Concise summary
Hermes Agent is useful for GEO when you treat it as an operating layer, not as a magic content writer. The job is simple: give the agent a stable prompt library, let it monitor AI answers on a schedule, ask it to classify citation and entity gaps, then route high-risk changes through human approval before anything goes live.
That matters because GEO work is repetitive. Teams need to check whether AI systems understand the brand, cite the right pages, compare competitors fairly, and surface current evidence. Doing that once is an audit. Doing it every week is a system.
Hermes Agent is a good fit for that second version because it is designed around persistent agent work. Nous Research describes Hermes Agent as an open-source agent that "grows with you," with a learning loop, persistent memory, scheduling, and multi-channel operation. Public documentation and the GitHub project also position it as self-improving agent infrastructure rather than a single-session chatbot.
The practical playbook below shows how to use Hermes Agent for automated GEO without letting an agent publish unchecked claims, spam low-quality pages, or confuse activity with AI search visibility.

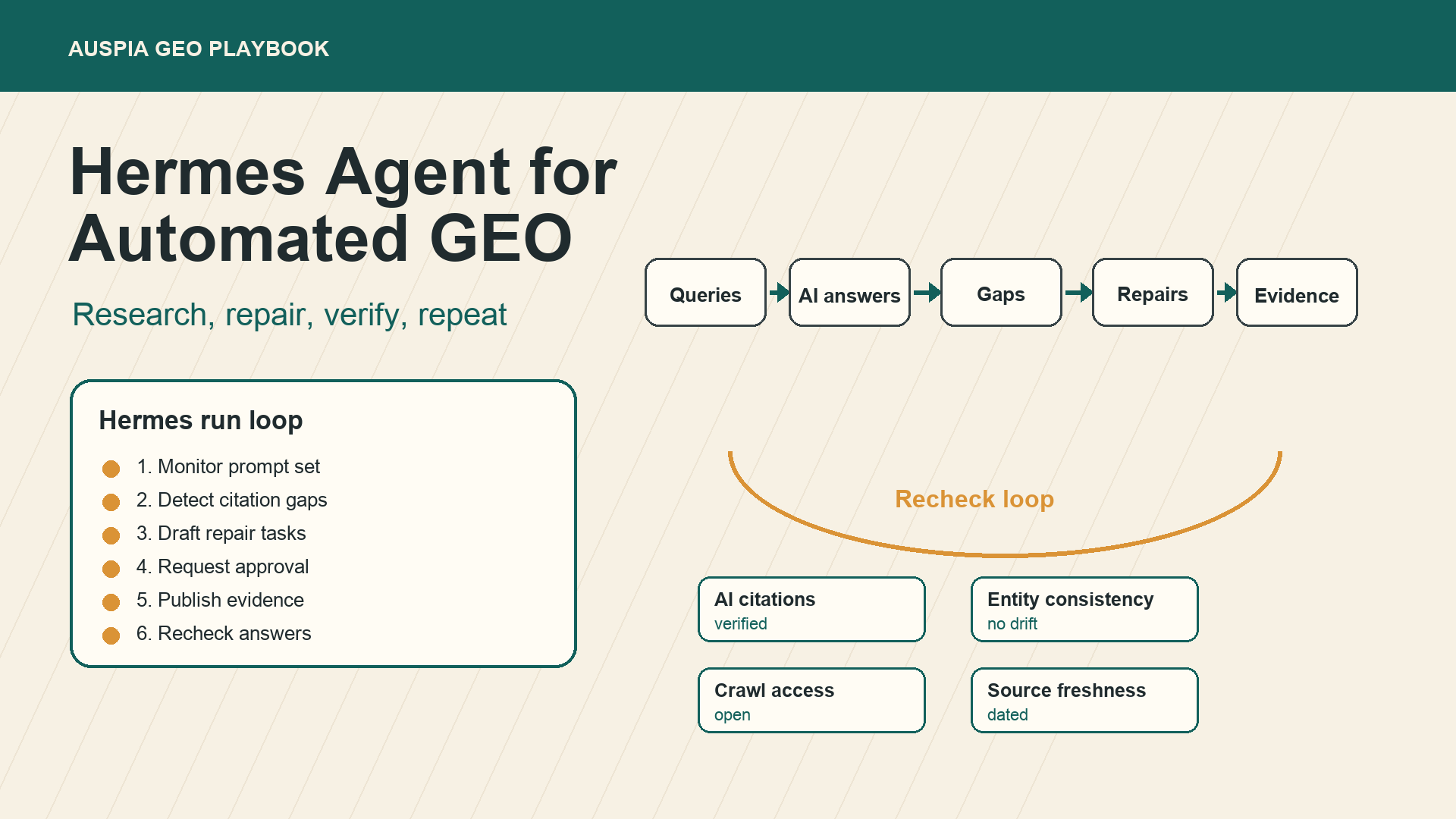
Caption: A safe Hermes Agent GEO loop starts with monitoring and ends with verification, not content generation.
What Hermes Agent changes about GEO work
Traditional GEO work often looks like this:
- Someone runs a few prompts in ChatGPT, Perplexity, Gemini, or Google AI Mode.
- They paste screenshots into a doc.
- The team argues about why competitors were cited.
- A writer updates one page.
- Nobody checks the same prompt set again for three weeks.
That process is too fragile. AI answer surfaces change, prompts drift, competitors publish new evidence, and your own pages get stale. GEO needs a cadence.
Hermes Agent helps because it can hold context across runs. In a GEO setup, that persistent context should include:
- the brand's entity profile and preferred wording;
- the products, use cases, and regions the company wants to be cited for;
- the approved prompt library;
- previous AI answer snapshots;
- known citation gaps;
- technical constraints such as robots.txt, sitemap, structured data, and llms.txt policy;
- the team's rules for what the agent may do alone and what needs approval.
Do not start by asking Hermes to "improve our GEO." Start by giving it a repeatable job with inputs, outputs, and review gates.
The six-part Hermes GEO loop
1. Build a prompt library the agent can run repeatedly
A GEO prompt library is not a random list of keywords. It should cover the questions where AI visibility could affect pipeline or purchase decisions.
Use at least five prompt groups:
| Prompt group | Example | Why it matters |
|---|---|---|
| Category discovery | "What are the best tools for checking AI search visibility?" | Tests whether your brand appears in broad recommendation answers. |
| Problem diagnosis | "Why is my brand not cited in AI answers?" | Shows whether AI systems connect your content to real user pain. |
| Comparison | "Auspia vs other GEO tools" | Reveals positioning gaps and competitor framing. |
| Implementation | "How do I create an llms.txt file for my site?" | Tests whether your practical guides are cite-ready. |
| Local or vertical intent | "GEO checklist for B2B SaaS websites" | Checks whether the brand appears in specific buying contexts. |
Store each prompt with metadata: target region, language, buyer stage, product line, expected entities, and the page that should be eligible for citation.
Hermes can then run this library on a schedule and keep the results comparable across time.
2. Capture AI answers in a structured format
The agent should not merely say "we were mentioned." It should save each run in a structured record.
A useful record includes:
- prompt text;
- platform tested;
- date and time;
- answer summary;
- whether the brand was mentioned;
- cited URLs;
- competitors mentioned;
- claims made about the brand;
- missing or outdated facts;
- screenshots or exports when available;
- confidence rating.
This is where many teams get sloppy. They look at one answer and react emotionally. Hermes should help build a decision log instead.
3. Classify the gap before creating content
Not every missing citation is a content problem. Hermes should classify each miss before suggesting a fix.
Common GEO gap types:
| Gap type | What it looks like | Better fix |
|---|---|---|
| Evidence gap | Competitors are cited because they have fresher examples, benchmarks, or docs. | Publish stronger source material, not another opinion post. |
| Entity gap | The model does not connect your brand to the category. | Improve entity consistency across pages, schema, profiles, and third-party mentions. |
| Crawl gap | Your best source exists but is blocked, buried, or hard to parse. | Check robots.txt, sitemap, internal links, page rendering, and llms.txt guidance. |
| Intent gap | Your page answers a nearby question but not the exact prompt. | Add a direct section, table, FAQ, or comparison block. |
| Trust gap | The answer cites neutral or third-party sources instead of vendor pages. | Build quotable evidence outside your own site. |
This classification step keeps the agent from defaulting to "write more content." More content is often the wrong answer.
4. Turn gaps into repair tasks
After classification, Hermes can draft a task list. Each task should be small enough for a human to approve or reject quickly.
Good repair tasks look like this:
- Add a dated definition section to the GEO guide explaining what changed in AI answer behavior.
- Create a comparison table that explains when to use an AI search visibility checker versus a traditional SEO audit.
- Update the product page with a crawlable feature list and clear entity language.
- Add internal links from the AI Search Visibility Checker page to the relevant GEO guide.
- Check whether robots.txt blocks AI crawlers that the business actually wants to allow.
- Create a third-party evidence target list for review sites, partner pages, or public case studies.
Bad repair tasks are vague: "optimize GEO," "write more thought leadership," "make the page better." Hermes should be trained to reject those.
5. Add approval gates before publishing
Hermes can monitor, classify, draft, and report with low risk. Publishing is different.
Use approval gates for anything that changes public claims, pricing, rankings, legal language, customer references, third-party comparisons, or crawler policy. The agent can prepare the work, but a human should approve the final version.
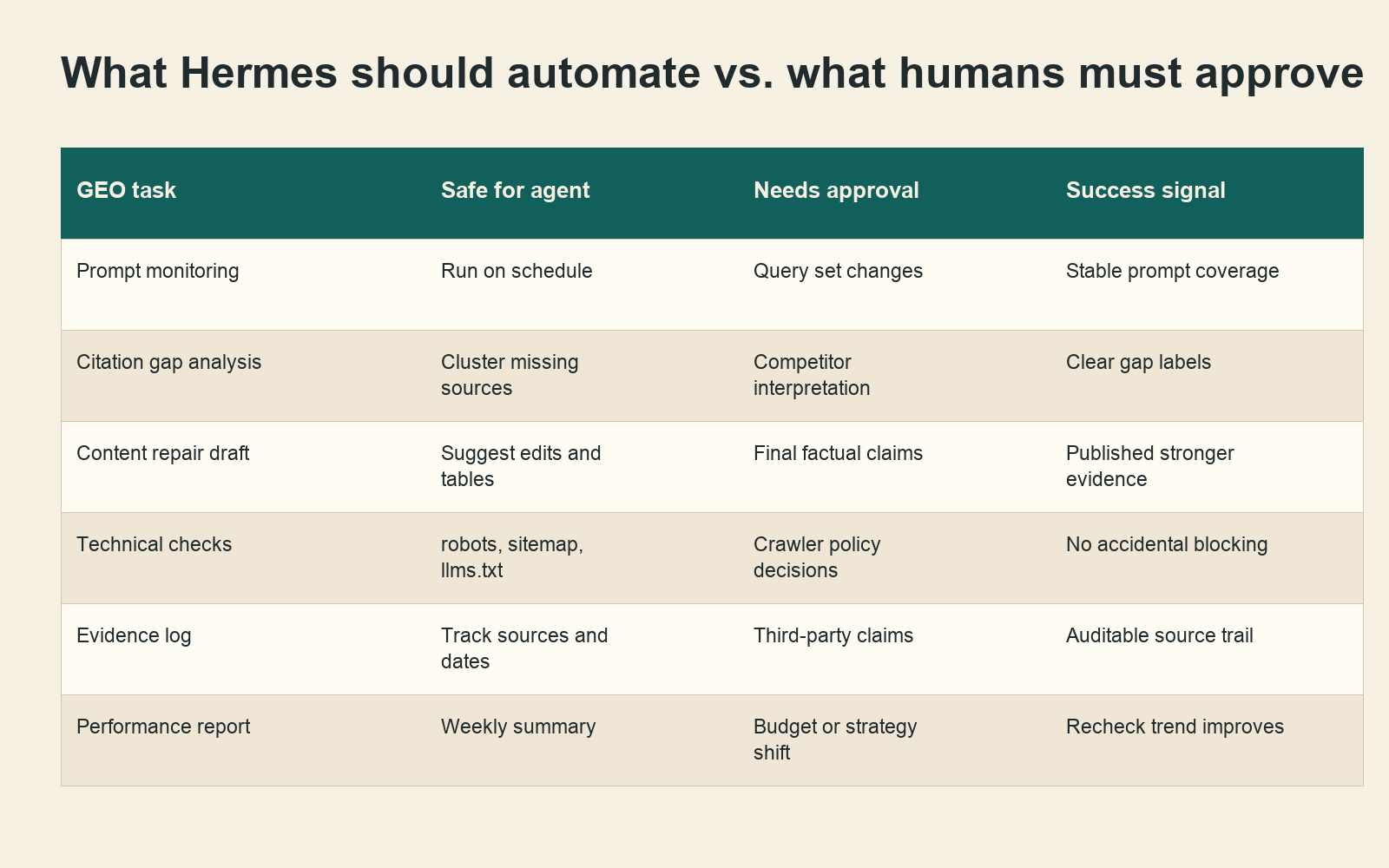
Caption: Hermes should automate repetitive analysis, but humans should approve claims, strategy, and public evidence.
What to automate and what to keep human
A useful Hermes GEO setup has a clear boundary.
| Workstream | Agent can handle | Human should own |
|---|---|---|
| Prompt monitoring | Run approved prompts on a schedule and save answer records. | Decide which prompts represent business priorities. |
| Citation analysis | Extract URLs, domains, competitors, and repeated patterns. | Interpret why a source deserves trust in the market. |
| Content repair | Draft sections, tables, FAQs, schema suggestions, and internal-link changes. | Approve claims, tone, evidence quality, and final publication. |
| Technical GEO | Check sitemap, robots.txt, canonical tags, page status, and llms.txt presence. | Decide crawler access policy and risk tolerance. |
| Reporting | Produce weekly summaries and change logs. | Decide whether the trend justifies investment. |
| Learning loop | Store reusable fixes as skills. | Remove bad learned patterns before they spread. |
This boundary is the difference between an agentic GEO system and a content spam machine.
Example Hermes Agent workflow for one GEO cycle
Here is a practical weekly workflow for a B2B SaaS site.
Monday: run the prompt set
Hermes runs 50 to 150 approved prompts across the priority categories. It records answer text, citations, brand mentions, competitor mentions, and source domains.
The output is a prompt-level table, not a narrative report.
Tuesday: classify gaps
Hermes groups misses by cause:
- 18 prompts show no brand mention;
- 11 prompts mention the brand but cite no Auspia page;
- 7 prompts cite outdated competitor explanations;
- 4 prompts appear affected by missing comparison content;
- 3 prompts show possible crawl or indexation issues.
A human reviews the classification before repair tasks are created.
Wednesday: draft repairs
Hermes creates proposed edits. For example:
- add a "How AI search visibility is measured" section to a tool page;
- create a new FAQ block for prompts that ask about llms.txt;
- rewrite a comparison paragraph that is currently too vague;
- add an internal link from an existing SEO article to a GEO explainer;
- produce a short evidence brief for third-party outreach.
Thursday: publish approved fixes
The team approves a small batch of changes. The safest early target is existing pages, because they already have context, internal links, and some authority.
New pages should only be created when the prompt library shows a recurring intent gap.
Friday: recheck and log
Hermes reruns the affected prompts and records whether anything changed. Do not expect instant citation movement. The point is to build a clean experiment log:
- what changed;
- when it changed;
- which prompts were affected;
- which AI answer systems were tested;
- whether citations, mentions, or answer framing improved.
Over time, this log becomes more valuable than any single AI answer screenshot.
A starter instruction for Hermes Agent
Use a starter instruction like this and adapt it to your stack:
You are the GEO operations agent for this website. Your job is to monitor approved AI-search prompts, record brand mentions and citations, classify gaps, and propose repair tasks. Do not publish content, change crawler policy, make competitor claims, or invent customer evidence without approval.
For each run, produce:
1. prompt results table;
2. citation and mention summary;
3. gap classification;
4. proposed repair tasks;
5. risk flags;
6. recheck plan.
Prefer small, verifiable fixes over broad content recommendations. If evidence is missing, say evidence is missing. If a page is blocked, report the technical issue before suggesting copy changes.
That instruction is intentionally boring. Boring is good here. GEO automation needs discipline more than personality.
Metrics to track
Do not measure Hermes Agent by the number of pages it creates. Measure whether the system improves the quality and consistency of your AI visibility work.
Track these metrics:
| Metric | What it tells you |
|---|---|
| Prompt coverage | Whether the team is testing the right commercial and informational questions. |
| Brand mention rate | Whether AI systems associate your brand with the target category. |
| Citation rate | Whether your pages are being used as sources, not merely named. |
| Citation quality | Whether cited pages are relevant, current, and conversion-useful. |
| Competitor co-mentions | Whether the brand appears in the right comparison set. |
| Gap resolution time | How quickly the team turns a detected issue into a reviewed fix. |
| Recheck outcome | Whether fixes correlate with better answer inclusion over time. |
Auspia's view: the best GEO teams will not be the ones that publish the most AI-assisted content. They will be the ones with the cleanest feedback loop between AI answer observation, source improvement, and verification.
Common mistakes
Letting the agent publish everything it drafts
This is the fastest way to create thin pages, unsupported claims, and internal contradictions. Hermes should prepare work. Humans should approve public facts.
Treating citations as the only goal
A citation in a bad answer may not help the business. Track whether the answer frames the brand accurately and sends users to a useful page.
Ignoring technical access
If important pages are blocked, hard to render, missing from the sitemap, or poorly linked, more writing will not fix the problem. Run technical checks before asking for new copy.
Rewriting pages without evidence
AI systems often cite pages that are clear, current, and externally corroborated. If your page has no data, examples, screenshots, documentation, or third-party validation, a copy refresh may not be enough.
Changing prompts every week
If the prompt set constantly changes, you cannot tell whether visibility improved. Keep a stable core set and add experimental prompts separately.
Where Auspia fits
Hermes Agent can run the operating loop. Auspia helps teams decide what to check, how to score it, and which fixes are worth doing.
A practical stack looks like this:
- use Hermes Agent to schedule monitoring, maintain memory, and draft repair tasks;
- use Auspia tools to inspect GEO readiness, AI search visibility, crawl access, and page quality;
- use human review for claims, positioning, and strategy;
- use the decision log to turn one-off fixes into an operating model.
If you are starting from zero, run a baseline with Auspia's GEO Score Checker , create a 50-prompt library, then ask Hermes to monitor it weekly for one month before expanding the workflow.
Checklist: first 30 days
| Week | Action | Output |
|---|---|---|
| 1 | Define target entities, products, competitors, and prompt groups. | Approved GEO prompt library. |
| 1 | Audit crawl access, sitemap, structured data, and llms.txt policy. | Technical readiness notes. |
| 2 | Configure Hermes to run prompts and save structured records. | First answer and citation baseline. |
| 2 | Create the gap taxonomy and approval rules. | Repair workflow with risk gates. |
| 3 | Fix the highest-confidence evidence and intent gaps. | Approved page updates or source assets. |
| 4 | Rerun affected prompts and compare results. | Recheck report and next task queue. |
FAQ
Can Hermes Agent fully automate GEO?
It can automate a large part of the operating loop: monitoring, extraction, classification, drafting, reporting, and rechecking. It should not fully automate public claims, crawler policy, competitor comparisons, or evidence decisions without review.
Is Hermes Agent only useful for developers?
No. A developer may be needed for setup, integrations, and safe deployment, but the workflow itself is a growth and content operations process. The most important inputs are prompt design, evidence quality, and approval rules.
How often should Hermes run GEO checks?
Weekly is enough for most teams. Daily checks can create noise unless the site is in a fast-moving category or the team is actively testing a launch, pricing change, or major content update.
What should Hermes learn over time?
It should learn your approved prompt structure, recurring gap types, preferred repair formats, entity wording, evidence standards, and reporting style. It should not learn to bypass review just because a previous edit was approved.
What is the biggest risk?
The biggest risk is turning GEO into automated content production. AI answer visibility improves when the web has clear, crawlable, trustworthy evidence about your brand. Hermes can help maintain that system, but it cannot replace the need for real evidence.
Sources and further reading
- Nous Research, Hermes Agent official site and documentation: https://hermes-agent.nousresearch.com/
- NousResearch/hermes-agent GitHub repository: https://github.com/nousresearch/hermes-agent
- GEO research paper, "GEO: Generative Engine Optimization": https://arxiv.org/abs/2311.09735
- Auspia GEO resources and tools: https://auspia.ai/tools