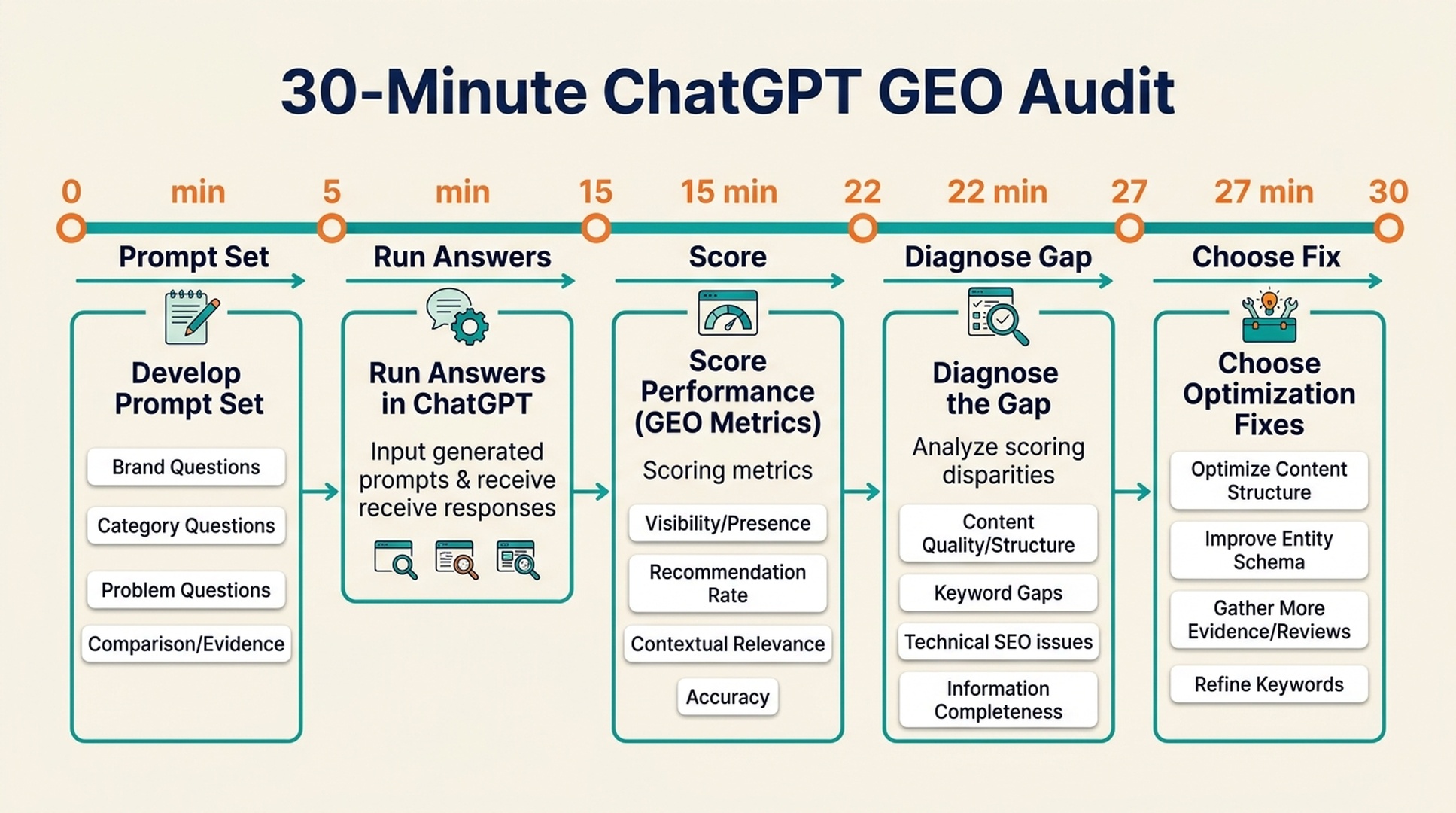
The 30-minute answer
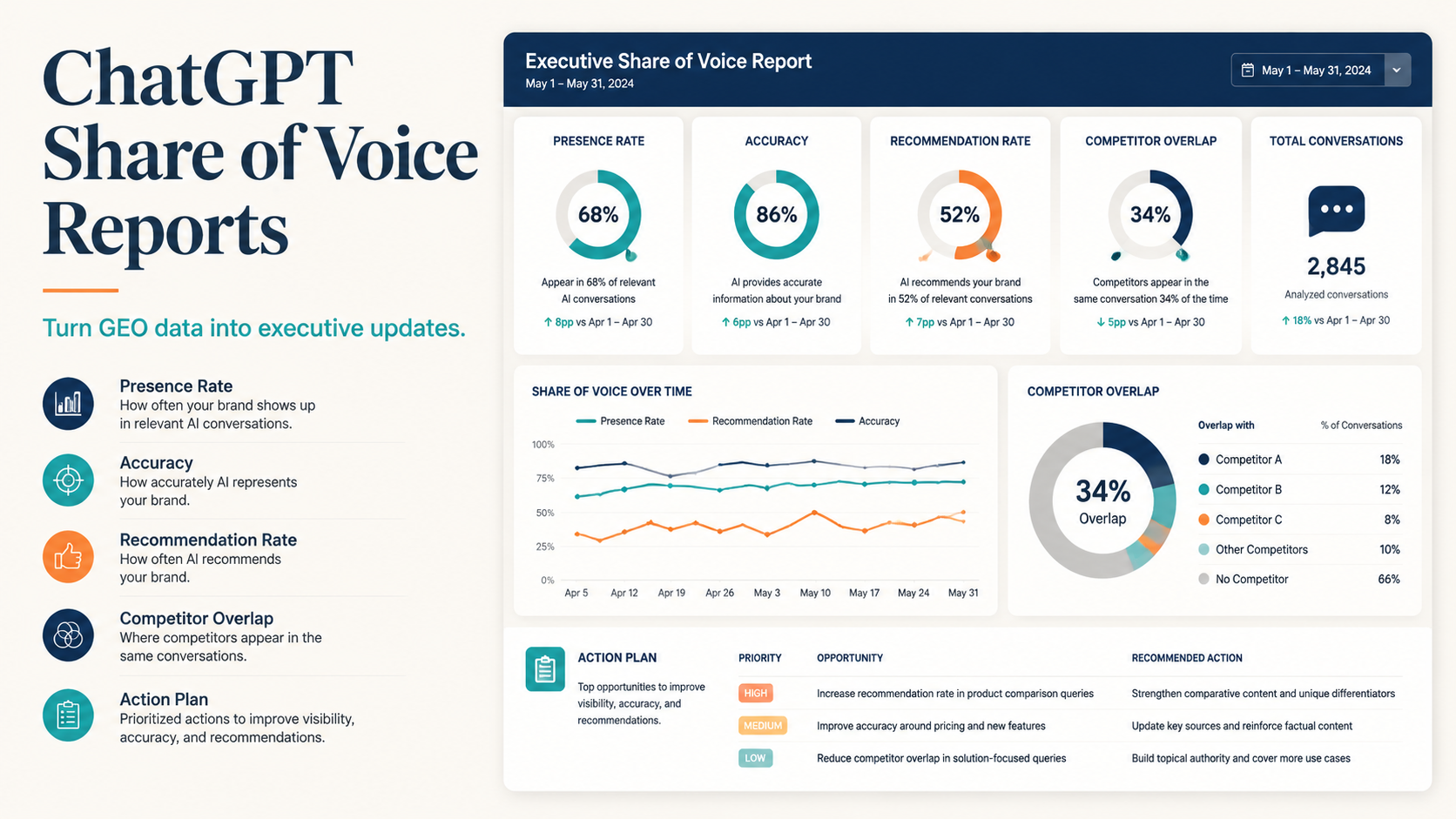
A ChatGPT GEO audit is a short visibility check that shows whether AI answer systems understand, mention, compare, and recommend your brand for the prompts your buyers might ask. In 30 minutes, you can test a small prompt set, score the answers, identify the most common visibility gaps, and decide which page or evidence asset to fix first.
This audit will not replace a full GEO program. It is a fast diagnostic. Use it when a founder, content lead, SEO manager, or growth team asks: "Do we show up in ChatGPT for the things we want to be known for?"
The output should be a simple scorecard: where the brand appears, how accurately it is described, which competitors appear instead, and what content or entity gap is most likely causing the problem.
What this audit measures
A good ChatGPT GEO audit looks beyond one brand-name prompt. Asking "What is our brand?" is useful, but it is not enough.
You need to test five visibility dimensions:
| Dimension | What it tells you |
|---|---|
| Brand understanding | Does ChatGPT describe your company accurately? |
| Category inclusion | Does your brand appear when users ask for tools or companies in your category? |
| Problem association | Does your brand appear when users describe the pain you solve? |
| Comparison visibility | Does your brand appear alongside alternatives or competitors? |
| Evidence strength | Does the answer include proof, examples, sources, or specific reasons? |
If your brand only appears in brand-name prompts, you have awareness but not recommendation visibility. If your brand appears in category and problem prompts with accurate context, your GEO foundation is stronger.
What you need before starting
You only need four inputs:
- Your brand name and domain
- Your primary category
- Three to five competitors or alternatives
- The main problem your product or service solves
Optional but useful:
- target country or language
- buyer persona
- product names
- high-intent use cases
- known wrong descriptions
- important third-party sources
Keep the audit lightweight. The point is to find the next fix, not to build a perfect research database.
Minute 0-5: write 15 audit prompts
Create three prompts for each of the five dimensions.
Brand understanding prompts
- What is [brand]?
- What does [brand] do?
- Who is [brand] for?
Category inclusion prompts
- What are the best [category] tools?
- Which platforms help with [category outcome]?
- What companies should I consider for [category]?
Problem association prompts
- How can I solve [problem]?
- What tools help with [problem]?
- How should a team handle [problem]?
Comparison visibility prompts
- What are alternatives to [competitor]?
- Compare [brand] with [competitor].
- Which is better for [use case], [brand] or [competitor]?
Evidence strength prompts
- What evidence supports [brand]'s claims?
- Are there examples of [brand] being used for [use case]?
- What are the strengths and limitations of [brand]?
Do not over-optimize the wording. Use prompts a real buyer might ask.
Minute 5-15: run the prompts and capture answers
Run the prompts in the AI systems you care about. If you only have time for one, start with ChatGPT. If you are doing a broader AI search check, include Perplexity, Gemini, Google AI-style answers, or other systems relevant to your market.
Capture:
- full answer text or screenshot
- whether your brand appears
- position/order if the answer is a list
- competitors mentioned
- description accuracy
- sources or citations if visible
- surprising claims
- missing proof
Do not correct the model during the audit. You are measuring what it says without coaching.
Minute 15-22: score each answer
Use a simple 0-5 score.

| Score | Meaning | What to do |
|---|---|---|
| 0 | Brand is absent | Check category pages, third-party evidence, and prompt fit |
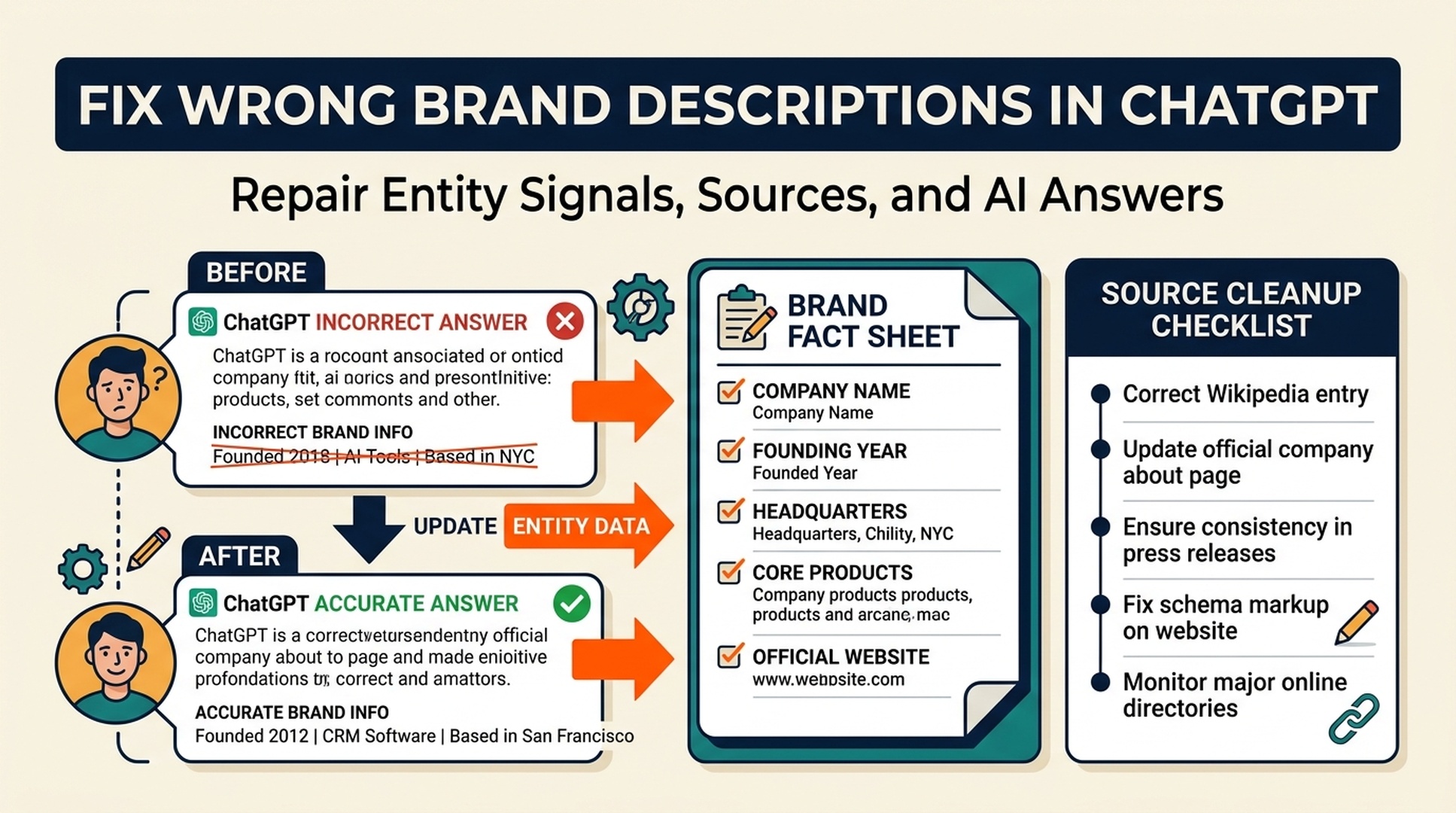
| 1 | Brand appears but is wrong | Fix entity facts and outdated sources |
| 2 | Brand appears but is vague | Improve product pages and use-case clarity |
| 3 | Brand is accurate but not competitive | Add comparison and differentiation assets |
| 4 | Brand is recommended with useful context | Strengthen proof and citations |
| 5 | Brand is recommended with evidence | Monitor and defend the position |
Score each prompt quickly. The score does not need to be perfect. It needs to reveal patterns.
Minute 22-27: diagnose the likely gap
Look for the dominant failure pattern.
| Pattern | Likely cause | First fix |
|---|---|---|
| Absent from category prompts | weak category association | category page or solution page |
| Wrong brand description | entity inconsistency | brand fact sheet and profile cleanup |
| Competitors appear but you do not | weak comparison footprint | alternatives or comparison page |
| Brand appears only in direct prompts | low problem association | use-case pages and educational content |
| Brand appears but no proof | thin evidence layer | case study, template, benchmark, review/profile update |
| Old product claims appear | stale external sources | directory, partner, podcast, and social profile updates |
The fastest fix is usually the page or source closest to the failure pattern.
For example, if the brand is absent from "best tools for [category]" prompts but described correctly in direct prompts, you probably need category and comparison assets, not another about-page rewrite.
Minute 27-30: choose the next action
End the audit with one priority, not a giant backlog.
Use this rule:
- If the description is wrong, fix entity clarity first.
- If the brand is absent from category prompts, build category relevance.
- If competitors dominate, build comparison context.
- If claims are vague, build proof.
- If answers cite old pages, clean stale sources.
Write the next action in this format:
Priority: Publish a comparison page for [category] because ChatGPT recommends three competitors in alternatives prompts but does not include [brand]. Add fit guidance, differentiators, proof links, and update two directory profiles with the same category language.
That is a useful audit output. "Improve GEO" is not.
Example audit summary
Here is a compact example for a B2B SaaS brand.
| Audit area | Result | Interpretation |
|---|---|---|
| Brand understanding | 3/5 | Brand is mostly described correctly |
| Category inclusion | 1/5 | Category prompts mention competitors instead |
| Problem association | 2/5 | Brand appears only in narrow prompts |
| Comparison visibility | 0/5 | Alternatives prompts miss the brand |
| Evidence strength | 1/5 | Answers lack proof or examples |
Recommended fix:
- Publish a category page that defines the market and use cases.
- Publish one alternatives page against the most common competitor.
- Add a proof section linking to a case study, template, or workflow example.
- Update review and directory profiles with the same category language.
- Rerun the same 15 prompts in 30 days.
This is enough to move from vague concern to a practical execution plan.
Common audit mistakes
Mistake 1: testing only your brand name
Brand-name prompts tell you whether ChatGPT knows you. They do not show whether buyers will discover or compare you.
Mistake 2: changing prompts every time
If you change the prompt set every audit, you cannot measure improvement. Keep a stable core set and add new prompts separately.
Mistake 3: treating one answer as the truth
AI answers can vary. Look for patterns across prompts, not one surprising response.
Mistake 4: ignoring wrong but positive answers
A flattering but inaccurate answer is still a problem. It can create poor-fit leads and brand confusion.
Mistake 5: jumping straight to content production
Sometimes the right fix is not a new blog post. It may be an about-page rewrite, directory update, comparison page, documentation page, or third-party evidence cleanup.
When to run this audit
Run a 30-minute ChatGPT GEO audit when:
- you launch a new product or positioning
- a competitor starts appearing in AI answers
- you publish comparison or category pages
- sales hears buyers mention ChatGPT recommendations
- you suspect the brand is described incorrectly
- you are planning a new content cluster
- leadership wants a simple AI visibility baseline
For ongoing programs, run a deeper monthly prompt library review. The 30-minute audit is best for quick diagnosis and prioritization.
FAQ
What is a ChatGPT GEO audit?
A ChatGPT GEO audit is a prompt-based review of whether ChatGPT-style AI answers understand, mention, compare, and recommend your brand for important buyer questions.
How many prompts do I need for a quick audit?
Fifteen prompts is enough for a 30-minute diagnostic: three brand prompts, three category prompts, three problem prompts, three comparison prompts, and three evidence prompts.
Should I use the same prompts every month?
Yes. Keep a stable core prompt set so you can compare results over time. You can add experimental prompts, but do not replace the baseline too often.
What is a good ChatGPT GEO audit score?
For early-stage brands, an average score of 3 across relevant prompts is a healthy first target. It means the brand is usually described accurately. Scores of 4-5 require stronger comparison context and evidence.
What should I fix first if my brand does not appear?
Start with the most likely gap: category clarity, comparison pages, use-case pages, third-party evidence, or entity consistency. The audit pattern should tell you which one matters most.
Author: Victor Lane, GEO Audit Specialist with 300+ Readiness Reviews at Auspia. Victor writes about readiness audits, checklists, scorecards, diagnostics, and practical GEO repair workflows.