Executive Summary
Most GEO programs fail at the measurement layer before they fail at the execution layer.
A brand may pay for Generative Engine Optimization, receive a few screenshots from ChatGPT or Perplexity, and still not know whether the work is creating value. The old SEO habit of checking rankings and traffic is not enough, because AI answer systems do not behave like a simple list of blue links.
A practical GEO measurement system needs four layers:
- Mention Rate: Does the AI system recognize and mention your brand in the right buyer scenarios?
- Sentiment and Accuracy: When it mentions you, does it describe you positively and correctly?
- Answer Position Stability: Can you keep appearing in useful answer positions over time?
- Business Impact: Does AI visibility create branded search, direct traffic, leads, pipeline, or sales?
The core idea is simple: GEO is not validated by one screenshot. It is validated by a repeatable measurement loop.
If your team is investing in AI search optimization, this article gives you a framework to judge whether the work is actually improving visibility, trust, and revenue potential.
Why GEO Measurement Is Different From SEO Measurement
Traditional SEO measurement is mostly linear.
A simplified SEO path looks like this:
Higher ranking -> more impressions -> more clicks -> more conversions.
The path is not perfect, but it is trackable. Search Console, analytics platforms, rank trackers, and conversion tools can help connect keyword visibility to user behavior.
GEO is different because the user may never click a search result. The answer engine may synthesize multiple sources, summarize a recommendation, compare vendors, cite a publication, or mention a brand without sending traffic immediately.
In AI search, the path often looks more like this:
User asks a question -> AI retrieves and reasons over sources -> AI forms an answer -> brand is mentioned, omitted, or described -> user searches the brand later, visits directly, or asks a follow-up question.
That makes GEO measurement more networked than linear.
You are not only asking, "Did we rank?" You are asking:
- Does the AI system know we exist?
- Does it understand what we do?
- Does it connect us to the right use cases?
- Does it recommend us against relevant alternatives?
- Does it describe our positioning accurately?
- Does that visibility influence real demand?
This is why a single AI screenshot is weak proof. AI answers vary by platform, prompt, location, time, model behavior, search mode, and available sources. A serious GEO program needs a test set, a cadence, and a scorecard.
The Four-Layer GEO Measurement Framework
The simplest way to evaluate GEO is to move from visibility to trust to durability to business impact.
| Layer | Core Question | What It Measures | Why It Matters |
|---|---|---|---|
| Mention Rate | Does AI know us? | Brand appearance across target prompts | Establishes baseline visibility |
| Sentiment and Accuracy | Does AI describe us well? | Positive, neutral, negative, or incorrect descriptions | Protects trust and buyer perception |
| Position Stability | Can we keep the position? | Recurring appearance and answer placement over time | Separates temporary wins from durable authority |
| Business Impact | Does it create value? | Branded search, direct traffic, leads, pipeline, sales | Connects GEO to growth outcomes |
This framework works because it prevents teams from stopping too early. A brand can appear often but be described poorly. It can be described well once but disappear the next week. It can show strong visibility but fail to create business value.
Good GEO measurement looks at the whole chain.
Layer 1: Mention Rate
Mention Rate answers the first question: does the AI system recognize your brand in the scenarios that matter?
It is the percentage of target prompts where your brand, product, executive, content, or owned source appears in the AI answer.
For example, a B2B analytics company might test prompts such as:
- "Best product analytics tools for PLG SaaS teams"
- "How should a startup measure feature adoption?"
- "Amplitude vs Mixpanel vs Heap alternatives"
- "Tools for tracking user activation and retention"
- "What analytics stack should a Series A SaaS company use?"
If the brand appears in 18 of 60 target prompts, its Mention Rate is 30% for that test set.
Mention Rate is not the final goal, but it is the entry gate. If an AI system rarely mentions you in core buyer scenarios, your brand is not yet part of its answer universe.
A practical way to segment prompts is:
| Prompt Type | Example | Why It Matters |
|---|---|---|
| Category prompts | "best AI search visibility tools" | Tests whether you are recognized in the market |
| Problem prompts | "how to measure brand visibility in ChatGPT" | Tests use-case association |
| Comparison prompts | "Auspia alternatives for GEO audits" | Tests competitive inclusion |
| Brand prompts | "what does Auspia do?" | Tests entity understanding |
| Buying prompts | "which tool should a marketing team use for AI search optimization?" | Tests commercial recommendation potential |
Do not only test obvious brand prompts. A brand prompt tells you whether AI can summarize you after being given your name. Category and problem prompts tell you whether AI considers you before the user knows you.
Auspia's recommendation: start with 40-100 prompts across one market, one language, and three to five AI surfaces. Use the same test set consistently before expanding.
Layer 2: Sentiment and Accuracy
Appearing in an AI answer is not automatically good.
An answer engine can mention your brand as a weak option, describe your pricing incorrectly, associate you with an outdated product, or recommend a competitor while using your content as background.
That is why the second layer measures sentiment and accuracy.
For each mention, classify the answer into one of four buckets:
| Classification | Meaning | Example Signal |
|---|---|---|
| Positive and accurate | AI recommends or clearly validates the brand | "A strong option for teams that need..." |
| Neutral but accurate | AI mentions the brand without strong endorsement | "Other tools include..." |
| Negative or risky | AI highlights limitations or trust concerns | "Users report inconsistent..." |
| Incorrect or outdated | AI states wrong facts | Wrong feature, market, pricing, or category |
This layer matters because AI answers influence trust before a user reaches your website.
If the AI answer says you are a good fit for enterprise teams, but your actual product is built for small agencies, you have a positioning problem. If it says your tool lacks a feature you already launched, you have a source freshness problem. If it mentions unresolved complaints, you may have a reputation and third-party evidence problem.
Low sentiment or weak accuracy usually comes from one of four causes:
- Your website does not state the value proposition clearly enough.
- Third-party sources describe you inconsistently.
- Review sites, forums, or comparison pages contain stronger competitor signals.
- AI systems are reading old, incomplete, or low-authority information.
The fix depends on the cause. Do not respond to every negative AI answer by writing more blog posts. Sometimes the solution is product-page clarity. Sometimes it is documentation. Sometimes it is reviews, PR, partner pages, structured entity data, or correcting outdated third-party listings.
This is where GEO begins to overlap with brand, PR, content strategy, technical SEO, and reputation management.
Layer 3: Answer Position Stability
AI answers are unstable by design.
A brand may appear today and disappear next week because competitors publish stronger pages, a source gets updated, a model changes behavior, or the user prompt shifts slightly.
That is why GEO should measure answer position stability over time.
Position stability asks:
- Does the brand keep appearing across repeated tests?
- Does it appear in the first recommendation set or only near the end?
- Is it cited as a source or merely listed as an option?
- Does its position improve, decline, or fluctuate randomly?
- Is performance consistent across ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews?
A simple tracking format is enough at the beginning:
| Prompt | Platform | Week 1 | Week 2 | Week 3 | Week 4 | Notes |
|---|---|---|---|---|---|---|
| Best tools for AI search visibility | ChatGPT Search | Top 3 | Top 3 | Mentioned late | Top 3 | Competitor article entered answer |
| How to audit LLM visibility | Perplexity | Cited | Cited | Cited | Cited | Strong source match |
| GEO tools for agencies | Gemini | Not mentioned | Mentioned | Mentioned | Not mentioned | Needs stronger agency page |
You do not need perfect automation to start. You need consistent sampling.
For serious programs, test on a fixed schedule such as weekly or biweekly. Keep the prompt set stable for at least 8-12 weeks so you can see trends instead of noise.
Position stability is important because it separates a real authority signal from a lucky answer. A one-time appearance can happen by accident. Repeated inclusion across high-intent prompts suggests that AI systems are finding a stronger relationship between your brand, sources, and the buyer problem.
Layer 4: Business Impact
The last layer asks the question executives care about: did GEO create business value?
AI answer visibility is a means, not the end. A brand does not invest in GEO to collect screenshots. It invests because AI-assisted discovery is becoming part of the buyer journey.
Business impact can show up in several places:
- Growth in branded search volume.
- More direct traffic to key pages.
- More homepage visits after AI-search campaigns.
- Higher assisted conversions from organic and direct channels.
- More demo requests mentioning ChatGPT, Perplexity, Gemini, or AI search.
- More sales calls where prospects say they found the brand through an AI tool.
- More inclusion in third-party comparison and recommendation content.
Attribution will not be perfect. Many AI systems do not pass clean referral data. Some users read an AI answer, then search the brand later. Others ask for recommendations, copy a URL, or visit from another device.
That is why GEO attribution should use directional evidence rather than fake precision.
A useful quarterly review asks:
- Did Mention Rate improve across high-intent prompt groups?
- Did sentiment and accuracy improve in answers that mention us?
- Did our answer position become more stable?
- Did branded search, direct traffic, qualified leads, or sales conversations move in the same direction?
- Which content, source, or entity updates were made before the improvement?
The goal is not to claim that one AI mention created one sale. The goal is to understand whether the GEO system is strengthening demand signals over time.
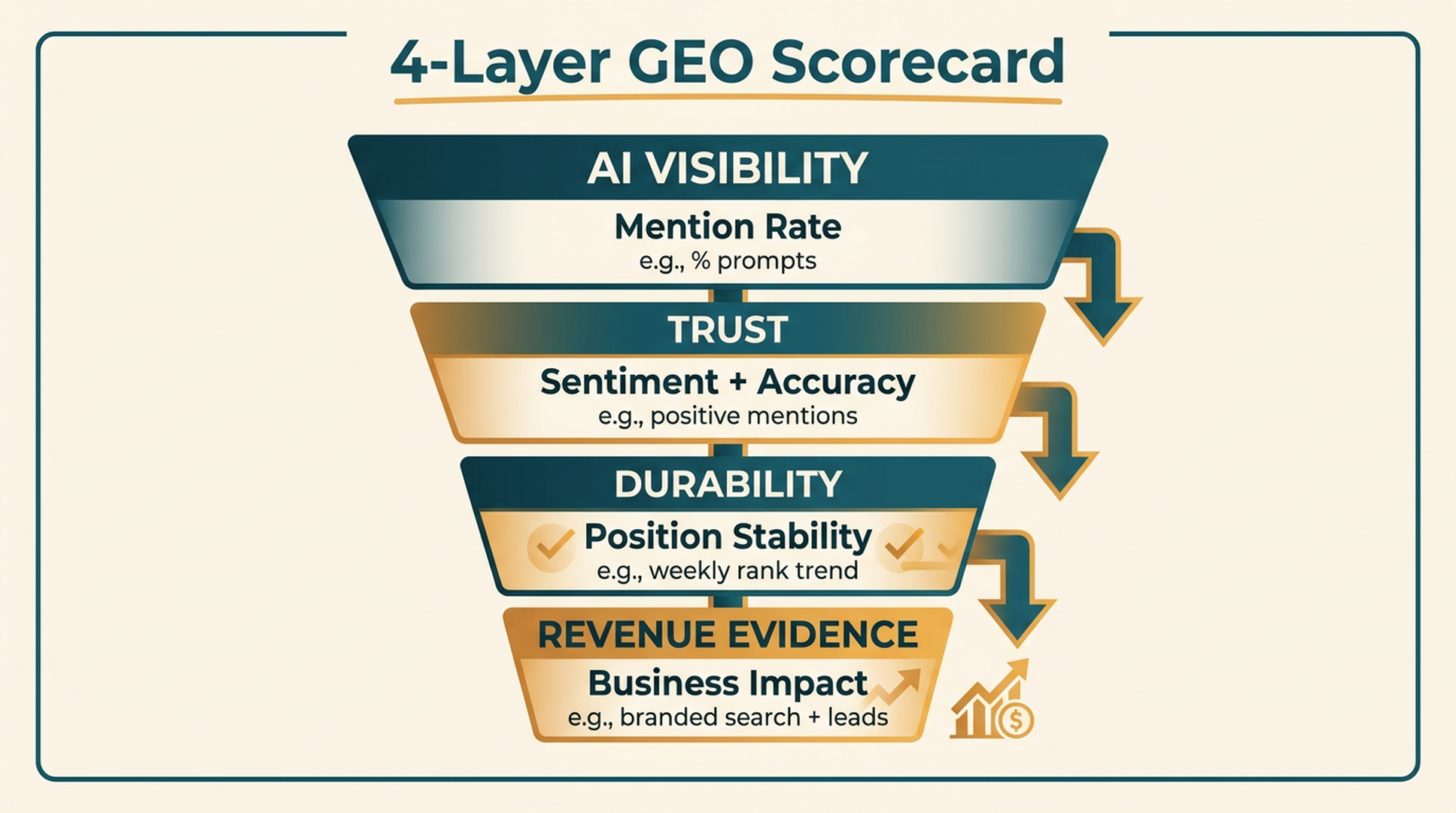
Use a layered GEO scorecard so your team can separate visibility, trust, durability, and business outcomes.
A Practical Three-Step GEO Measurement Process
Once the four layers are clear, the workflow becomes manageable.
Step 1: Build a Baseline Before Optimization
Before you publish new pages, rewrite content, or hire a GEO vendor, run a baseline test.
Create a prompt library with 40-100 prompts across:
- Category terms.
- Problem statements.
- Comparison prompts.
- Brand prompts.
- Commercial buying questions.
- Long-tail use cases.
Then test the prompts across the AI surfaces that matter for your audience. For a global B2B team, that may include ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews. For a local services business, the relevant surfaces may include Google AI Overviews, local search, reviews, and vertical directories.
Record Mention Rate, sentiment, accuracy, answer position, cited sources, and notes.
Without a baseline, your team cannot know whether a later improvement is meaningful.
Step 2: Monitor on a Fixed Cadence
GEO should be tracked as a trend, not as a screenshot collection.
A practical cadence:
- Weekly for strategic prompts and competitive terms.
- Biweekly for broader prompt groups.
- Monthly for executive reporting.
- Quarterly for business-impact review.
Keep the same prompts stable, but add a separate section for new prompts discovered from sales calls, customer support, keyword research, or AI-answer analysis.
The reporting format should show movement:
| Metric | Baseline | Current | Target | Action |
|---|---|---|---|---|
| Mention Rate | 22% | 41% | 60% | Build comparison and use-case pages |
| Positive Accuracy | 55% | 72% | 85% | Update product pages and third-party profiles |
| Stable Top Mentions | 8 prompts | 17 prompts | 30 prompts | Strengthen cited source coverage |
| Branded Search Lift | Flat | +12% | +25% | Connect GEO pages to campaigns |
This turns GEO from a vague optimization project into an operating rhythm.
Step 3: Connect Metrics to Content and Source Actions
Measurement without action is just reporting.
Each scorecard review should produce a prioritized action list:
- If Mention Rate is low, identify missing topic and category pages.
- If sentiment is weak, clarify positioning and fix third-party source gaps.
- If accuracy is poor, update entity data, documentation, profiles, and structured content.
- If stability is weak, build stronger source depth around the same buyer problem.
- If business impact is unclear, improve tracking, landing pages, forms, and sales-call intake fields.
Auspia's view: the best GEO teams do not separate measurement from execution. They treat measurement as the input for content strategy, source strategy, technical fixes, and conversion tracking. Teams can start with lightweight tools such as an AI Search Visibility Checker , then build a repeatable internal benchmark.
Common Mistakes When Evaluating GEO
Mistake 1: Accepting screenshots as proof
A screenshot only proves that one answer appeared once. It does not prove repeatability, accuracy, stability, or business impact.
Mistake 2: Testing only brand-name prompts
If you ask an AI system about your brand directly, it may summarize you reasonably well. That does not mean it recommends you when buyers ask category, problem, or comparison questions.
Mistake 3: Ignoring answer mode and source behavior
Some AI platforms behave differently when live web search is enabled. Others rely more heavily on citations, browsing, or model memory. Your test environment must match the real way buyers use the tool.
Mistake 4: Measuring too early
GEO often needs time. Content updates, third-party mentions, documentation changes, and entity signals may take weeks or months to influence AI answers. Use a 90-day window as a practical minimum for meaningful evaluation.
Mistake 5: Treating all mentions as equal
A brand mention in a low-intent educational answer is not the same as a positive recommendation in a high-intent comparison prompt. Weight prompts by buyer value.
Mistake 6: Optimizing for visibility while ignoring conversion
A brand can improve AI visibility and still lose the user if the landing page, offer, trust proof, or sales path is weak. GEO should connect to conversion strategy, not stop at visibility reporting.
The GEO Measurement Checklist
Use this checklist before you sign off on a GEO campaign or vendor report.
| Question | Yes / No |
|---|---|
| Do we have a fixed prompt library across category, problem, comparison, brand, and buying prompts? | |
| Do we track multiple AI surfaces instead of relying on one tool? | |
| Do we classify mentions by sentiment and accuracy? | |
| Do we record answer position and cited sources over time? | |
| Do we compare results against a baseline? | |
| Do we review data at least monthly? | |
| Do we connect GEO movement to branded search, direct traffic, leads, or sales notes? | |
| Do we turn scorecard findings into content, entity, source, and technical actions? |
If a GEO report cannot answer these questions, it is not an evaluation system. It is a presentation.
Auspia Takeaway
GEO performance should be measured like a trust-building system.
A useful formula is:
AI Search Momentum = Mention Rate x Sentiment Accuracy x Position Stability x Business Impact
This formula is not meant to be a perfect mathematical model. It is a reminder that GEO only becomes valuable when visibility, trust, durability, and business outcomes move together.
The brands that win in AI search will not be the ones that collect the most screenshots. They will be the ones that build a disciplined measurement loop, understand where AI systems trust them, and keep improving the sources that shape those answers.
If you are starting today, do not begin with a 30-page strategy deck. Begin with 50 buyer prompts, three AI platforms, one baseline scorecard, and a 90-day review window.
Then ask the question that matters:
When AI answers your buyers, does it understand you well enough to recommend you?
FAQ
How often should a team measure GEO performance?
Weekly or biweekly tracking works well for high-priority prompts. Monthly executive summaries and quarterly business-impact reviews are enough for most teams. The key is consistency, not constant manual checking.
What is a good Mention Rate for GEO?
It depends on the market and prompt set. For a new or under-optimized brand, 20-40% may be a realistic baseline. For core commercial prompts after optimization, teams should aim for steady improvement toward 60% or higher, while also tracking sentiment and stability.
Can GEO results be attributed directly to revenue?
Sometimes, but not perfectly. AI systems often influence discovery before users arrive through branded search, direct traffic, or sales conversations. Use directional signals such as branded search lift, direct traffic, lead quality, and customer self-reported discovery sources.
Which AI platforms should be included in a GEO benchmark?
Choose platforms based on buyer behavior. Many global B2B teams should test ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews. Local, ecommerce, or vertical markets may require additional surfaces such as review platforms, marketplaces, or industry directories.
Is GEO measurement the same as SEO measurement?
No. SEO measurement often focuses on rankings, impressions, clicks, and conversions. GEO measurement focuses on AI answer inclusion, sentiment, source citation, answer stability, and the downstream business signals created by AI-assisted discovery.