The point of a GEO prompt library
A GEO prompt library is a repeatable set of questions you use to test whether AI systems understand, mention, compare, cite, or recommend your brand.
It is not a list of prompts for writing blog posts.
It is a visibility diagnostic.
A good prompt library helps you answer:
- Does ChatGPT know what our brand is?
- Are we included in category recommendations?
- Which competitors appear instead of us?
- Are we cited by AI search tools?
- Do AI answers describe us correctly?
- Which buyer questions exclude us?
- What content or evidence should we fix next?
Start with 50 prompts. That is enough to see patterns without turning the process into a spreadsheet swamp.
How to use this library
Run the prompts across the AI surfaces that matter to your audience. For many teams, that means ChatGPT, Perplexity, Gemini, and Google AI Overviews when relevant.
For each prompt, record:
| Field | What to capture |
|---|---|
| Platform | ChatGPT, Perplexity, Gemini, AI Overview, etc. |
| Prompt wording | Exact prompt used |
| Brand mentioned | Yes or no |
| Competitors mentioned | Which brands appear |
| Citations | Which sources are cited, if any |
| Accuracy | Correct, mostly correct, partly wrong, harmful |
| Score | 0-3 visibility score |
| Next action | Content, entity, evidence, or technical fix |
Use the same prompts every two to four weeks. Do not rewrite the whole library every time. Consistency is what makes the data useful.
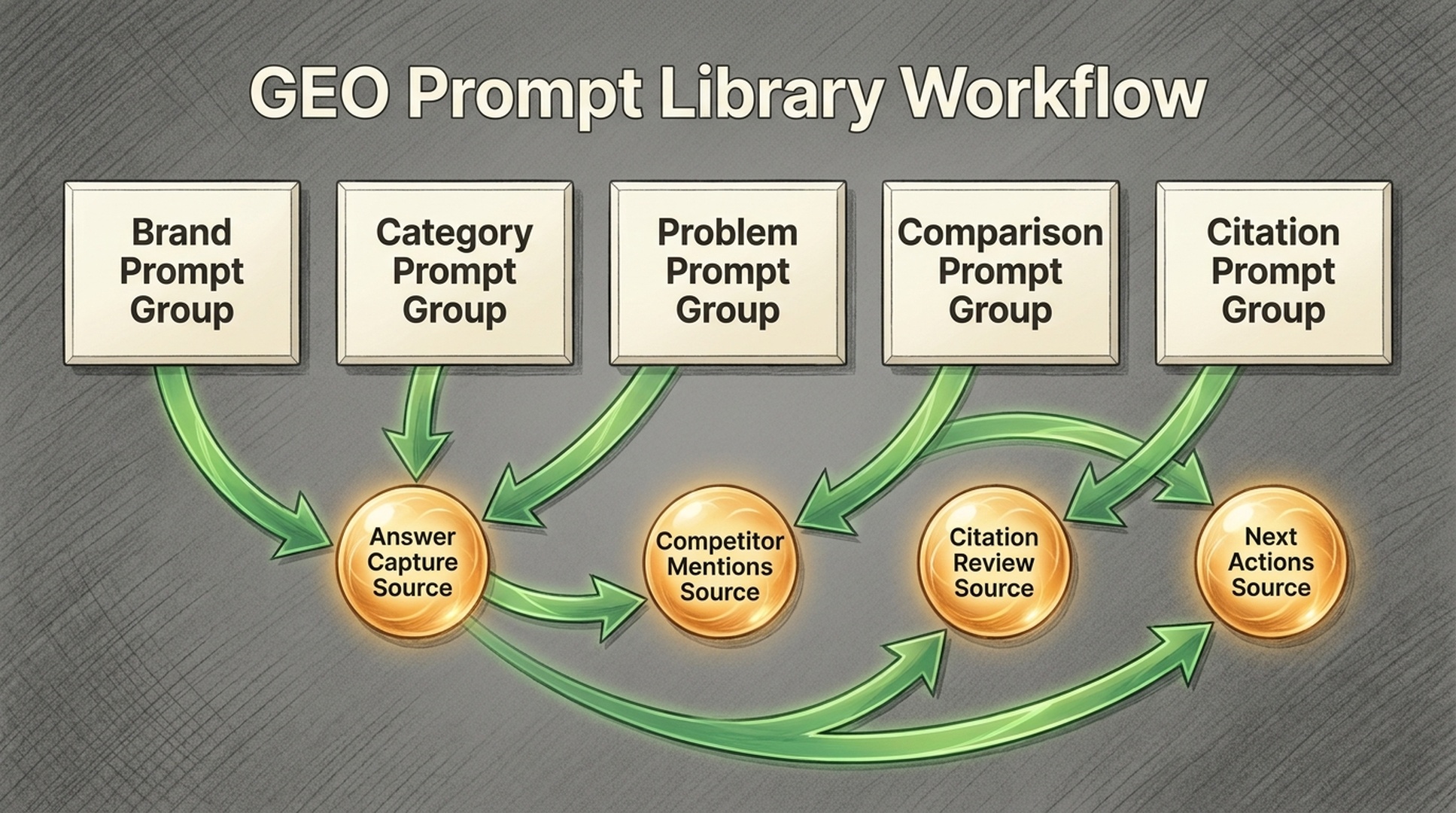
Scoring method
Use a simple score for each prompt.
| Score | Meaning |
|---|---|
| 0 | Your brand is not mentioned |
| 1 | Your brand appears weakly or only when named |
| 2 | Your brand appears as a relevant option |
| 3 | Your brand is recommended, compared, or cited with useful context |
Then tag the issue type:
| Issue type | When to use it |
|---|---|
| Entity gap | The system does not understand who you are |
| Category gap | You are missing from category prompts |
| Content gap | Your pages do not answer the prompt well |
| Evidence gap | Competitors have stronger third-party support |
| Citation gap | Your site is not cited when it should be |
| Accuracy gap | The answer describes you incorrectly |
The score tells you how visible you are. The issue type tells you what to fix.
Prompt group 1: brand understanding
Use these prompts to see whether ChatGPT understands your brand entity.
Replace [Brand] with your company name.
- What is
[Brand]? - What does
[Brand]do? - Who is
[Brand]for? - What category does
[Brand]belong to? - What problems does
[Brand]solve? - What are the main use cases for
[Brand]? - How is
[Brand]different from other tools in its category? - Is
[Brand]a software product, service, agency, marketplace, or content brand? - What type of customer should consider
[Brand]? - What should a buyer know before choosing
[Brand]?
What to look for:
| If the answer... | It likely means... |
|---|---|
| Does not know the brand | Entity footprint is weak |
| Uses an old description | Outdated sources are visible |
| Puts you in the wrong category | Positioning is inconsistent |
| Describes only generic benefits | Core pages lack specific facts |
| Gets the audience wrong | Use-case pages and profiles need cleanup |
Prompt group 2: category visibility
These prompts test whether your brand appears when the user does not mention you by name.
Replace [Category] with your market, such as AI search visibility tools, SOC 2 compliance software, project management software for agencies, or GEO platforms.
- What are the best tools for
[Category]? - Which
[Category]tools should a startup compare? - What are the top
[Category]platforms for small teams? - Which companies are known for
[Category]? - What are the leading options in
[Category]? - What should I look for when choosing a
[Category]tool? - Which
[Category]tools are best for teams with limited budget? - Which
[Category]tools are best for enterprise teams? - What are the most important features in a
[Category]solution? - What are common mistakes when choosing a
[Category]vendor?
What to look for:
| If competitors appear but you do not | Check category pages, comparison assets, and third-party evidence | | If no brands appear | The prompt may be too broad or the category language may be wrong | | If your brand appears in the wrong context | Fix audience and use-case positioning |
Prompt group 3: problem and use-case prompts
These prompts test whether your brand is connected to real buyer problems.
Replace [Problem], [Audience], and [Use Case] with your actual context.
- How can
[Audience]solve[Problem]? - What tools help with
[Problem]? - What is the best way to handle
[Use Case]? - Which tools help
[Audience]with[Use Case]? - How should a small team approach
[Problem]? - What should a company do if it struggles with
[Problem]? - What software helps teams measure or improve
[Use Case]? - What are the best practices for
[Use Case]? - What should I compare before buying a tool for
[Problem]? - Which vendors are worth considering for
[Use Case]?
What to look for:
Problem prompts often reveal content gaps. If your brand appears in category prompts but not problem prompts, you may need stronger use-case pages, workflows, examples, and case studies.
Prompt group 4: comparison prompts
These prompts test competitive framing.
Replace [Competitor] with the companies that appear most often in AI answers.
[Brand]vs[Competitor]: which is better for[Use Case]?- How does
[Brand]compare with[Competitor]? - What are the main differences between
[Brand]and[Competitor]? - Who should choose
[Brand]instead of[Competitor]? - Who should choose
[Competitor]instead of[Brand]? - What are the best alternatives to
[Competitor]? - What are the best alternatives to
[Brand]? - Is
[Brand]a good alternative to[Competitor]? - Which tool is better for
[Audience]:[Brand]or[Competitor]? - What are the risks of choosing
[Brand]vs[Competitor]?
What to look for:
| Pattern | What it means |
|---|---|
| Competitor is explained in detail, your brand is vague | Your comparison and product pages need more specifics |
| Answer chooses competitor by default | Evidence gap or market association gap |
| Answer is wrong about your features | Source cleanup needed |
| Answer cannot compare | You may need clearer alternatives and buyer criteria pages |
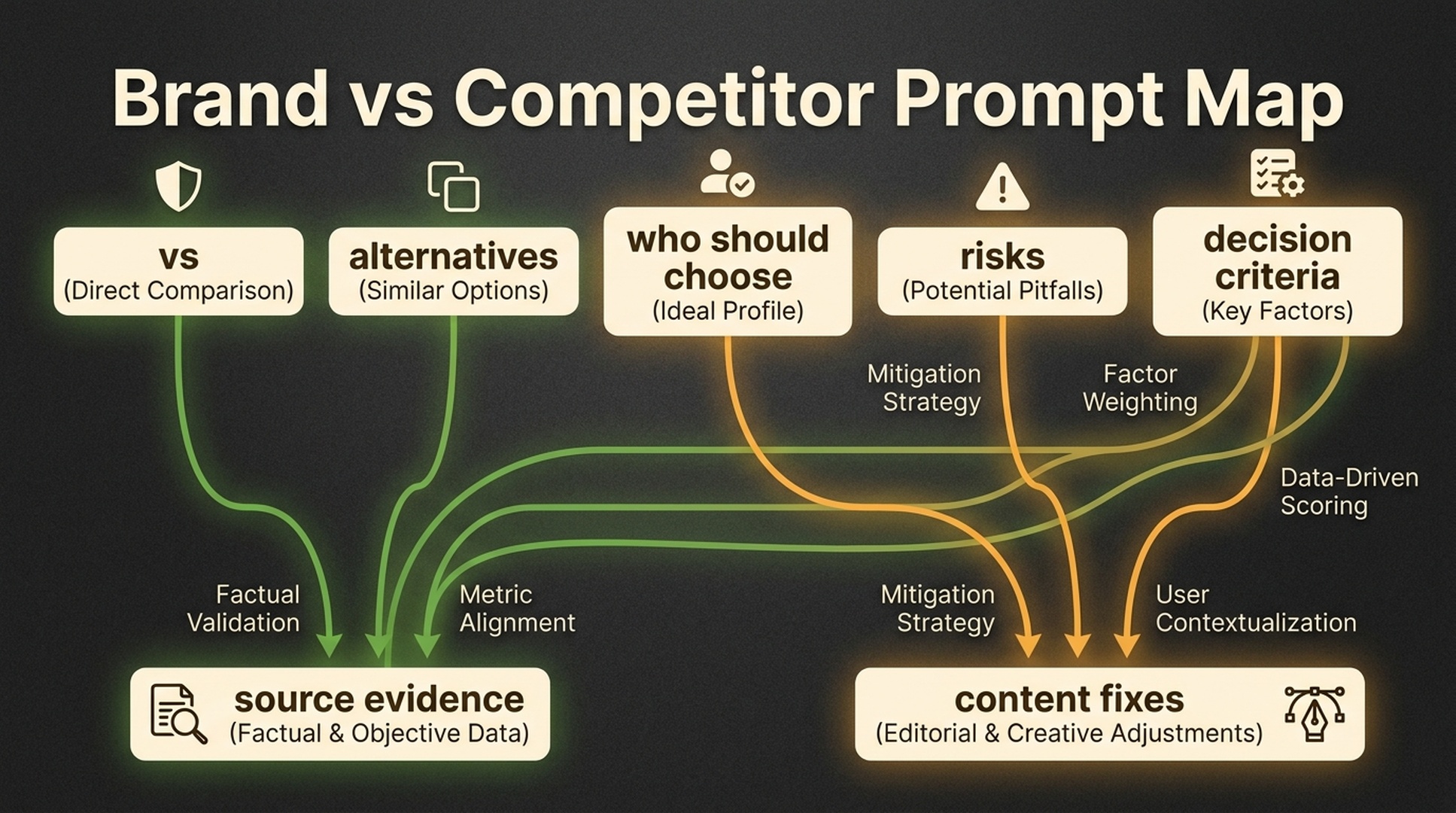
Prompt group 5: citation and source prompts
These prompts help you see which sources AI systems trust.
They work best in AI search tools that show citations, such as Perplexity or ChatGPT modes with browsing/citations.
- What sources explain
[Category]best? - Which websites should I read to understand
[Problem]? - What are reliable sources for comparing
[Category]tools? - Which pages explain
[Brand]clearly? - What sources mention
[Brand]and[Competitor]? - Find sources that compare
[Brand]with alternatives. - What evidence supports
[Brand]as an option for[Use Case]? - Which review sites include
[Brand]? - What third-party pages mention
[Brand]? - Which sources would help me evaluate
[Category]vendors?
What to look for:
- Is your own site cited?
- Are competitors' sites cited?
- Are review sites or directories cited?
- Are old or incorrect sources cited?
- Are important pages missing from the source set?
Source prompts are especially useful for deciding whether you need content fixes, technical fixes, or third-party evidence.
Optional prompt group 6: local, industry, or persona prompts
If your market depends on location, industry, or buyer type, add another 10 prompts.
Examples:
- What
[Category]tools are best for healthcare teams? - What
[Category]tools are best for agencies? - What
[Category]tools are best for ecommerce brands? - What vendors should a company in
[Region]compare for[Use Case]? - What is the best
[Category]option for a founder-led startup? - What should a technical buyer look for in
[Category]? - What should a CFO ask before buying
[Category]software? - What is the best lightweight option for
[Use Case]? - What is the best enterprise option for
[Use Case]? - Which vendors are strongest for
[Industry]teams with[Constraint]?
These prompts are useful because AI recommendations often change when the audience changes.
A brand that is not recommended for "best CRM" may be recommended for "best CRM for small nonprofit teams."
How to turn prompt results into content work
Do not stop at scoring.
Map each failed prompt to a fix.
| Prompt failure | Likely fix |
|---|---|
| Brand not recognized | Improve About page, schema, profiles, and entity consistency |
| Missing from category prompts | Build category page and third-party category evidence |
| Missing from problem prompts | Publish use-case pages and workflows |
| Weak in comparisons | Build comparison and alternatives pages |
| Not cited | Improve extractability and source quality |
| Described incorrectly | Clean up outdated sources and brand facts |
| Competitors dominate | Map competitor evidence and close the strongest gaps |
This turns prompt research into a content roadmap.
Reporting template
Use this table for a simple monthly report.
| Prompt group | Prompts tested | Mention rate | Citation rate | Top competitors | Main issue | Next action |
|---|---|---|---|---|---|---|
| Brand | 10 | |||||
| Category | 10 | |||||
| Problem | 10 | |||||
| Comparison | 10 | |||||
| Citation/source | 10 |
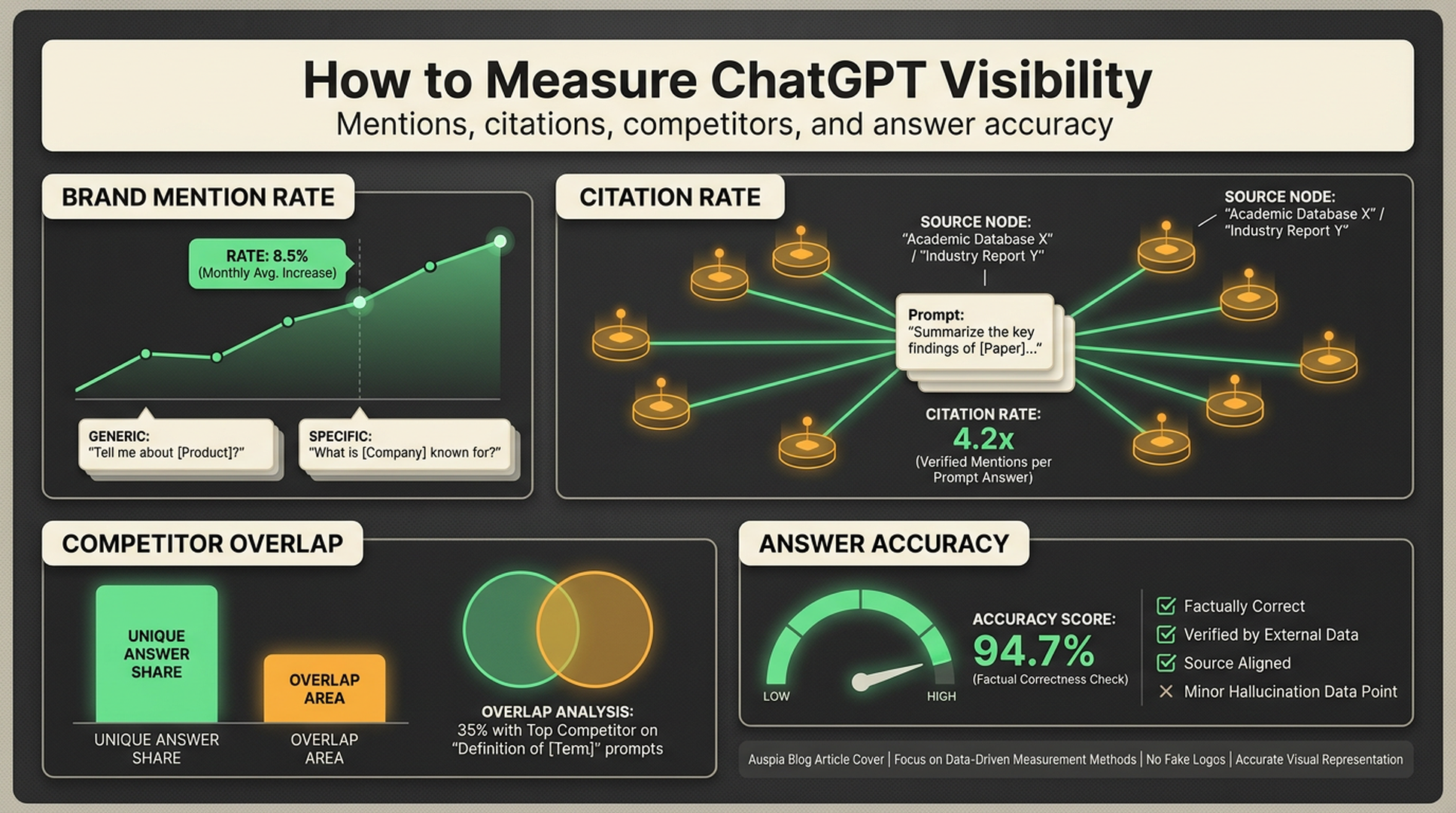
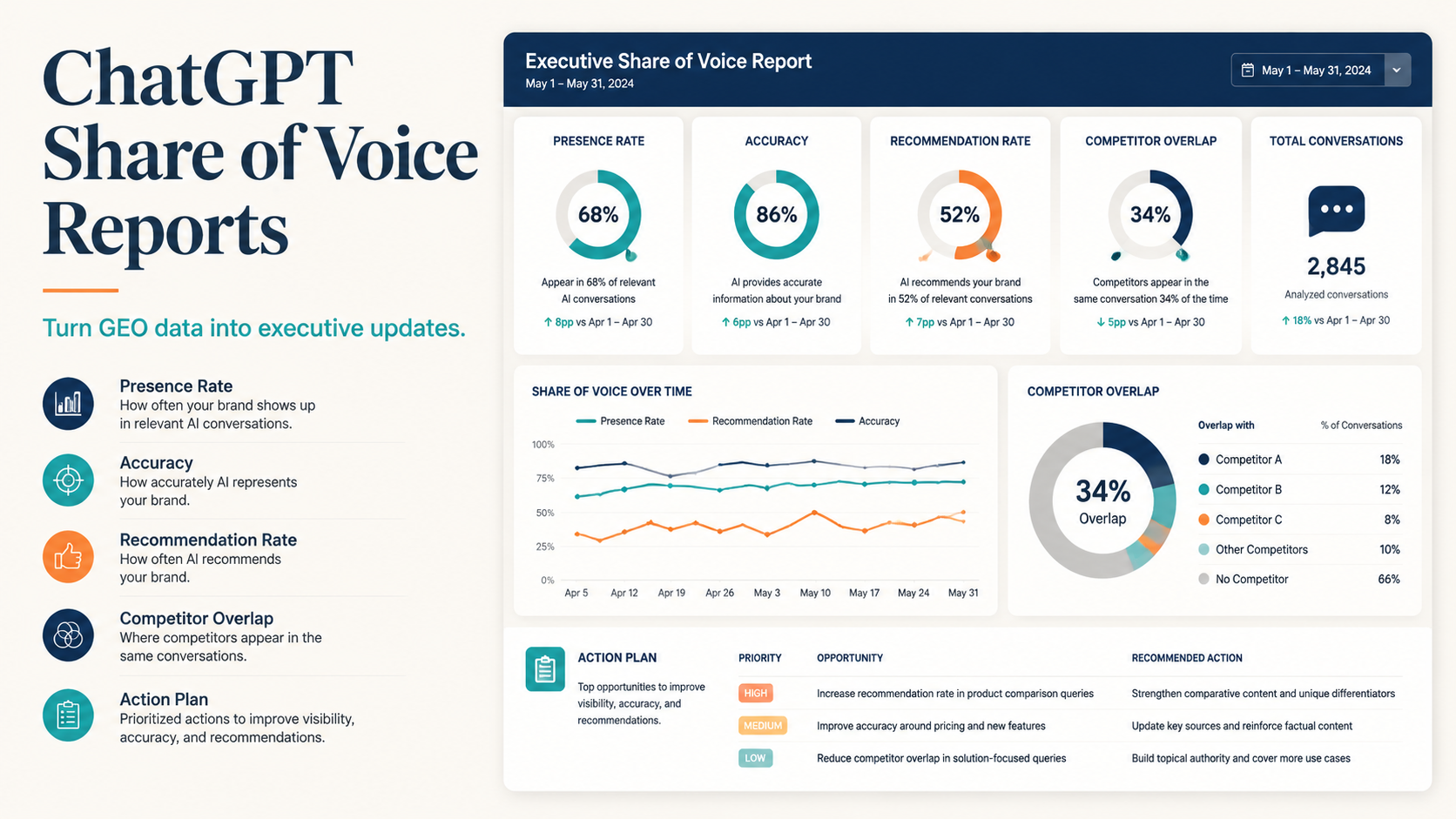
If you need the measurement method behind this report, read: How to Measure ChatGPT Visibility .
Common mistakes
| Mistake | Better approach |
|---|---|
| Only testing brand-name prompts | Include category, problem, comparison, and buyer prompts |
| Changing prompts every report | Keep a stable core set and add optional tests separately |
| Treating one answer as truth | Track patterns across prompts and platforms |
| Ignoring competitor mentions | Competitor overlap shows where the market is being defined |
| Ignoring source citations | Sources tell you what content or evidence to improve |
| Using prompts that no buyer would ask | Write prompts in natural buyer language |
| Measuring without assigning fixes | Connect each gap to entity, content, evidence, or technical work |
Auspia take
A prompt library is the bridge between GEO strategy and actual content work.
Without prompts, teams argue about vague AI visibility. With prompts, the gaps become concrete:
- This category prompt excludes us.
- This comparison prompt describes us incorrectly.
- This buyer prompt recommends three competitors.
- This source prompt cites a directory but not our product page.
- This problem prompt proves we need a use-case page.
That is useful. It tells the content team what to build next.
FAQ
What is a GEO prompt library?
A GEO prompt library is a repeatable set of AI prompts used to measure whether a brand appears in AI-generated answers for brand, category, problem, comparison, buyer, and citation queries.
How many ChatGPT prompts should we test?
Start with 50 prompts if you can. If that feels heavy, start with 25: five brand prompts, five category prompts, five problem prompts, five comparison prompts, and five buyer prompts.
Should we use the same prompts every month?
Yes. Keep a stable core prompt set so you can compare results over time. Add experimental prompts separately when new products, competitors, or buyer questions appear.
Should prompts mention our brand name?
Some should, but not all. Brand prompts test entity understanding. Category, problem, comparison, and buyer prompts test whether your brand appears when users do not already know you.
Which platforms should we test?
Start with the platforms your buyers are likely to use. For many B2B teams, that means ChatGPT, Perplexity, Gemini, and Google AI Overviews when available for the query.
What should we do when competitors appear but we do not?
Check whether competitors have clearer category pages, stronger third-party evidence, better comparison assets, or more extractable content. Then map the gap to a content or evidence fix.
Author: Elena Shaw, Prompt Library Strategist, 3,000+ Buyer Prompts Mapped at Auspia. Elena writes about prompt sets, query maps, evaluation libraries, and how teams translate buyer questions into GEO execution.