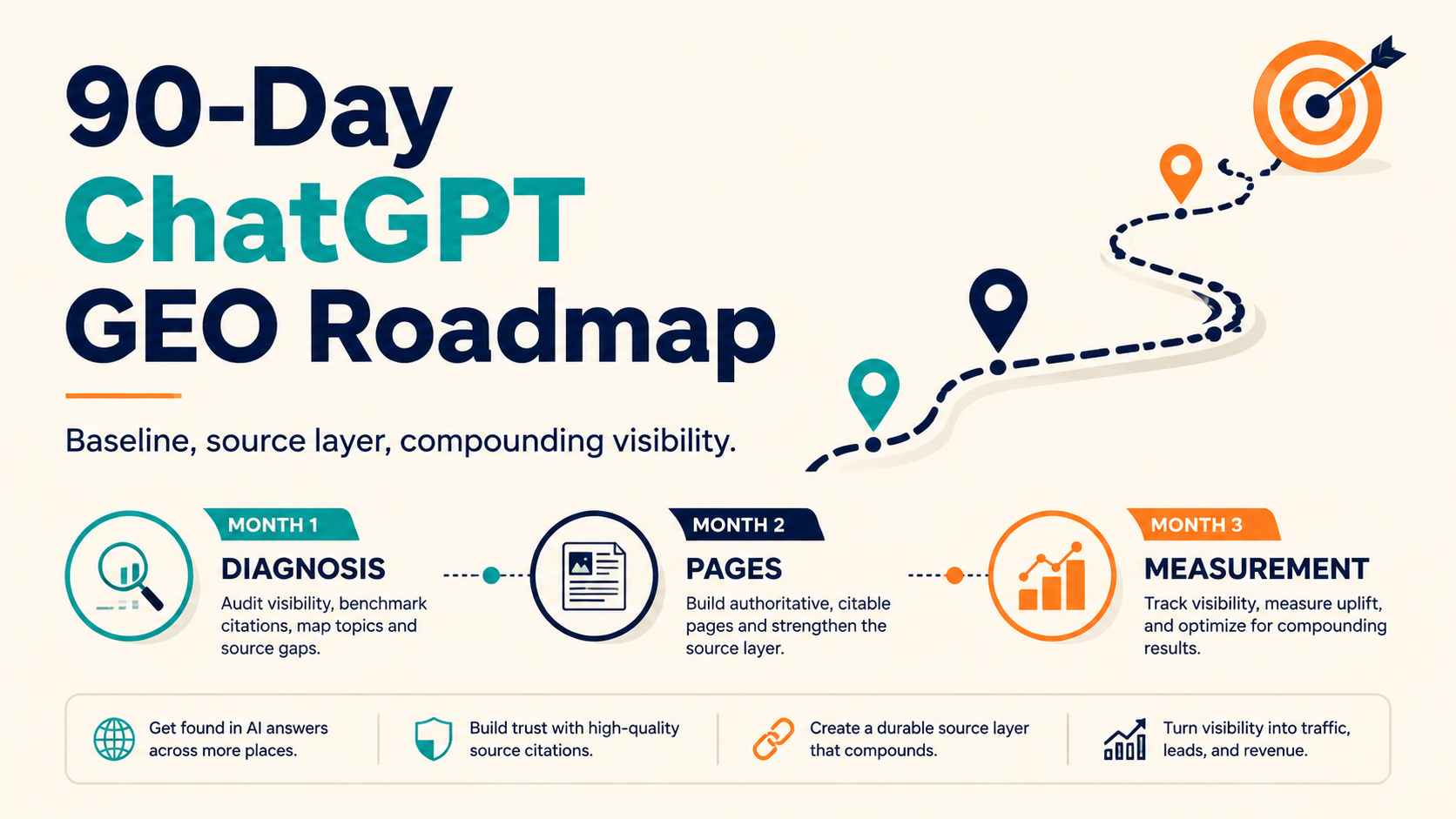
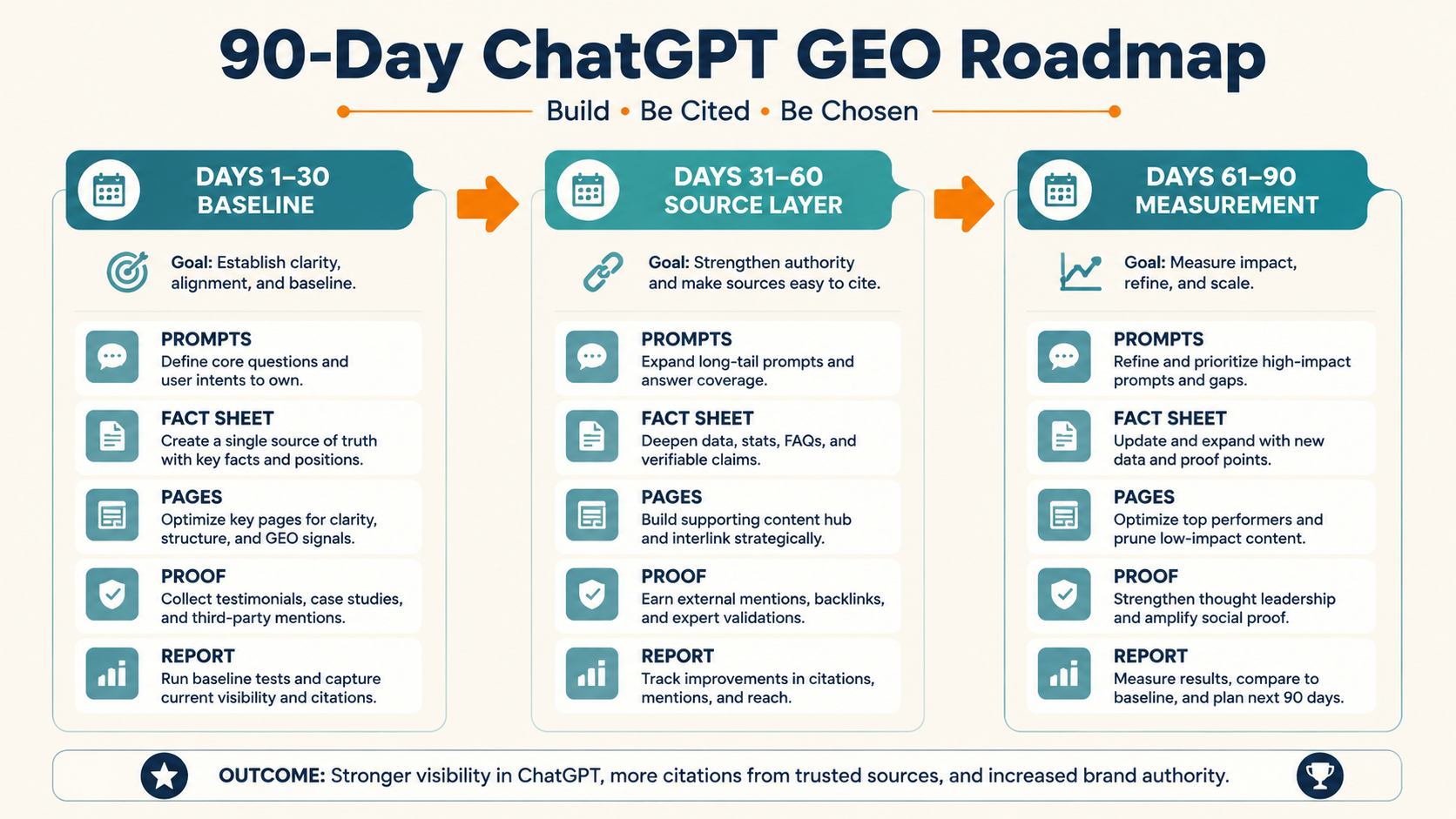
A 90-day ChatGPT GEO roadmap should move from diagnosis to foundation to compounding assets. In the first 30 days, measure where your brand appears and fix entity clarity. In days 31-60, build the pages that help AI systems understand your category, use cases, comparisons, and proof. In days 61-90, expand evidence, improve reporting, and turn the workflow into a repeatable operating system.
The goal is not to publish random AI SEO content. The goal is to make your brand easier to understand, compare, cite, and recommend across ChatGPT-style answers and other AI search surfaces.
A good roadmap gives every month a clear output: a baseline, a stronger source layer, and a measurement loop.
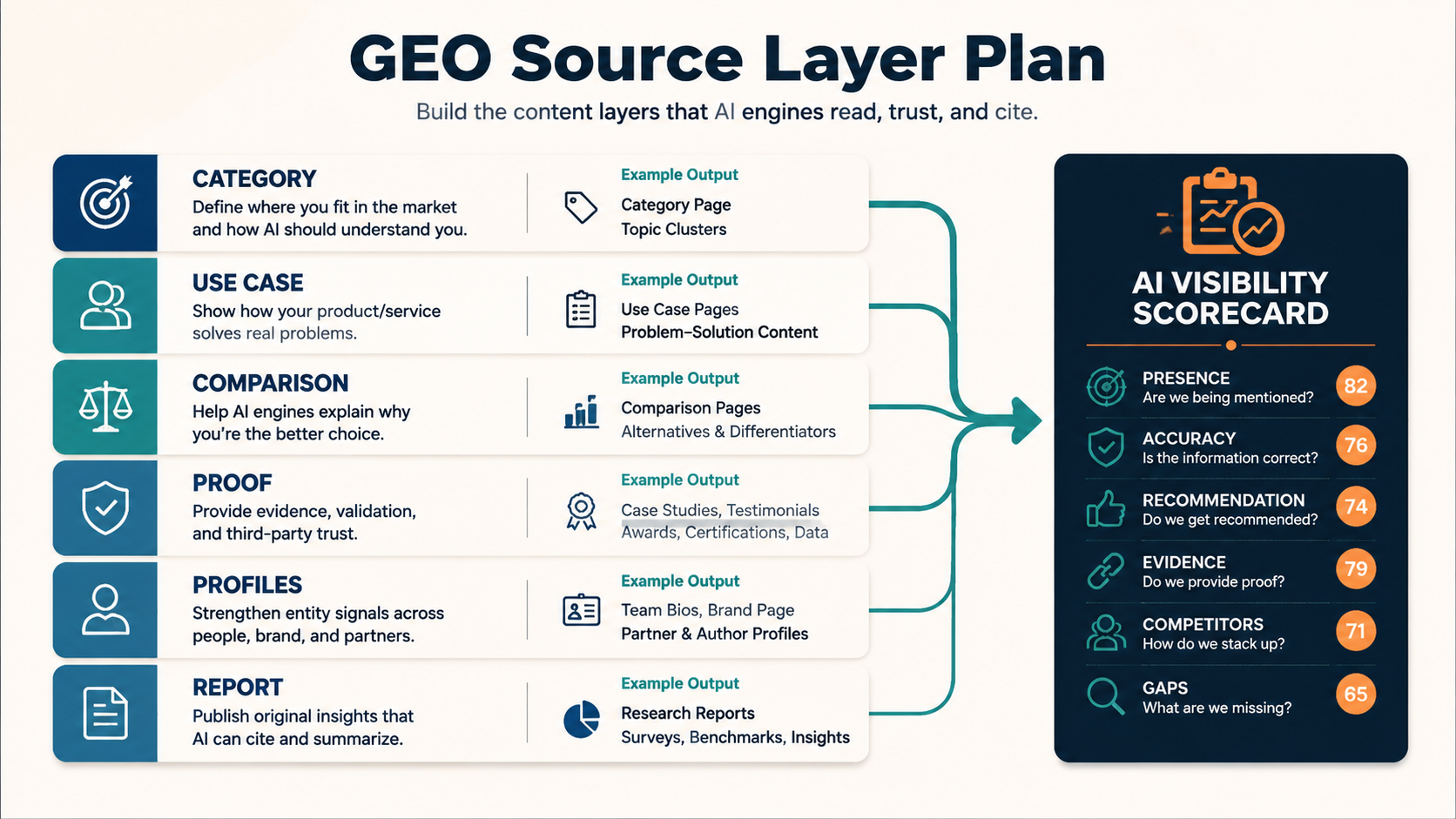
Who this roadmap is for
Use this roadmap if your team has at least one of these problems:
- ChatGPT does not mention your brand in category prompts
- AI answers describe your company incorrectly
- competitors appear in alternatives prompts but you do not
- your website lacks category, use-case, comparison, or proof pages
- leadership wants an AI visibility baseline
- your content team needs a repeatable GEO workflow
- your brand recently repositioned or launched a new product
This plan works best for B2B SaaS, agencies, service businesses, marketplaces, and content-led companies with public pages they can update.
Month 1: baseline and entity cleanup
The first month is about finding the truth. Do not start with a big publishing sprint before you know the visibility gap.
Week 1: build a prompt baseline
Create 25-50 prompts across:
- brand prompts
- category prompts
- problem prompts
- comparison prompts
- alternatives prompts
- evidence prompts
- use-case prompts
Record:
| Metric | What to track |
|---|---|
| Brand presence | whether the brand appears |
| Description accuracy | whether the answer is correct |
| Competitor overlap | which competitors appear |
| Recommendation context | whether the brand is recommended and why |
| Evidence | whether proof, sources, or examples appear |
| Wrong claims | outdated or incorrect descriptions |
This becomes your baseline.
Week 2: create a brand fact sheet
Write one internal source of truth:
- official brand name
- one-sentence description
- category
- audience
- use cases
- products
- competitors
- proof points
- claims to avoid
- preferred language
Every page and profile should align with this sheet.
Week 3: fix owned entity pages
Update high-control pages first:
- homepage
- about page
- product pages
- public profiles
- author or company pages
- footer and schema basics
- key CTAs and descriptions
The goal is consistency. If your own pages use five different categories, AI systems will struggle.
Week 4: diagnose gaps and choose priorities
Turn the baseline into a roadmap.
| Gap | Priority asset |
|---|---|
| absent from category prompts | category page |
| absent from alternatives prompts | alternatives or comparison page |
| vague product descriptions | product page rewrite |
| missing use-case prompts | use-case page |
| low evidence rate | case study or proof page |
| wrong brand descriptions | source cleanup and entity repair |
End month 1 with a written priority list.
Month 2: build the source layer
Month 2 is where the content and page work starts.
Week 5: publish or rebuild the category page
The category page should define the market, explain the problem, name buyer jobs, compare adjacent categories, and show where your product fits.
Week 6: publish a use-case page
Pick the highest-intent use case from your prompt baseline. The page should explain audience, trigger, workflow, product role, proof, fit, and not-fit.
Week 7: publish an alternatives or comparison page
If competitors dominate AI answers, build fair comparison content. Include decision criteria, fit guidance, differentiators, limitations, and evidence.
Week 8: publish proof
Choose one proof asset:
- case study
- review evidence hub
- benchmark
- before/after prompt audit
- workflow example
- public template
Proof is what turns positioning into credibility.
Month 3: measurement, evidence, and compounding
Month 3 turns the work into a system.
Week 9: rerun the prompt baseline
Use the same prompts as month 1. Compare:
- presence rate
- accuracy rate
- recommendation rate
- evidence rate
- competitor overlap
- wrong answer rate
Do not expect every metric to jump. Look for signal: fewer wrong descriptions, better category association, more accurate mentions, and improved prompt coverage.
Week 10: update third-party evidence
Refresh external sources:
- directory profiles
- review pages
- partner pages
- marketplace listings
- podcast bios
- social profiles
- author bios
- community resources
Use the same brand fact sheet language. External consistency matters.
Week 11: create the executive report
Turn prompt data into a concise update:
- what improved
- what is still missing
- which competitors dominate
- what assets were published
- what should happen next
Keep it action-oriented. Leadership does not need raw prompt logs first.
Week 12: build the next sprint plan
Choose the next 3-5 assets based on the data.
Possible next assets:
- additional use-case pages
- competitor-specific pages
- FAQ hub
- technical AI readability improvements
- LLMs.txt update
- robots.txt audit
- citation-ready research page
- deeper case study
The 90-day output checklist
By the end of 90 days, you should have:
| Output | Done? |
|---|---|
| 25-50 prompt baseline | |
| brand fact sheet | |
| owned page entity cleanup | |
| category page | |
| use-case page | |
| alternatives or comparison page | |
| proof asset | |
| third-party profile updates | |
| rerun prompt report | |
| executive share-of-voice summary | |
| next sprint plan |
If you only publish articles but skip measurement, you do not have a GEO program. You have content output.
What to prioritize if you only have one person
If one person owns the work, reduce the plan:
- Week 1: prompt baseline
- Week 2: brand fact sheet and homepage/product copy cleanup
- Week 3-4: one category or use-case page
- Week 5-6: one comparison page
- Week 7-8: one proof asset
- Week 9: update review/directory profiles
- Week 10: rerun prompts
- Week 11-12: report and plan next sprint
Do fewer things, but connect them to the same prompt baseline.
What to avoid
Avoid:
- publishing 20 generic AI SEO posts without prompt data
- changing positioning every month
- measuring only brand-name prompts
- ignoring competitors
- claiming guaranteed ChatGPT recommendations
- building comparison pages with no evidence
- leaving third-party profiles outdated
- reporting screenshots without a scoring model
- treating GEO as a one-time audit
GEO compounds when pages, proof, profiles, and measurement reinforce each other.
A simple 90-day scorecard
Use this monthly.
| Area | Month 1 | Month 2 | Month 3 |
|---|---|---|---|
| Brand accuracy | baseline | improve owned pages | monitor change |
| Category presence | baseline | publish category page | compare movement |
| Competitor overlap | baseline | publish comparison asset | report share of answer |
| Use-case visibility | baseline | publish use-case page | expand next use case |
| Evidence strength | baseline | publish proof asset | update external profiles |
| Reporting | set metrics | track asset work | executive report |
FAQ
What is a ChatGPT GEO roadmap?
A ChatGPT GEO roadmap is a time-bound plan for improving how AI answer systems understand, mention, compare, and recommend a brand. It combines prompt measurement, entity cleanup, page creation, evidence building, and reporting.
What should happen in the first 30 days?
Build a prompt baseline, create a brand fact sheet, fix owned entity pages, and diagnose whether the biggest gap is category, comparison, use case, evidence, or wrong descriptions.
How many pages should we publish in 90 days?
For most teams, three to six strong assets are better than dozens of thin posts. Prioritize category, use-case, comparison, and proof pages tied to your prompt gaps.
How do we know if the roadmap is working?
Rerun the same prompt set and track presence rate, accuracy rate, recommendation rate, evidence rate, competitor overlap, and wrong answer rate.
Can a small team run this roadmap?
Yes. A small team should reduce scope but keep the sequence: baseline, entity cleanup, one source asset, one proof asset, external profile updates, and repeat measurement.
Author: Aaron Wolfe, Organic Growth Systems Designer with 15 Years in SEO/GEO at Auspia. Aaron writes about organic growth systems, SEO/GEO process design, and repeatable AI visibility operations.