Quick answer
GEO works when a brand can pass three tests inside an AI answer system: the model can find the content, trust the evidence, and reuse a clean answer fragment without extra interpretation. The practical work is less mysterious than it sounds. Map real questions, publish crawlable evidence, build third-party authority, and measure whether AI systems mention, cite, or paraphrase you across a fixed prompt set.
The useful shift is this: stop treating GEO as "write articles for AI." Treat it as an operating model for becoming the source an answer engine can safely use.
Auspia's working formula is simple:
| GEO job | What it means in practice | What to measure |
|---|---|---|
| Be findable | Pages, profiles, documents, and citations are crawlable and easy to parse | Indexed URLs, accessible content, prompt retrieval hits |
| Be trusted | Claims have named sources, authors, dates, comparisons, and third-party mentions | Citation quality, source diversity, entity consistency |
| Be reusable | Content contains short answers, tables, checklists, and Q&A blocks | Mentions, citations, copied phrases, answer share |
| Be maintained | Prompts, platforms, and competitor mentions are checked every week | Trend by prompt cluster and platform |
Why GEO deserves a real budget now
The old search path was linear: user searches, user scans links, user clicks. AI search compresses that path. A user can now ask ChatGPT, Google AI Overviews, Perplexity, Copilot, Claude, or another answer engine for a recommendation, comparison, shortlist, risk check, or buying argument. The answer often arrives before the click.
That changes the traffic game. A brand can rank on a classic search results page and still be absent from the AI answer that shapes the buyer's next step.
Gartner predicted in February 2024 that traditional search engine volume would drop 25% by 2026 because of AI chatbots and virtual agents. The exact number is less important than the direction. Google began rolling out AI Overviews publicly in the United States in May 2024. OpenAI announced ChatGPT search in October 2024. Perplexity, Copilot, and other answer engines have made source-backed answers normal for many users.
For growth teams, this creates a strange window. AI answer visibility is already influencing discovery, but most companies still manage content as if the only audience is Googlebot plus a human reader. That gap is where early GEO work can pay off.
The catch: GEO is not a shortcut. You cannot publish a few keyword-stuffed posts and expect models to quote you. Answer systems are looking for retrievable, trustworthy, specific information. If your content is vague, promotional, blocked from crawlers, or unsupported by external evidence, it is easy for an AI system to ignore.
The source article's useful lesson, adapted for global teams
The article that prompted this piece has a strong operating rhythm: it starts with why GEO matters, explains the retrieval logic behind AI answers, then turns that logic into a four-part workflow. That structure is worth keeping.
The global version needs different examples. Instead of focusing on one local AI ecosystem or one domestic media mix, most international brands need to think across:
- ChatGPT and ChatGPT search
- Google AI Overviews
- Perplexity
- Microsoft Copilot and Bing
- Claude, Gemini, and vertical AI tools used in their industry
- Reddit, YouTube, GitHub, review sites, analyst pages, documentation, partner pages, and traditional editorial sources
The principle stays the same. Different AI systems lean on different retrieval sources, indexes, partnerships, and freshness signals. A software company, a healthcare marketplace, and a B2B services firm should not use the same GEO distribution plan.
How AI answer systems decide what to reuse
Most modern AI answer experiences use some version of retrieval-augmented generation, usually called RAG. The exact implementation differs by platform, but the practical workflow looks like this:
- The system interprets the user's question.
- It searches an index, web corpus, knowledge base, or connected source set.
- It scores candidate passages for relevance, reliability, freshness, and usefulness.
- It generates an answer using the strongest passages it can safely use.
For GEO, the implication is blunt: you need to win before the answer is written.
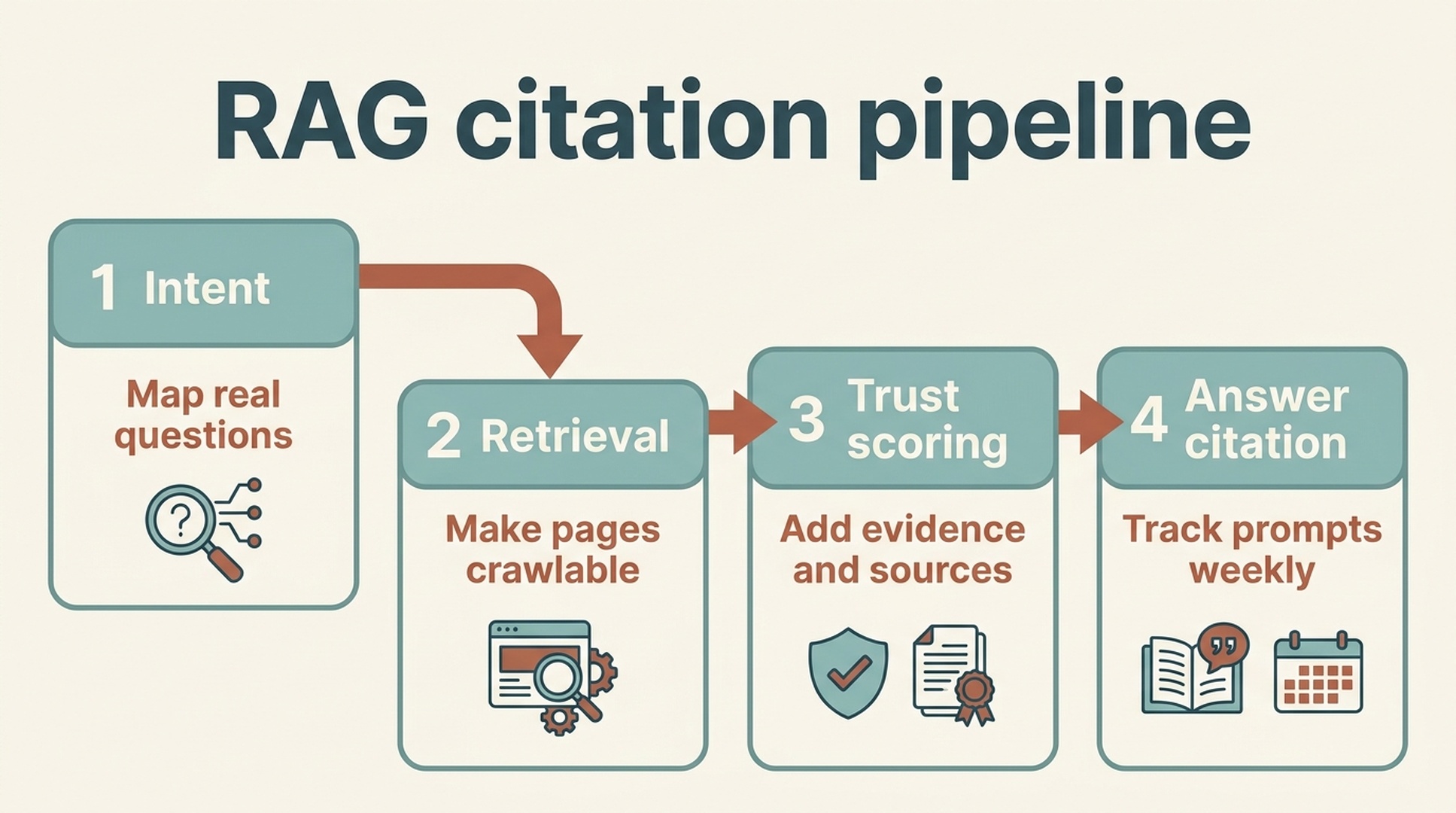
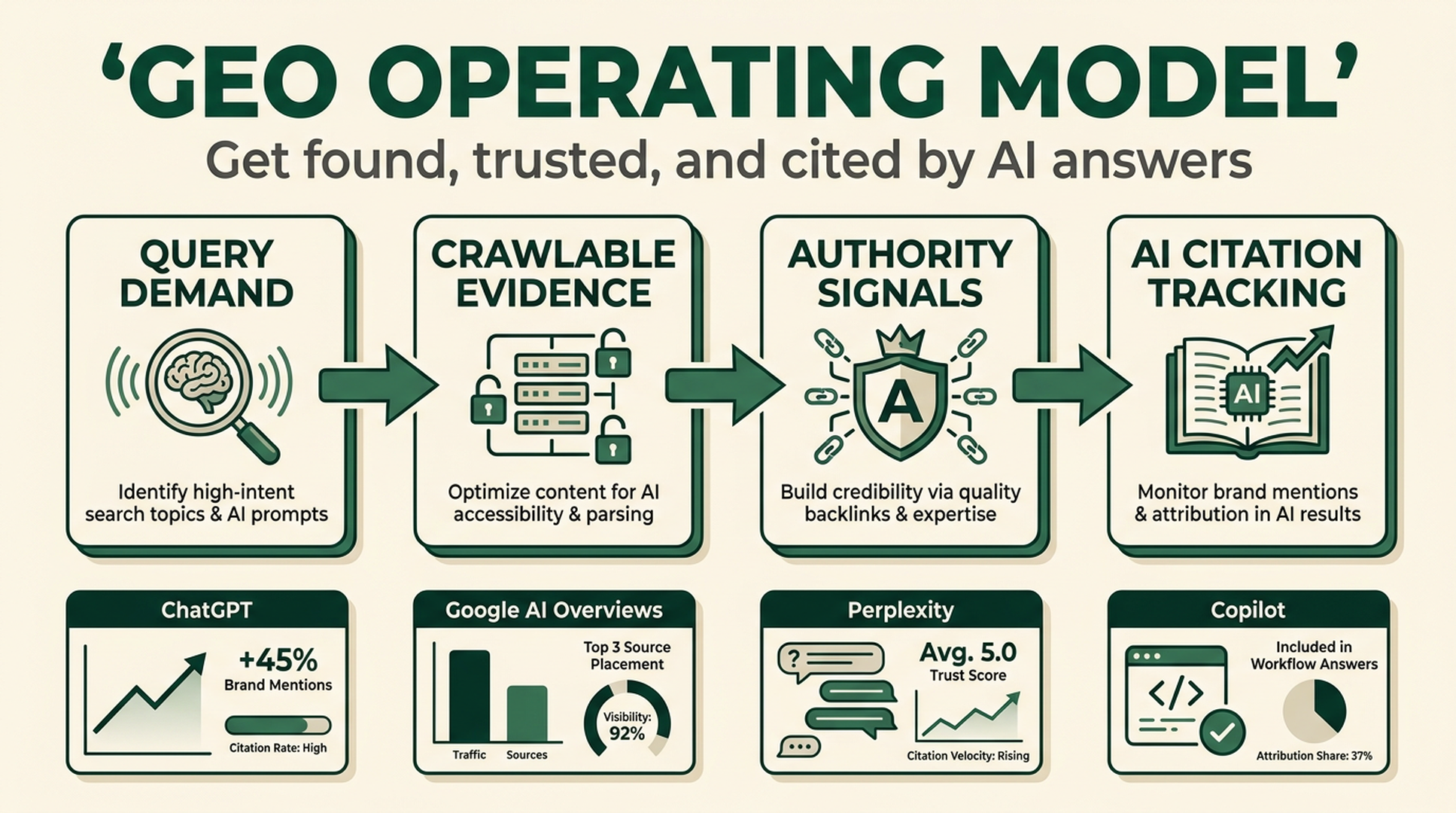
Caption: GEO maps to the retrieval pipeline: real questions, crawlable evidence, trust scoring, and citation tracking.
A lot of teams only optimize the final article. That is too late. The model first needs to retrieve your page or a third-party page that mentions you. Then it needs to prefer that source over alternatives. Only then can your wording, table, quote, or comparison appear in the final answer.
So the work breaks into four jobs: demand, content, authority, and platform fit.
Step 1: map questions, not just keywords
Traditional SEO starts with keywords. GEO starts with questions and decision moments.
A buyer rarely asks an AI system for a naked keyword like "CRM software" or "enterprise SEO platform." They ask messy, high-intent questions:
- "Which CRM is better for a 30-person sales team using HubSpot today?"
- "What are the risks of switching from Salesforce to a cheaper CRM?"
- "Best SEO platform for a SaaS company that needs technical audits and AI search visibility"
- "Compare Perplexity, ChatGPT, and Google AI Overviews for product research"
These prompts contain role, context, constraint, comparison, and desired output. That is the real GEO demand layer.
A practical question map should include:
| Prompt layer | Example | Why it matters |
|---|---|---|
| Audience | "for a seed-stage SaaS team" | Narrows the answer and source set |
| Use case | "for technical SEO audits" | Connects content to product value |
| Constraint | "under $500 per month" | Triggers comparison and shortlist behavior |
| Risk | "what can go wrong" | Pulls in review pages, forums, and expert sources |
| Alternative | "X vs Y" | Creates direct citation opportunities |
| Action | "give me a checklist" | Favors structured, reusable content |
Use SEO data, sales calls, support tickets, community threads, Reddit discussions, review-site language, and Google Search Console queries to build the first prompt library. Then rewrite each query into the way a person would ask an AI assistant.
If you need a quick diagnostic, run a sample of these prompts through Auspia's AI Search Visibility Checker and record which brands, sources, and page types appear repeatedly.
Step 2: build content that can be retrieved and quoted
AI systems do not reward clever intros. They reward clear, extractable answers.
A GEO-ready page usually has a strong first answer, then supporting proof. The first 80 to 120 words should tell the model what the page answers, who it is for, and what conclusion it supports. Do not hide the answer after five paragraphs of setup.
A useful page structure looks like this:
- Direct answer or recommendation.
- Short explanation of when the answer applies.
- Comparison table or decision matrix.
- Evidence with named sources and dates.
- Step-by-step checklist.
- FAQ written in natural question language.
- Last-updated note when freshness matters.
Tone matters more than most marketers want to admit. Promotional claims are weak inputs. "The leading platform for modern teams" gives a model almost nothing to reuse. "Best for mid-market SaaS teams that need technical audits, content briefs, and AI visibility reporting in one workflow" is much easier to compare, cite, and paraphrase.
The safest writing style is specific, calm, and sourced. Use plain claims. Add numbers when you have them. Name the source. Mention the date. Explain the limit.
Bad GEO sentence:
Our platform transforms AI search growth with powerful automation for every team.
Better GEO sentence:
Auspia is designed for teams that need to audit crawlability, check AI search visibility, and turn prompt-level gaps into SEO or GEO content tasks.
The second sentence is not louder. It is more useful.
Step 3: make the content technically accessible
A model cannot cite what its retrieval system cannot read.
For GEO, technical accessibility includes the basics: indexable HTML, stable URLs, clean titles, sensible headings, schema where useful, fast pages, and no accidental blocking in robots.txt. It also includes newer AI-facing details:
- Check whether important pages are blocked for common AI crawlers.
- Keep content visible in server-rendered HTML when possible.
- Avoid hiding core information behind tabs, scripts, forms, or login walls.
- Use canonical URLs consistently across localized and duplicate pages.
- Publish clear author, organization, date, and contact signals.
- Maintain
llms.txtwhen it helps agents understand your site structure.
Auspia has a Robots.txt AI Crawler Checker for the quick version of this audit. The deeper audit should also test whether your most important content can be extracted as plain text, because many retrieval systems do not see a page the way a browser user does.
Step 4: build authority outside your own site
Owned content is necessary, but it is rarely enough.
When answer systems compare sources, third-party evidence often carries more weight than a brand's own claims. This is especially true for comparison, recommendation, and "best option" prompts. A model wants safer evidence: reviews, expert roundups, documentation, forums, analyst pages, GitHub repos, YouTube transcripts, podcasts, partner pages, and credible editorial mentions.
For global teams, the distribution map should follow the buyer's trust path:
| Buyer question | Strong evidence sources |
|---|---|
| "Is this product reliable?" | Review sites, customer stories, uptime pages, support docs |
| "How does it compare?" | Comparison pages, third-party roundups, Reddit threads, analyst notes |
| "Can it solve my technical problem?" | Documentation, GitHub, Stack Overflow, technical blogs, videos |
| "Is the company real?" | About page, leadership profiles, press mentions, partner pages |
| "What do users dislike?" | Review excerpts, support content, changelogs, transparent limitations |
Do not fake this layer. Thin syndication, low-quality guest posts, and generic press releases may create pages, but they do not create trust. The better move is to place specific evidence where the buyer and the model both expect to find it.
Step 5: adapt by answer platform
One mistake in early GEO programs is treating every AI answer system as the same channel. They are not the same.
Caption: Different answer systems surface different evidence patterns, so GEO planning should not rely on one content channel.
A rough planning model:
| Platform or surface | What to prioritize | Practical action |
|---|---|---|
| Google AI Overviews | Pages that already align with search intent and trusted web sources | Improve classic SEO, add answer blocks, cite sources, strengthen topical coverage |
| ChatGPT search | Clear web pages, brand entities, current sources, useful comparisons | Publish extractable pages and maintain third-party mentions |
| Perplexity | Source-backed answers and fresh citations | Create pages with strong titles, dates, direct answers, and credible references |
| Microsoft Copilot / Bing | Bing-indexed content, entity clarity, web authority | Check Bing indexing, schema, citations, and partner profiles |
| Vertical AI tools | Domain-specific evidence | Build docs, datasets, case pages, and expert explanations in the places that field trusts |
This is not a fixed formula. It is a starting point. The right plan comes from testing prompts and logging which source types each platform actually uses in your category.
Step 6: measure GEO like an operating system
GEO reporting should not stop at "we were mentioned once." Mentions can be unstable. Citations can appear, disappear, or move between sources.
Build a weekly scorecard around a fixed prompt library:
| Metric | What it tells you |
|---|---|
| Mention rate | How often the brand appears in answers |
| Citation rate | How often the brand or its sources are cited |
| Answer position | Whether the brand appears first, middle, or as an afterthought |
| Competitor overlap | Which competitors appear for the same prompts |
| Source type | Whether answers use owned pages, third-party pages, forums, videos, or docs |
| Sentiment and accuracy | Whether the answer describes the brand correctly |
| Prompt cluster trend | Which buying situations are improving or weakening |
You also need a correction loop. If an AI answer gets your product wrong, do not just complain about the model. Find the source that taught it the wrong thing. Then update your pages, clarify documentation, add comparison content, and build better external evidence.
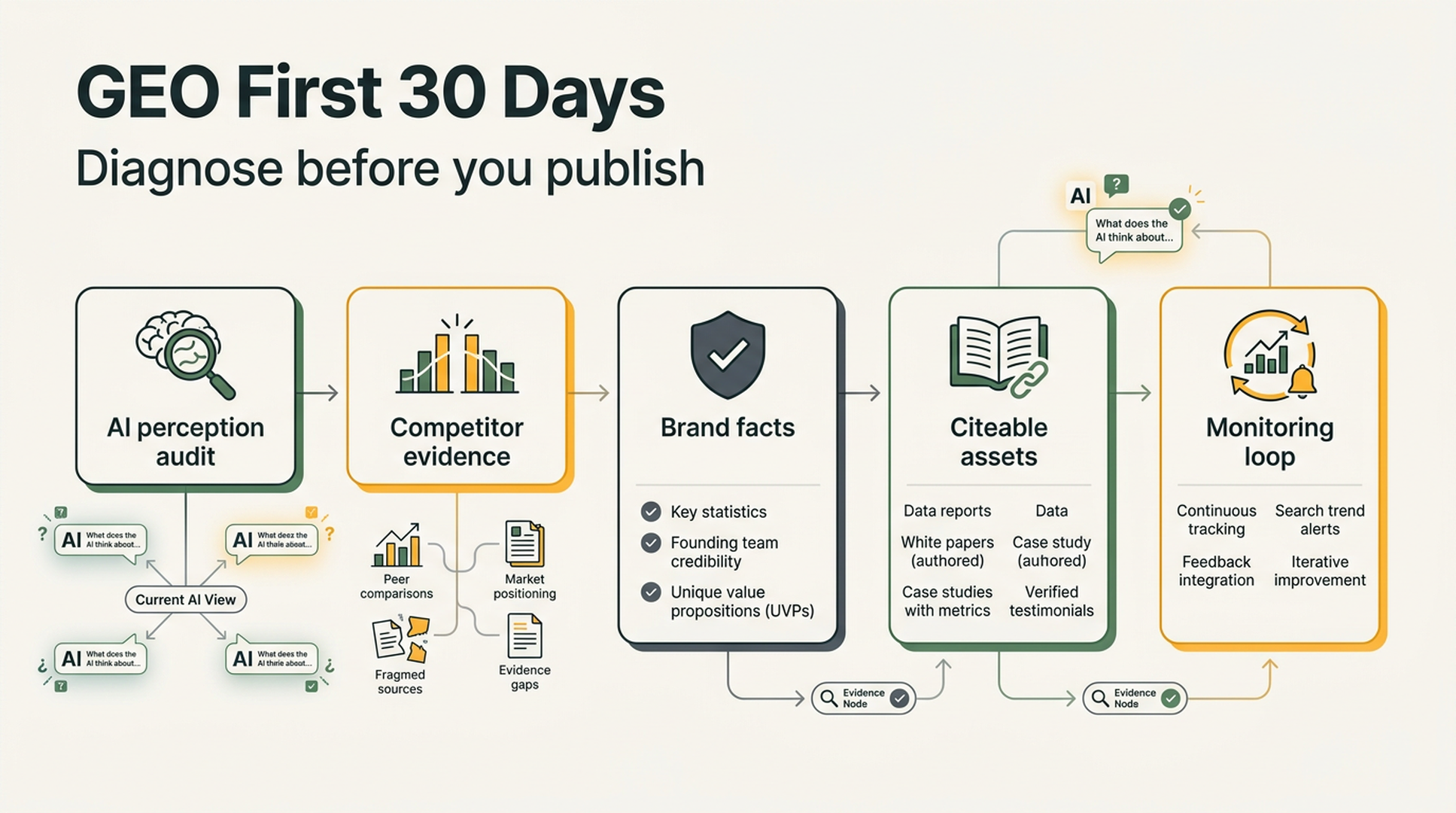
A 30-day GEO sprint
Here is a realistic first-month plan for a team that wants to move from theory to signal.
| Week | Work | Output |
|---|---|---|
| Week 1 | Build prompt library and baseline visibility | 50 to 150 prompts, competitor list, current AI answer screenshots |
| Week 2 | Audit technical access and owned content gaps | Crawlability fixes, page brief list, answer-block templates |
| Week 3 | Publish or update priority content | Comparison pages, FAQ sections, evidence tables, source-backed explainers |
| Week 4 | Build third-party evidence and measure again | Partner mentions, review updates, community answers, prompt trend report |
The sprint should end with a decision: which prompt clusters are worth scaling, which sources appear most often, and which content formats are actually reused by AI answers.
Common mistakes
The most common GEO mistake is treating it as bulk publishing. More pages do not help if the pages repeat the same claims, lack evidence, or cannot be crawled.
Other mistakes show up quickly:
- Optimizing for keywords instead of real AI prompts.
- Writing marketing copy when the model needs neutral evidence.
- Ignoring third-party sources and expecting owned pages to do all the work.
- Measuring one platform and assuming the result applies everywhere.
- Publishing content without dates, authors, citations, or clear entity signals.
- Blocking crawlers by accident, then wondering why nothing appears.
- Chasing citations without checking whether the answer is accurate or useful.
GEO rewards boring discipline. Clean pages. Clear evidence. Real sources. Repeated measurement.
Auspia takeaway
The best way to understand GEO is not as a new content trick. It is a source-selection problem.
AI answer systems need sources they can retrieve, trust, and quote. Your job is to make the brand a better source than the alternatives for the prompts that matter commercially.
That means the work sits across SEO, content, technical accessibility, digital PR, community, documentation, and analytics. If one team owns all of it alone, the program usually stalls.
Start small. Pick one product line, one buyer segment, and 50 prompts. Run the baseline. Fix crawlability. Rewrite the pages that answer high-intent questions. Add evidence where the model is likely to look. Measure again next week.
That is how GEO becomes a system instead of a slogan.
FAQ
What is GEO?
GEO stands for generative engine optimization. It is the practice of making a brand, page, product, or expert source more likely to appear in AI-generated answers from systems such as ChatGPT, Google AI Overviews, Perplexity, Copilot, and other answer engines.
Is GEO the same as SEO?
No. SEO focuses on visibility in search results. GEO focuses on visibility, citations, and accurate representation inside AI-generated answers. The two overlap because AI systems often retrieve web content, but GEO also depends on answer structure, third-party evidence, entity clarity, and prompt-level measurement.
How long does GEO take?
A first signal can appear within a few weeks if the site already has authority and the prompt set is narrow. Durable results take longer because models and retrieval systems need consistent evidence across owned pages, third-party sources, and technical signals.
What content format works best for GEO?
Direct answers, comparison tables, checklists, FAQs, dated explainers, documentation, and source-backed analysis tend to be easier for answer systems to reuse. The best format depends on the prompt. A buyer comparison needs different evidence than a technical troubleshooting question.
Can GEO guarantee AI citations?
No credible team can guarantee stable AI citations across all platforms. AI answers change by user, date, geography, model, and retrieval source. A good GEO program improves the odds by making content findable, trustworthy, and easy to cite, then measures the results over time.