The measurement problem
Most teams measure SEO with rankings, clicks, impressions, and traffic.
That is not enough for ChatGPT visibility.
A brand can lose visibility inside AI answers before organic traffic shows a clear decline. It can also appear in ChatGPT, Perplexity, or Gemini without receiving a direct click. The answer may mention the brand, summarize it, compare it with competitors, or cite a third-party source instead of your website.
So the core measurement question changes:
When buyers ask AI systems questions about our category, problem, competitors, or use cases, do we appear in the answer, and are we described correctly?
That is what ChatGPT visibility measurement is for.
What to measure
Start with seven metrics.
| Metric | What it tells you |
|---|---|
| Brand mention rate | How often your brand appears across a prompt set |
| Competitor mention rate | Which competitors appear instead of you |
| Citation rate | Whether your website or third-party sources are cited |
| Answer accuracy | Whether the AI system describes your brand correctly |
| Prompt coverage | Which buyer questions include or exclude your brand |
| Source mix | Which domains shape the answer |
| Sentiment or framing | Whether the answer positions your brand positively, neutrally, or with caveats |
Do not start with a giant dashboard. Start with a prompt library and a repeatable scoring method.
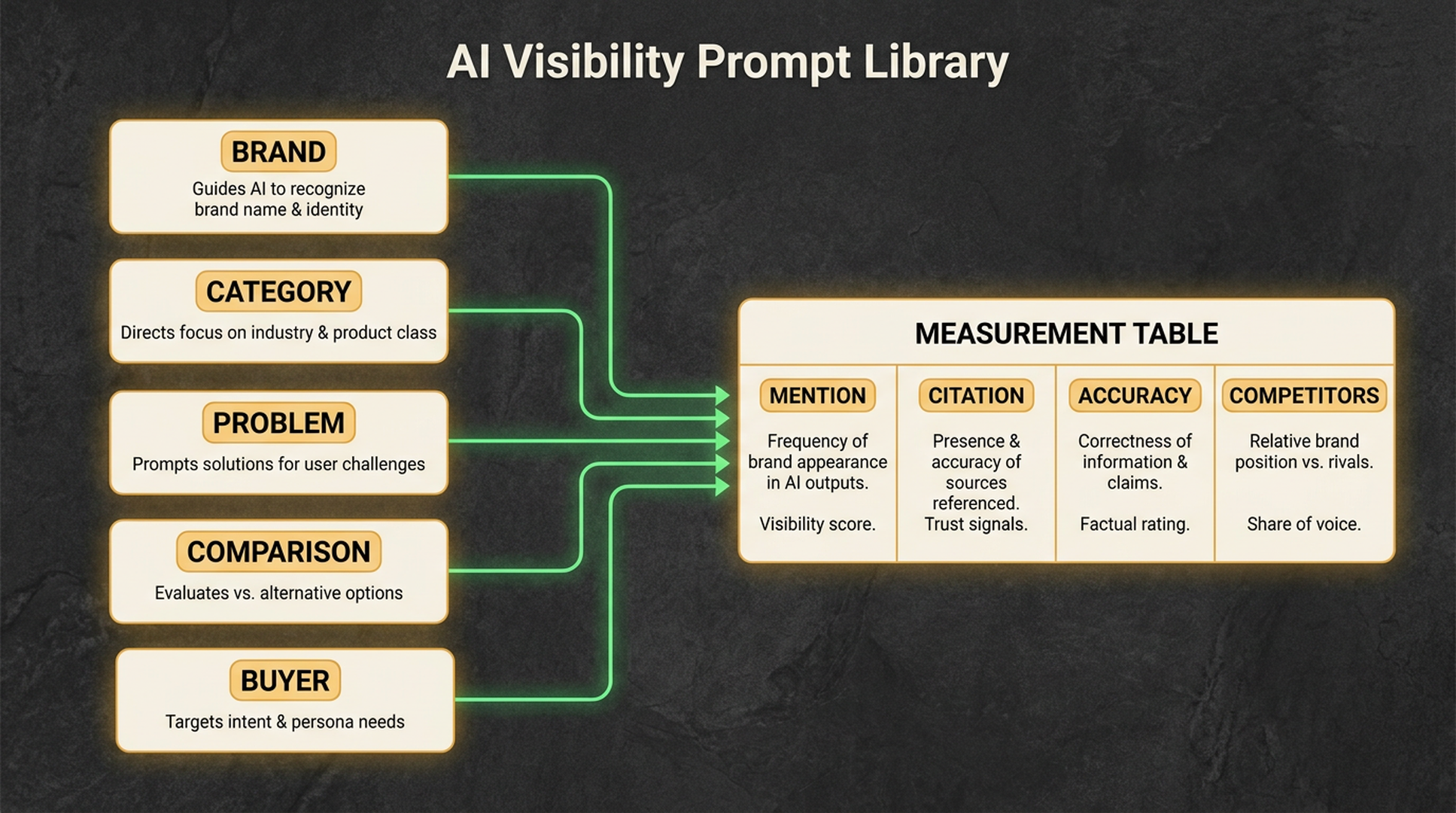
Build a prompt library first
A prompt library is the measurement unit for ChatGPT visibility.
It should cover the ways a buyer might use AI during research, comparison, and decision-making.
Use five prompt groups:
| Prompt group | Purpose | Example |
|---|---|---|
| Brand prompts | Check brand understanding | "What is [brand]?" |
| Category prompts | Check market inclusion | "What are the best tools for [category]?" |
| Problem prompts | Check solution relevance | "How can I solve [specific problem]?" |
| Comparison prompts | Check competitive framing | "[Brand] vs [competitor] for [use case]" |
| Buyer prompts | Check recommendation visibility | "Which [category] tool should a [specific team] choose?" |
Start with 25 prompts. Five per group is enough for a useful baseline.
A bigger prompt set can come later. If you start with 200 prompts, the team usually stops updating it.
Define the scoring rules
You need consistent scoring or every report becomes subjective.
Use this simple scale for each prompt:
| Score | Meaning |
|---|---|
| 0 | Brand is not mentioned |
| 1 | Brand is mentioned only after prompting by name or appears weakly |
| 2 | Brand is mentioned as a relevant option |
| 3 | Brand is recommended, compared, or cited with useful context |
Then add notes for:
- Competitors mentioned
- Sources cited
- Whether your own site was cited
- Whether third-party sources were cited
- Whether the description was accurate
- Whether the answer included outdated or wrong information
This gives you both a score and a diagnosis.
Track the answer, not just the outcome
Do not reduce the report to "appeared" or "did not appear."
The answer text matters.
For example, these three outcomes are very different:
| Outcome | Meaning |
|---|---|
| Your brand is listed with no explanation | Weak mention |
| Your brand is recommended for the wrong use case | Visibility exists, but positioning is wrong |
| Your brand is compared accurately with citations | Strong visibility |
Capture the answer text, citation URLs, model/platform, date, location, and prompt wording.
A good log includes:
| Field | Example |
|---|---|
| Date | 2026-06-29 |
| Platform | ChatGPT, Perplexity, Gemini, Google AI Overview |
| Prompt group | Comparison |
| Prompt | "Auspia vs [competitor] for AI search visibility tracking" |
| Brand mentioned | Yes |
| Score | 2 |
| Competitors mentioned | Competitor A, Competitor B |
| Citations | auspia.ai, review site, directory |
| Accuracy | Mostly correct |
| Notes | Missed GEO checklist feature |
This may look manual, but it is the fastest way to learn what is actually happening.
Measure source influence
AI answers are shaped by sources.
Some systems cite sources directly. Others do not. Either way, source quality matters.
Track which sources show up repeatedly:
| Source type | What it means |
|---|---|
| Your own website | Your pages are discoverable and useful enough to cite |
| Review sites | Buyer proof and category validation may matter |
| Directories | Basic entity and category data may be shaping the answer |
| Competitor pages | Competitors are defining the market language |
| Third-party articles | Independent comparisons or guides may influence recommendations |
| Documentation | Product facts and technical details are being used |
| Old pages | Outdated sources may be causing wrong answers |
If the same third-party comparison article appears often, study it. If your own pages never appear, your content may be less extractable or less trusted than other sources.
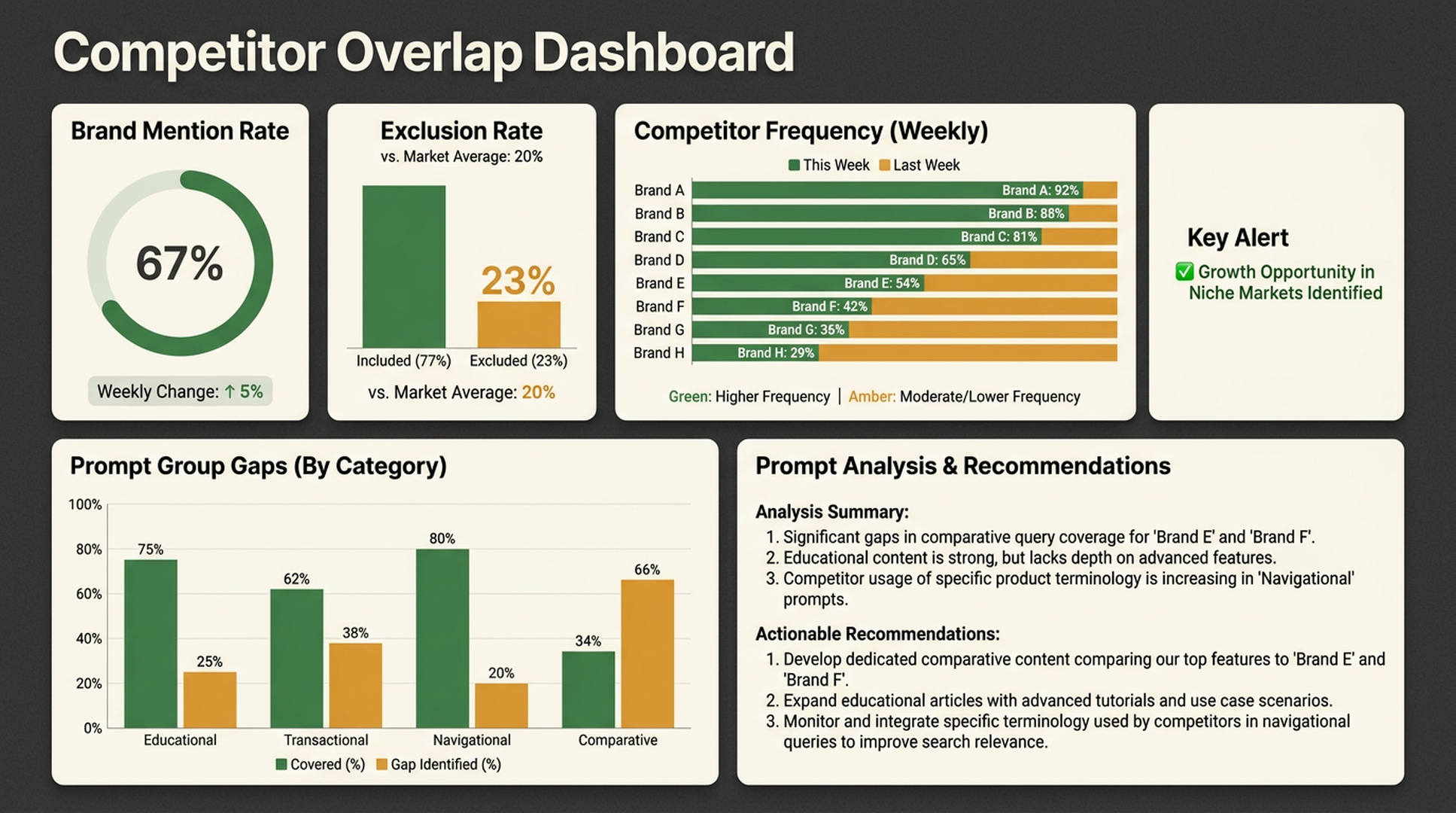
Watch competitor overlap
Competitor overlap is one of the most useful GEO metrics.
It tells you who owns the AI answer set.
For each prompt, record the brands mentioned. Then calculate:
| Metric | Formula |
|---|---|
| Your mention rate | Prompts mentioning your brand / total prompts |
| Competitor mention rate | Prompts mentioning each competitor / total prompts |
| Overlap rate | Prompts where your brand and competitor both appear / total prompts |
| Exclusion rate | Prompts where competitors appear but you do not / total prompts |
The exclusion rate is especially useful.
If competitors appear in 70% of buyer prompts and you appear in 10%, the problem is not just content quality. It is category association, evidence, and prompt coverage.
Check answer accuracy
Visibility is not always good.
If ChatGPT mentions your brand but describes it incorrectly, you have a different problem.
Track accuracy in four levels:
| Level | Meaning |
|---|---|
| Accurate | Description matches current positioning and product facts |
| Mostly accurate | Minor gaps, but no harmful errors |
| Partly wrong | Important use case, audience, feature, or category is wrong |
| Harmful | The answer misrepresents the brand in a way that could hurt trust |
Common accuracy problems:
- Old product positioning
- Wrong category
- Discontinued features
- Missing current use cases
- Confused pricing model
- Wrong audience
- Competitor comparison based on outdated data
When accuracy is weak, do not just publish more content. Clean up source facts.
Segment by prompt intent
A single average visibility score hides the real problem.
Segment performance by prompt group:
| Prompt group | What poor performance means |
|---|---|
| Brand prompts | Entity clarity is weak or outdated |
| Category prompts | Category association is weak |
| Problem prompts | Use-case content is missing |
| Comparison prompts | Competitive positioning is weak |
| Buyer prompts | Evidence and recommendation readiness are weak |
This helps choose the next action.
If brand prompts are strong but category prompts are weak, your brand is known but not associated with the market. If comparison prompts are weak, you may need better alternatives pages, decision criteria, or third-party evidence.
Build a simple reporting table
Start with a table like this:
| Prompt group | Prompts tested | Brand mention rate | Citation rate | Top competitor | Accuracy notes | Next action |
|---|---|---|---|---|---|---|
| Brand | 5 | 80% | 40% | n/a | Mostly accurate | Fix missing product facts |
| Category | 5 | 20% | 0% | Competitor A | Weak category association | Build category page |
| Problem | 5 | 40% | 20% | Competitor B | Good when mentioned | Add use-case examples |
| Comparison | 5 | 20% | 0% | Competitor A | Incomplete | Publish comparison page |
| Buyer | 5 | 0% | 0% | Competitor C | Not included | Build evidence and reviews |
This table is more useful than a vanity AI visibility score because it points to the work.
How often to measure
Do not measure every day unless you are running a controlled experiment.
AI answers vary. Daily checks can create noise and panic.
Use this cadence:
| Team stage | Cadence |
|---|---|
| New GEO program | Baseline, then every 2 weeks during active fixes |
| Stable program | Monthly prompt tracking |
| Major site update | Before and 2-4 weeks after launch |
| Reputation issue | Weekly until source corrections stabilize |
| Executive reporting | Monthly or quarterly summary |
The key is consistency. Use the same prompt wording, same platforms, and same scoring rules unless there is a reason to change them.
Common measurement mistakes
| Mistake | Better approach |
|---|---|
| Testing one prompt once | Track a prompt set over time |
| Only checking brand-name prompts | Include category, problem, comparison, and buyer prompts |
| Ignoring citations | Track which sources shape answers |
| Treating all mentions as equal | Score weak mentions separately from recommendations |
| Averaging everything | Segment by prompt intent |
| Ignoring wrong answers | Track accuracy and source cleanup needs |
| Measuring without action | Tie each finding to content, evidence, or technical fixes |
The goal of measurement is not to prove that GEO is working. It is to decide what to fix next.
A 30-day measurement workflow
Use this if you are starting from zero.
| Week | Work | Output |
|---|---|---|
| Week 1 | Build prompt library and run baseline | 25 prompts, scores, answer notes, source list |
| Week 2 | Analyze gaps | Competitor overlap, prompt group weaknesses, accuracy issues |
| Week 3 | Fix top two issues | Entity cleanup, page rewrite, comparison page, evidence update |
| Week 4 | Rerun priority prompts | Before/after report and next sprint plan |
Keep the first report simple. The team should be able to read it in five minutes and know what to do next.
Auspia take
ChatGPT visibility measurement should feel less like rank tracking and more like market research.
You are not only asking, "Did we rank?"
You are asking:
- Does the AI system understand us?
- Does it place us in the right category?
- Does it mention competitors instead?
- Which sources does it trust?
- Are we described accurately?
- Which buyer prompts exclude us?
- What should we fix next?
That is why a prompt library is more useful than a single screenshot.
If you need a starting audit before building a dashboard, use the companion checklist: The ChatGPT Visibility Checklist for Content Teams .
FAQ
What is ChatGPT visibility?
ChatGPT visibility is the degree to which a brand, product, website, or content asset appears in ChatGPT answers for relevant prompts. It can include mentions, recommendations, comparisons, summaries, and citations.
How do you measure ChatGPT visibility?
Build a prompt library, run the same prompts on a schedule, and track brand mentions, competitor mentions, citation rate, answer accuracy, source mix, and prompt coverage.
Is ChatGPT visibility the same as SEO ranking?
No. SEO ranking measures where pages appear in search results. ChatGPT visibility measures whether a brand or source appears inside generated answers.
How many prompts should a team track?
Start with 25 prompts across brand, category, problem, comparison, and buyer intent. Expand once the process is repeatable.
How often should we check ChatGPT visibility?
For an active GEO sprint, every two weeks is usually enough. For ongoing reporting, monthly is more practical. Daily checks often create noise.
What should we do if ChatGPT describes our brand incorrectly?
Create a brand facts inventory, update owned sources first, correct key third-party profiles, and improve pages that explain your category, product, audience, and use cases.
Author: Ethan Marlowe, GEO Measurement Lead Across 500+ Prompts at Auspia. Ethan writes about prompt tracking, citation reporting, visibility dashboards, and AI answer quality checks.