GEO in 2026: what actually needs to be done
GEO in 2026 is no longer a side project where someone rewrites a few blog posts for ChatGPT. It is a weekly operating system for making a brand easier for AI answer engines to understand, trust, compare, and cite.
The practical work has four parts:
- diagnose how AI systems describe your brand today;
- fix the technical and entity signals that help crawlers and retrieval systems read your site;
- publish evidence-rich pages that answer real buyer questions;
- measure brand mentions, citation quality, answer accuracy, and assisted traffic every week.
A useful GEO program still borrows from SEO. Clean pages, schema, internal links, topic coverage, and brand authority all matter. The difference is the output you optimize for. SEO tries to earn rankings and clicks. GEO tries to become part of the answer.
A 2026 team should treat that as a 16-week rollout, not a one-day content sprint.
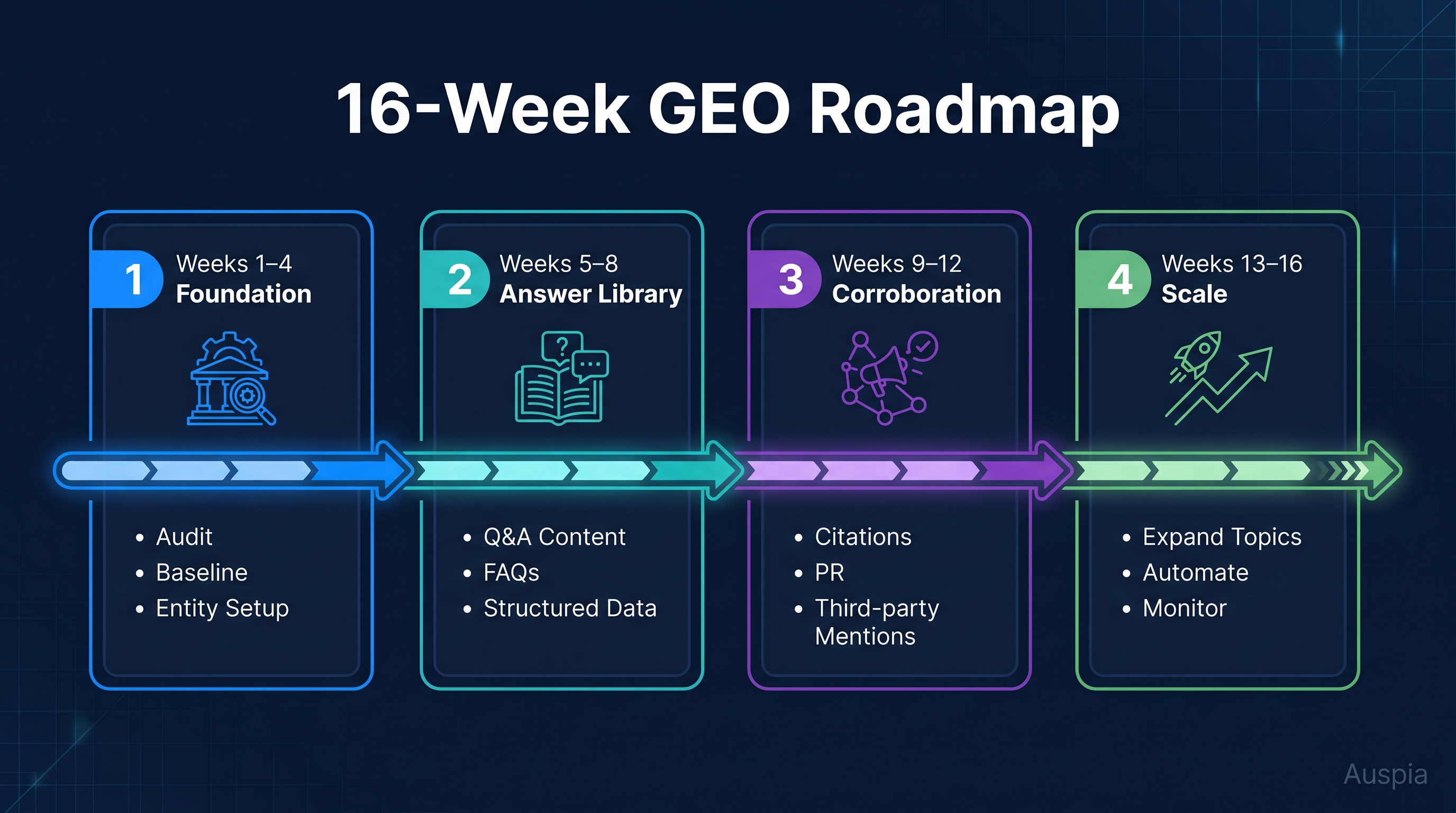
Caption: A 16-week GEO roadmap gives teams enough time to establish entity signals, publish useful evidence, and measure AI answer movement without guessing.
Why GEO became a real growth workflow in 2026
Search behavior has changed in a way most analytics dashboards still hide. Buyers ask longer questions inside ChatGPT, Perplexity, Gemini, Claude, Google AI Overviews, Bing Copilot, and vertical AI tools. Many of those sessions do not start with a blue-link results page. Some never produce a click at all.
That does not make websites irrelevant. It makes source quality more important.
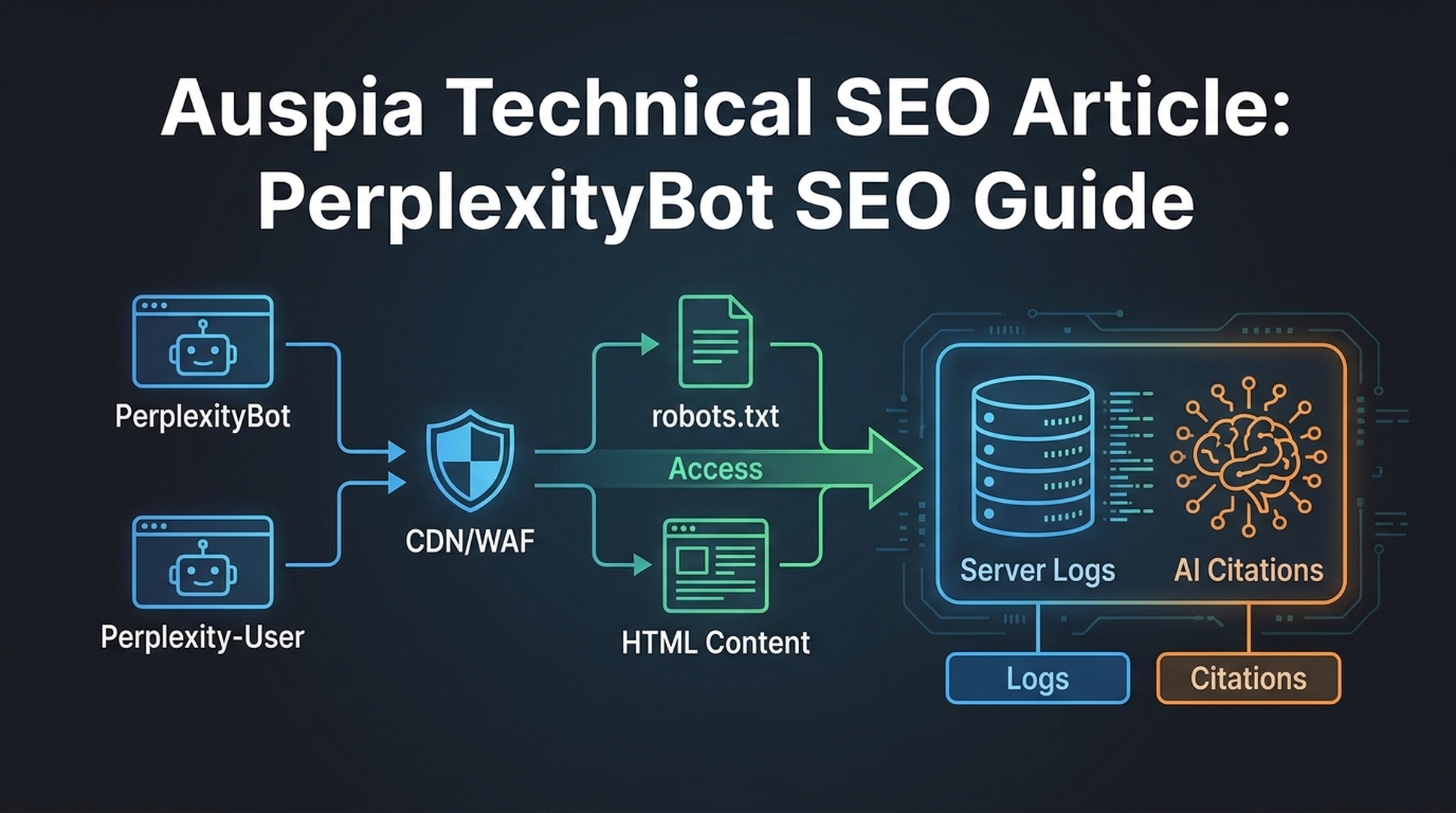
Google says publishers can control how content appears in AI-powered search features through the same preview controls used for Search, such as nosnippet, max-snippet, and noindex. OpenAI documents separate crawlers such as OAI-SearchBot for search-related surfacing and GPTBot for model training. The practical point is simple: AI visibility depends on whether your content can be crawled, understood, retrieved, and used safely in an answer.
GEO is the work of improving that chain.
The mistake is thinking it is only "write longer content." Length helps only when the page contains facts, comparisons, examples, constraints, and clear language that an answer system can extract. A 3,000-word article full of soft claims is less useful than a 900-word page with exact definitions, pricing context, use cases, schema, source links, and a clear comparison table.
GEO vs SEO: the 2026 version
GEO and SEO overlap, but they do not have the same finish line.
| Dimension | Traditional SEO | GEO in 2026 |
|---|---|---|
| Main goal | Rank pages and earn clicks | Get the brand, product, or source cited in AI answers |
| Primary surface | Google results, Bing results, vertical search | ChatGPT, Perplexity, Gemini, Google AI Overviews, Bing Copilot, Claude, industry assistants |
| Content unit | Page optimized around a query | Answer-ready asset tied to an entity, question, comparison, or workflow |
| Technical focus | Crawlability, indexability, schema, speed, internal links | Same foundations, plus AI crawler access, llms.txt, extractable summaries, clean entity facts |
| Evidence style | Backlinks, topical authority, engagement, content quality | Verifiable facts, source clarity, third-party mentions, structured answers, citation-friendly formatting |
| Measurement | Rankings, impressions, CTR, organic sessions | Share of answer, citation count, answer accuracy, prompt coverage, AI referral traffic, brand search lift |
| Operating rhythm | Monthly SEO review | Weekly prompt tests and answer-quality review |
That overlap matters. If your site is slow, blocked, thin, or confusing, AI systems will not magically fix that. GEO is better understood as SEO plus answer-readiness, not a replacement for SEO.
The six foundations every GEO project needs
Before planning content volume, make sure the brand can be recognized. Most weak GEO programs fail here. They publish more articles before the AI systems have a stable picture of who the company is.
1. A clean brand entity
AI answer engines need consistent facts. Your homepage, About page, product pages, social profiles, directory listings, author pages, and third-party mentions should agree on:
- brand name and spelling;
- category and market position;
- primary products or services;
- target customer;
- locations served, if relevant;
- proof points that are true and current;
- comparison language against alternatives.
If your site calls the product an "AI growth platform," your LinkedIn says "SEO agency," and your directory listings say "marketing software," answer engines have to choose. They may choose badly.
2. Crawlable technical foundations
Start with the boring checks because they decide whether anything else can work.
- Make sure important pages are indexable.
- Review
robots.txtfor accidental blocks against major search and AI-related crawlers. - Add or update XML sitemaps.
- Use Organization, WebSite, BreadcrumbList, Product, Service, Article, and FAQPage schema where appropriate.
- Add concise page summaries near the top of important pages.
- Build or update
llms.txtif it fits your site governance.
Auspia teams often start with the LLMs.txt Generator / Checker and the Robots.txt AI Crawler Checker because they expose basic access problems quickly.
3. Answer-ready content
AI-friendly content is not a special writing style. It is useful writing with less ambiguity.
A good GEO page usually has:
- a direct answer in the first 100-150 words;
- definitions written in plain language;
- tables for comparisons, criteria, and steps;
- named examples, not generic examples;
- data with source context;
- clear "who this is for" and "when not to use it" sections;
- FAQs that match real prompts;
- internal links to deeper pages.
The page should be easy for a person to skim and easy for a model to quote without inventing missing context.
4. Third-party evidence
Your own website is necessary, but it is not enough in many categories. AI systems often lean on sources that look independent: review sites, comparison pages, community answers, partner pages, documentation, public datasets, news coverage, and niche directories.
For a B2B SaaS company, this might mean G2, Capterra, GitHub, Stack Overflow, partner marketplaces, analyst blogs, integration pages, and category guides. For a local service brand, it might mean Google Business Profile, Yelp, local directories, city pages, trade associations, and local media.
The point is not spam distribution. The point is corroboration. If multiple credible places describe the brand in the same category, answer systems have a clearer pattern to retrieve.
5. A prompt library
You cannot measure GEO with five random prompts typed into ChatGPT. Build a prompt library that reflects how buyers ask.
Include:
- brand prompts: "What is [Brand]?";
- category prompts: "best tools for [job]";
- comparison prompts: "[Brand] vs [Competitor]";
- problem prompts: "how to solve [pain]";
- local or market prompts, if relevant;
- bottom-funnel prompts: "which [category] tool is best for [use case]?".
Keep the library stable for trend tracking, then add new prompts as customer language changes.
6. A measurement dashboard
A GEO dashboard should not pretend to be perfect. AI answers vary by user, location, model, browsing mode, and time. Still, a disciplined sample is better than anecdotes.
Track:
| Metric | What it tells you | Suggested cadence |
|---|---|---|
| Brand mention rate | Whether the brand appears in relevant answers | Weekly |
| Citation rate | Whether your pages or third-party sources are used | Weekly |
| Answer accuracy | Whether AI systems describe the brand correctly | Weekly |
| Share of answer | How often your brand appears against competitors | Weekly or biweekly |
| Citation quality | Whether citations point to strong, current pages | Monthly |
| AI referral traffic | Sessions from identifiable AI surfaces | Monthly |
| Assisted conversion | Whether AI-origin visitors convert or return later | Monthly |
| Brand search lift | Whether more people search the brand after AI exposure | Monthly |
Use the AI Search Visibility Checker for quick prompt checks, then move important queries into a repeatable reporting workflow.
A 16-week GEO implementation plan
The timeline below is realistic for a team that already has a website, a few content assets, and someone responsible for execution. A brand starting from zero may need longer. A mature SEO team may move faster.
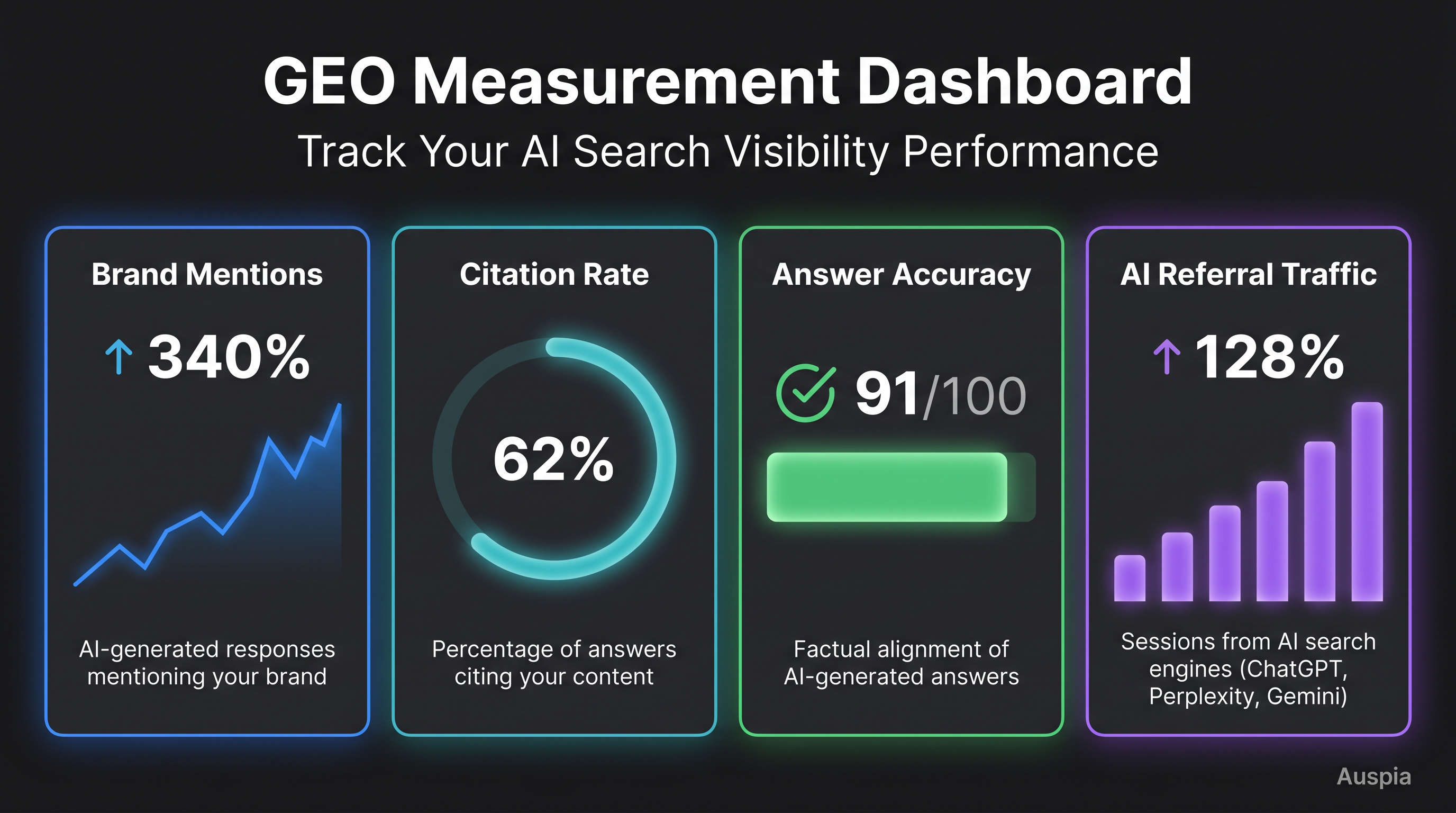
Caption: GEO measurement works best when prompt testing, citation review, and analytics are reviewed together instead of as separate reports.
Weeks 1-4: diagnose and build the foundation
The first month is for diagnosis and infrastructure. Resist the urge to publish 30 articles before you know the baseline.
| Week | Work | Deliverable |
|---|---|---|
| 1 | Test brand, category, comparison, and problem prompts across target AI platforms | AI visibility baseline report |
| 2 | Audit crawlability, schema, robots.txt, sitemap, page summaries, and entity consistency | Technical GEO checklist |
| 3 | Review competitors and map where they are cited | Competitor citation matrix |
| 4 | Choose target prompts, priority pages, owners, and review cadence | 90-day GEO roadmap |
For the baseline, record the raw answer, date, model or platform, whether browsing was enabled, citations shown, brand position, competitor names, and inaccurate statements. Screenshots help because AI answers change.
Weeks 5-8: create the core answer library
The second month is where content work begins. Focus on assets that answer buyer questions and fix entity confusion.
Start with these pages:
| Asset | Purpose | GEO notes |
|---|---|---|
| Homepage summary block | Clarify what the company does | Add a concise 2-3 sentence brand description |
| About page | Strengthen brand entity | Include founding context, category, locations, team context, and proof points that are safe to verify |
| Product or service pages | Explain offers clearly | Add use cases, constraints, comparison points, FAQs, and schema |
| Category guide | Explain the market problem | Define the category in neutral language and link to supporting pages |
| Comparison pages | Answer buyer evaluation prompts | Be fair, specific, and current |
| How-to articles | Capture problem prompts | Use step-by-step tables and examples |
| Evidence pages | Support trust | Publish case studies, benchmarks, templates, or original research where possible |
A good target for many teams is 8-15 strong assets in the first content cycle, not 50 thin posts. Each page should have a clear prompt target and a reason to exist.
Weeks 9-12: distribute and corroborate
The third month is about making the brand easier to corroborate outside its own site.
Possible actions:
- update business profiles and software directories;
- answer high-intent community questions without copying the blog post;
- publish partner or integration pages;
- pitch practical guest posts to relevant industry sites;
- turn original data into charts that others can reference;
- add author pages and editorial review notes where they improve trust;
- refresh outdated third-party descriptions of the brand.
Do not blast the same article everywhere. Rewrite for the platform. A LinkedIn post, a community answer, a directory profile, and a technical guide should not read like clones.
Weeks 13-16: validate, prune, and scale
By the fourth month, you should have enough data to make decisions.
Review:
- which prompts started mentioning the brand;
- which pages earned citations;
- which competitors still appear more often;
- which answers contain wrong facts;
- which content assets were ignored;
- whether AI-referred visitors behave differently from organic search visitors.
Then choose one of four actions for each asset:
| Signal | Action |
|---|---|
| Cited often and accurate | Keep fresh, add related internal links |
| Mentioned but not cited | Improve source clarity, add data, strengthen third-party corroboration |
| Cited but answer is wrong | Rewrite summary, fix schema, update brand facts, request third-party corrections where possible |
| Never appears | Recheck intent, consolidate with a stronger page, or retire |
This is the point where GEO becomes routine. The teams that improve keep a weekly loop. The teams that stall treat the first content batch as the finish line.
What results should you expect?
GEO results are uneven. Anyone promising guaranteed AI citations in a fixed number of days is selling certainty they do not have.
A more honest expectation looks like this:
| Timeframe | What may improve | What usually remains uncertain |
|---|---|---|
| First 4 weeks | Better crawl access, cleaner entity facts, baseline measurement | Brand mentions may not change yet |
| 5-8 weeks | More answer-ready assets, early citations on narrow prompts | Broad category prompts may still favor bigger brands |
| 9-12 weeks | Improved mention rate on long-tail and comparison prompts | Citation consistency varies by platform |
| 13-16 weeks | Clearer view of which assets work, better answer accuracy | Some platforms may not expose citations or referral data cleanly |
| 3-6 months | Stronger share of answer if publishing and corroboration continue | Competitive categories may need ongoing authority building |
For a new or mid-market brand, the first visible wins often come from narrow prompts: "best [category] tool for [specific use case]," "alternatives to [competitor] for [audience]," or "how to solve [specific problem]." Broad prompts like "best CRM" or "top SEO tools" are much harder.
Use directional targets, not guarantees:
- 20-40% more accurate brand descriptions across your tracked prompt set;
- first citations from owned pages on narrow use-case prompts;
- higher mention rate in comparison and problem prompts;
- measurable AI referral sessions where platforms pass referrers;
- stronger branded search after consistent exposure.
Common GEO mistakes in 2026
| Mistake | What it looks like | Better move |
|---|---|---|
| Treating GEO as keyword stuffing | Repeating the brand name in every paragraph | Write clear answers and provide evidence |
| Publishing before diagnosis | Producing content without knowing current AI visibility | Run a baseline prompt audit first |
| Blocking useful crawlers by accident |
| Review crawler access with legal and engineering |
| Depending only on the website | No third-party profiles, reviews, or corroborating pages | Build credible external evidence |
| Using fake statistics | Numbers with no source or context | Use fewer numbers and make them verifiable |
| Testing prompts randomly | Different prompts every week | Keep a stable prompt library and add new prompts separately |
| Chasing every AI platform equally | Same effort across all tools | Prioritize platforms your buyers actually use |
| Expecting instant results | Declaring failure after two weeks | Review in 4-week cycles and keep improving assets |
The worst mistake is volume without trust. If a team uses AI to generate hundreds of generic pages, those pages may be easy to crawl but hard to believe. GEO rewards clarity, corroboration, and freshness more than raw output.
A practical weekly GEO routine
After the 16-week rollout, keep the workflow simple enough to survive busy weeks.
Every Monday:
- run the fixed prompt library across priority platforms;
- record brand mentions, competitors, citations, and inaccurate claims;
- flag answers that changed materially.
Every Tuesday:
- choose two to four pages to update;
- fix outdated summaries, missing examples, weak FAQs, and unclear tables;
- add internal links where they help the reader.
Every Wednesday:
- review third-party sources;
- update profiles, respond to high-intent community questions, or pitch one evidence asset.
Every Friday:
- review the dashboard;
- decide whether to create, refresh, consolidate, or retire content;
- send a short note to content, SEO, sales, and product teams.
The weekly note should be blunt: which prompts improved, which answers are still wrong, what page caused movement, and what will be fixed next.
GEO project checklist
Use this checklist before calling a GEO project "launched."
| Area | Check |
|---|---|
| Entity | Brand description is consistent across owned and major third-party profiles |
| Crawl access | Important pages are indexable and not blocked accidentally |
| Structured data | Organization, Product, Service, Article, Breadcrumb, and FAQ schema are used where relevant |
| llms.txt | The file exists if the team chooses to support it, and it points to useful canonical resources |
| Prompt library | At least 30-80 prompts are grouped by brand, category, comparison, problem, and bottom-funnel intent |
| Baseline | Week 1 answers are saved with platform, date, citations, and screenshots |
| Content assets | Core pages answer high-intent prompts directly and include tables or examples |
| Evidence | Important claims are supported by owned or credible third-party sources |
| Measurement | Mention rate, citation rate, answer accuracy, share of answer, and AI referral traffic are reviewed weekly |
| Governance | Content, SEO, product, and legal know who approves updates |
| Refresh cadence | Priority assets are reviewed at least monthly |
FAQ
How long does GEO take to work?
Expect technical fixes and content improvements in the first month, but measure visibility in 4-week cycles. Narrow prompts can move within 8-12 weeks. Competitive category prompts often need several months of content, authority, and third-party corroboration.
Is GEO replacing SEO?
No. GEO depends on many SEO foundations: crawlable pages, clear site architecture, structured data, useful content, internal links, and authority. The difference is that GEO also measures whether AI answer systems mention, cite, and accurately describe the brand.
Do I need llms.txt for GEO?
It is useful for some sites, especially when you want to guide AI agents or crawlers toward canonical resources. It is not a magic ranking file. Treat it as one access and documentation layer alongside robots.txt, sitemap.xml, schema, and clean page summaries.
Which AI platforms should I track first?
Track the platforms your buyers use. For many global B2B teams, that means ChatGPT, Perplexity, Gemini, Google AI Overviews, Bing Copilot, and sometimes Claude. Local markets or technical audiences may require different surfaces.
What is the best first GEO task for a small team?
Run a 30-prompt baseline audit. Test brand, category, comparison, and problem prompts. Save the answers, record inaccuracies, and identify which pages or third-party sources are cited. That audit will tell you whether the first priority is entity cleanup, technical access, content creation, or external evidence.
Can AI-generated content help with GEO?
Yes, but only with human review, source checking, and real expertise. AI can help draft briefs, tables, FAQs, and refresh plans. It should not invent statistics, testimonials, or case studies. Thin AI pages are unlikely to earn durable citations.
Final takeaway
GEO in 2026 is a practical growth discipline: make the brand legible, publish answer-ready evidence, earn corroboration, and measure how AI systems describe you. The teams that win will not be the teams that publish the most. They will be the teams that make the most useful facts easiest to retrieve.
Author: Martin Hayes, GEO Playbook Builder for 200+ Execution Checklists at Auspia. Martin writes practical GEO workflows, implementation checklists, and operating guides for teams that need to turn AI search visibility into repeatable work.