Short answer
The strongest companies rarely advertise their GEO work because the advantage is fragile. Once competitors know which prompts, sources, comparison pages, review patterns, and entity signals are working, they can copy the visible layer and dilute the edge.
That does not mean GEO should be treated like a dark art. It means serious teams need two tracks: public content that helps users and AI systems understand the brand, plus private operating knowledge that should not be turned into a public case study too early.
In plain English: GEO is worth doing. Bragging about the exact playbook is usually not.
The odd silence around GEO
Ask a growth team whether AI search matters and most will say yes. Ask whether they are testing GEO, and the answer often gets vague.
"We're watching it."
"Too early to tell."
"Mostly content quality work."
Sometimes that is true. Many teams are still guessing. But in competitive categories, the quiet is also deliberate. If a brand has started to show up in ChatGPT, Gemini, Perplexity, Claude, Copilot, or AI overviews for commercial questions, it has little reason to hand competitors a map.
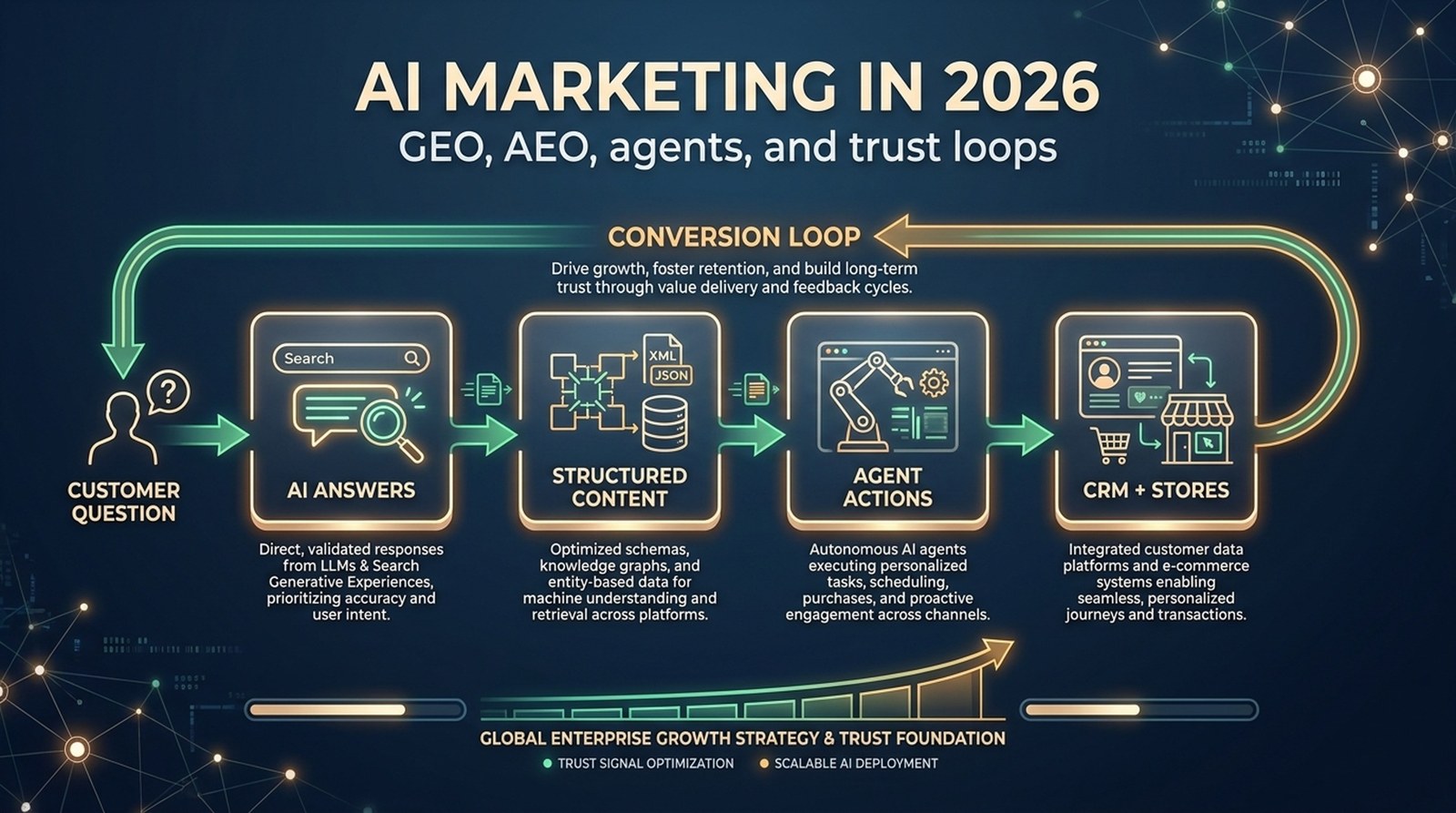
GEO is not just a traffic channel. It can shape the first shortlist a buyer sees. When someone asks an AI system "which tools should I compare?" or "who is trusted for this problem?" the answer can frame the entire buying process before the user visits a website.
That is why the best operators often talk about "content quality," "brand authority," or "answer readiness" in public. Internally, they are much more specific.
Reason 1: a GEO advantage can be copied faster than an SEO advantage
Traditional SEO has visible signals: pages, links, keyword rankings, technical structure. Competitors can study them, but they still have to build authority over time.
GEO has a different weakness. A lot of the surface area is easy to imitate once the pattern is visible.
If a competitor learns that you are winning AI answers because of a specific cluster of comparison pages, review summaries, partner mentions, documentation snippets, and category definitions, they can move quickly. They may not copy the underlying business, but they can copy the public evidence trail.
That matters because AI answers often synthesize categories. A brand that once appeared as the clear recommendation can become one of five similar options if the web fills with lookalike evidence.
The risk is not that competitors steal one blog post. The risk is that they learn the prompts you care about, the sources that influence answers, and the framing that makes your brand look like the obvious choice.
| What leaks | Why competitors care | Defensive habit |
|---|---|---|
| Winning prompts | Shows where buyer demand is forming | Keep prompt libraries private |
| Source patterns | Reveals which publications, directories, or pages influence answers | Track sources but avoid public over-sharing |
| Page templates | Makes content structure easy to imitate | Publish useful pages, not your internal scoring logic |
| Entity language | Shows how you want AI systems to categorize the brand | Keep public positioning consistent |
| Proof assets | Reveals reviews, cases, and data that carry weight | Build real evidence competitors cannot fake |
This is the first reason good companies stay quiet. They are not hiding because GEO is fake. They are hiding because the visible layer is learnable.
Reason 2: public hints can expose more than teams expect
A company does not need to publish its entire GEO strategy to leak useful information. A conference slide, a founder post, a case study, or a vendor quote can reveal enough for a competitor to reverse-engineer the plan.
A few examples:
- "We are focusing on comparison prompts" tells competitors where buyers are being influenced.
- "Our integration pages improved AI mentions" tells them which content asset matters.
- "Reviews were the missing piece" tells them to attack the trust layer.
- "We rewrote our category definitions" tells them the entity problem you solved.
- "Perplexity citations moved first" tells them which surface to monitor.
AI makes this easier. A competitor can feed public material into an internal research workflow and ask it to infer the likely prompt set, source map, content gaps, and next pages to build.
That does not mean companies should never share learnings. It means they should separate public education from operational disclosure. Teach the category. Do not publish the private map while it is still producing an edge.
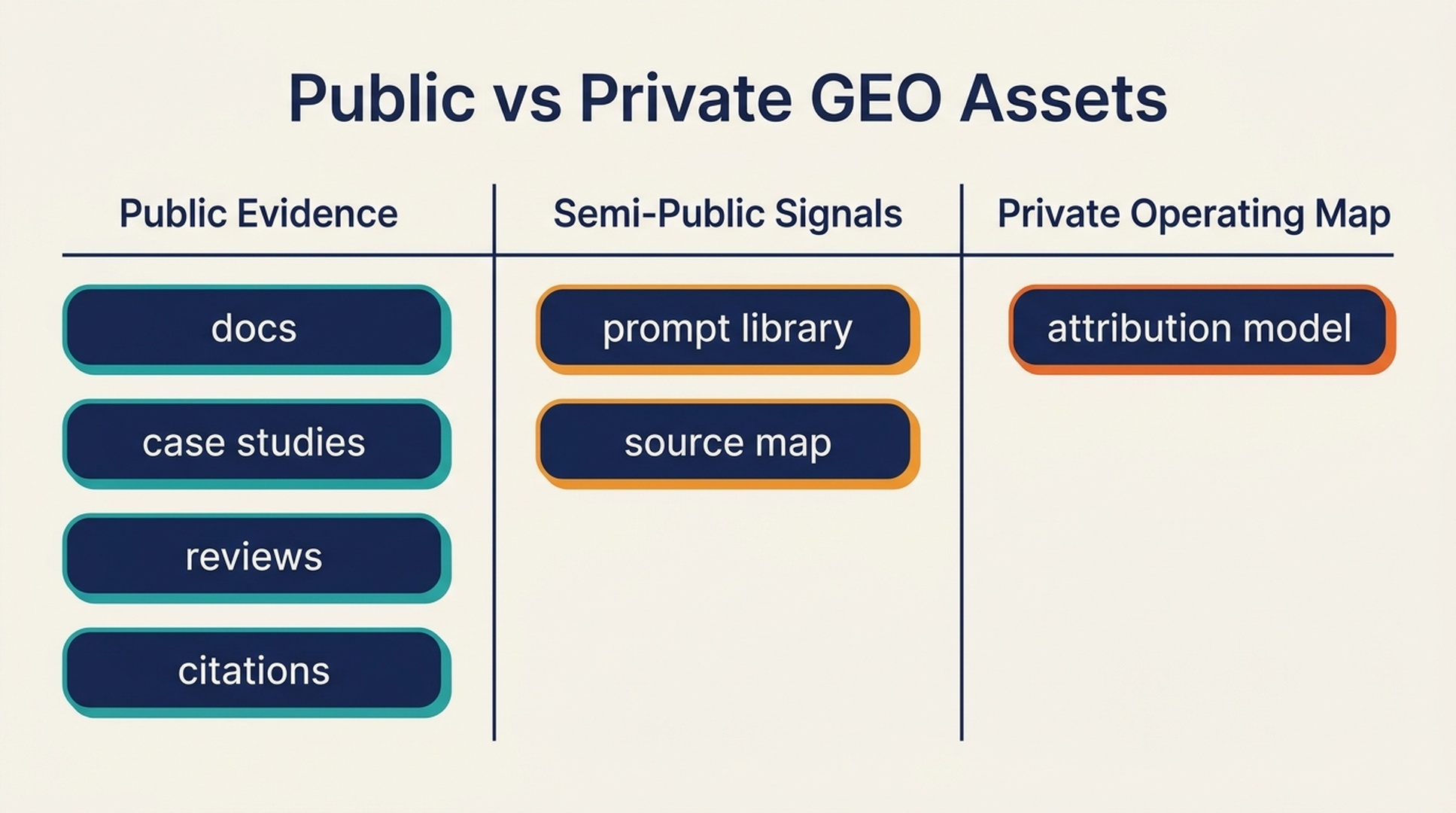
Caption: Good GEO programs separate public evidence from private operating knowledge.
Reason 3: GEO has a reputation problem
There is another reason teams avoid saying "we do GEO" too loudly: the term is already getting mixed with spam.
Some agencies use GEO to describe legitimate answer optimization: better content, clearer entities, more credible sources, and stronger evidence. Others use the same label for mass-produced pages, fake Q&A, synthetic reviews, spammy citations, and attempts to manipulate AI systems with low-quality content.
That creates a brand safety issue.
A serious company does not want customers, journalists, partners, or regulators to hear "GEO" and think "AI manipulation." So the public wording becomes safer:
- "We improved our content architecture."
- "We made product documentation clearer."
- "We strengthened third-party proof."
- "We are testing AI search visibility."
- "We are making our brand easier to understand across search and AI systems."
That language is not cowardly. It is often more accurate. Good GEO is not about poisoning AI answers. It is about making real evidence easier to retrieve, verify, and cite.
Our view at Auspia : if a GEO tactic would embarrass you in a customer meeting, do not use it. The durable version of GEO is closer to evidence management than growth hacking.
Reason 4: the ROI is hard to defend in a boardroom
GEO can influence demand before the click, which is exactly why it is valuable. It is also why attribution gets messy.
A buyer may ask an AI assistant for a shortlist, see your brand, search your name later, read a comparison page, ask a colleague, click a paid ad, and then convert through direct traffic. Which channel gets credit?
Most analytics systems will not answer that cleanly.
That creates an internal politics problem. If a team publicly claims "GEO drove growth," someone will ask for the spreadsheet. The spreadsheet may show brand search increasing, sales conversations improving, referral traffic shifting, and AI citations appearing, but not a neat one-channel ROI line.
So teams keep the language modest. They call it an experiment. They report leading indicators. They avoid big public claims until measurement catches up.
That is the right instinct. Overclaiming GEO results is a fast way to lose trust internally.
A better measurement model looks like this:
| Metric type | What to track | Why it matters |
|---|---|---|
| Visibility | Brand appears in target AI prompts | Shows whether the brand enters the answer set |
| Citation quality | Which sources are used in answers | Shows which evidence systems trust |
| Accuracy | Category, positioning, pricing, geography | Prevents wrong answers from spreading |
| Competitive share | How often competitors appear instead | Shows whether the answer set is shifting |
| Assisted demand | Brand search, direct traffic, sales mentions | Captures demand influenced before the visit |
| Conversion quality | Pipeline from AI-influenced journeys | Keeps the work tied to business outcomes |
For a first pass, use a small prompt library and an AI Search Visibility Checker . Do not pretend it solves attribution. Use it to see whether you are present, absent, miscategorized, or being outranked by better evidence.
Reason 5: the real moat is not the tactic, it is the evidence
Here is the part many GEO discussions miss. The public tactic is rarely the moat.
A comparison page can be copied. A schema pattern can be copied. A prompt list can leak. A content outline can be recreated by any decent competitor with AI.
Real evidence is harder to fake.
That includes:
- Customers who mention the same strengths repeatedly
- Product documentation that answers technical questions better than competitors
- Case studies with specific constraints and outcomes
- Independent reviews that agree with the brand's positioning
- Partner pages and integrations that confirm category fit
- Community discussions that use the brand naturally
- Original data that competitors cannot scrape from a landing page
This is why strong GEO programs often look boring from the outside. They are not just publishing more content. They are cleaning up the evidence layer around the company.
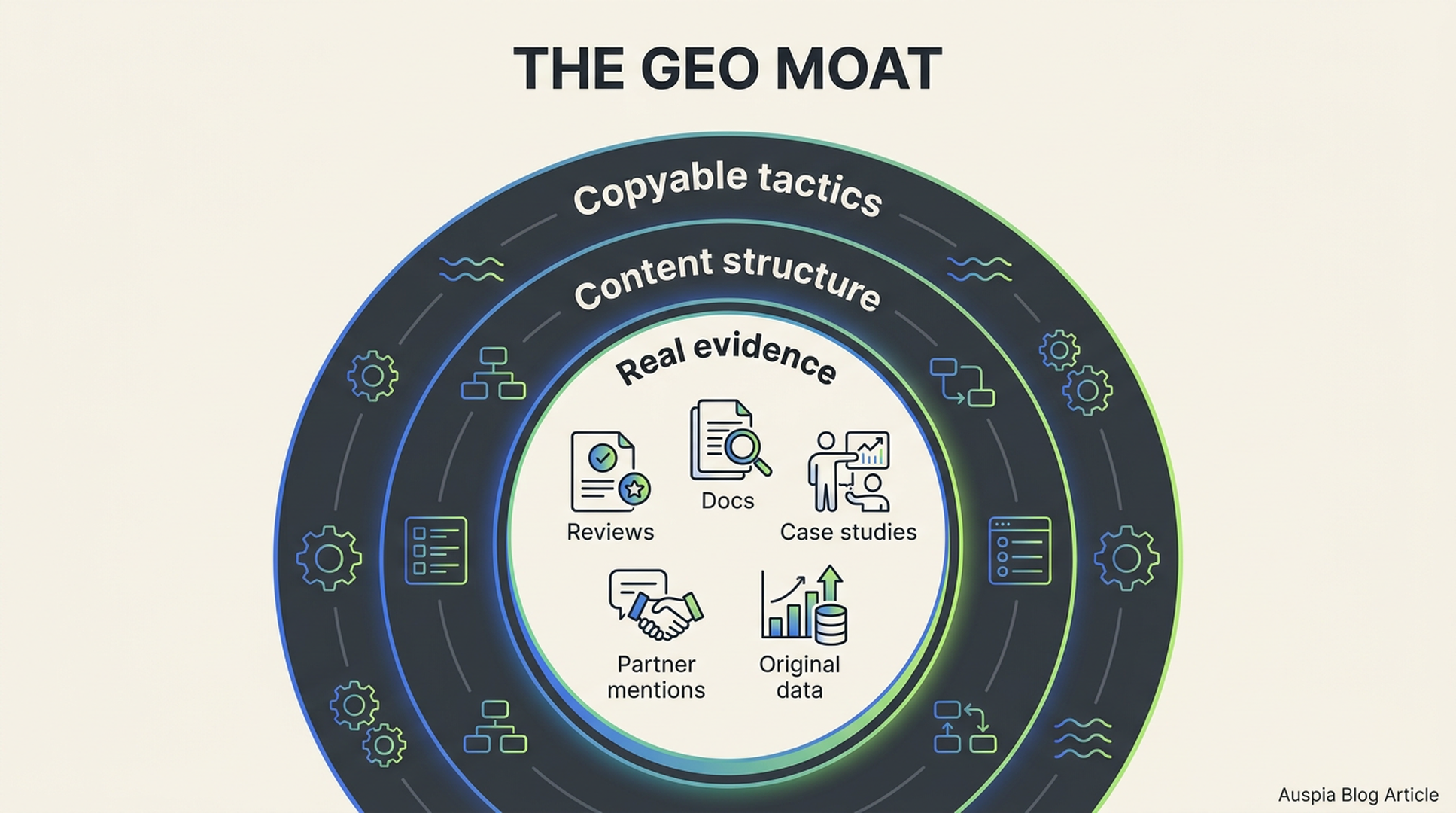
Caption: GEO tactics are easy to imitate. The evidence behind them is much harder to copy.
What to keep private and what to publish
The answer is not to become secretive about everything. A brand still needs public content. AI systems cannot cite evidence that does not exist.
The trick is deciding what belongs in public, semi-public, and private layers.
| Layer | Safe to publish | Keep private |
|---|---|---|
| Public evidence | Clear product pages, docs, case studies, FAQs, comparisons | Internal scoring, prompt weights, conversion assumptions |
| External proof | Reviews, partner pages, customer stories, third-party articles | Outreach lists, negotiation details, source influence ranking |
| Measurement | Broad visibility trends and learning themes | Exact prompt library, competitor gap map, attribution model |
| Positioning | Category language and buyer use cases | Sensitive roadmap, internal taxonomy, priority accounts |
| Operations | General content quality standards | Automation workflows, monitoring rules, private datasets |
A good rule: publish what helps buyers make better decisions. Keep private what helps competitors copy your decision system.
How to build GEO without creating reputational risk
If your team wants GEO visibility without sounding like it is trying to manipulate AI systems, use a clean operating standard.
1. Start with real buyer questions
Build prompts from sales calls, support tickets, search terms, comparison pages, community threads, and customer interviews. Avoid fantasy prompts that make the brand look good but do not match how buyers ask.
2. Audit answer presence before publishing more content
Check whether AI systems mention the brand, cite accurate sources, place it in the right category, and compare it fairly with alternatives. Absence is one problem. Wrong presence is another.
3. Fix entity confusion
Make sure the brand name, product names, category, target users, official URLs, and descriptions are consistent across the website, profiles, documentation, and third-party listings.
4. Strengthen evidence before scaling pages
Do not mass-produce thin pages. Add proof: specific examples, customer language, documentation, benchmarks, review summaries, partner references, and transparent limitations.
5. Use structured content because it helps readers
Tables, summaries, FAQs, and schema are useful when they make the answer clearer. They become risky when they are used to flood the web with shallow near-duplicates.
6. Monitor competitors, but do not chase every answer
Some prompts are not worth winning. Focus on queries tied to real purchase intent, high-value customer segments, or strategic category ownership.
A practical private GEO operating model
For most teams, a lightweight model is enough.
| Workstream | Owner | Cadence | Output |
|---|---|---|---|
| Prompt library | Growth or SEO lead | Monthly | 20-100 buyer prompts grouped by intent |
| Answer audit | SEO/GEO analyst | Biweekly | Mention rate, citations, competitor share, errors |
| Evidence backlog | Content and product marketing | Monthly | Pages, docs, case studies, review gaps |
| Entity cleanup | SEO and web team | Quarterly | Consistent profiles, schema, product descriptions |
| Risk review | Legal, brand, growth | Quarterly | Claims, review usage, automation boundaries |
| Exec reporting | Growth lead | Monthly | Trends, risks, next actions, business signals |
This keeps the work specific without turning GEO into a black-box agency exercise. It also gives leadership enough structure to fund the work without demanding fake precision.
Auspia takeaway
The companies that stay quiet about GEO are not necessarily doing anything shady. Many are just being rational.
If a strategy depends on prompt selection, source influence, entity clarity, and hard-won evidence, broadcasting the details can weaken the advantage. At the same time, hiding everything is not a strategy. AI systems need public proof.
The mature move is to publish the evidence buyers need, keep the operating map private, measure AI visibility carefully, and avoid tactics you would not want associated with your brand.
GEO rewards companies that are easy to understand, easy to verify, and hard to imitate. That last part is why the smartest teams do the work quietly.
FAQ
Why do companies avoid talking publicly about GEO?
They often avoid it because GEO advantages can be reverse-engineered. Publicly sharing winning prompts, source patterns, page templates, or evidence gaps can help competitors copy the visible layer of the strategy.
Is GEO risky for brand reputation?
It can be if the work relies on spam, fake reviews, synthetic Q&A, or misleading claims. Legitimate GEO focuses on clearer content, stronger evidence, consistent entities, and accurate citations.
Should GEO work be secret?
The operating details should often stay private, especially prompt libraries, source maps, and attribution assumptions. The evidence itself should be public enough for buyers and AI systems to verify the brand.
How can a company measure GEO if attribution is unclear?
Track leading indicators: AI answer mentions, citation quality, answer accuracy, competitor share, brand search changes, sales-call mentions, and assisted pipeline. Avoid claiming perfect one-channel ROI too early.
What is the safest way to start GEO?
Start with a buyer prompt audit, check whether your brand appears accurately, fix entity inconsistencies, and publish evidence-rich content that answers real decision questions. Do not begin with automation at scale.