The practical point
Technical GEO is mostly technical SEO with stricter clarity. If a page cannot be crawled, indexed, rendered, or shown with a useful snippet, it is a weak candidate for search visibility and AI answer visibility.
Google's guidance for AI features is clear on one important point: there are no special technical requirements for appearing in AI Overviews or AI Mode beyond being indexed and eligible to appear with a snippet. That means the beginner technical workflow should not chase mystery AI tags. Start with crawlability, indexability, snippet controls, canonicals, sitemap health, internal links, and structured data that matches visible content.
Hermes can help by reading exports and turning them into a prioritized audit. It should not change technical settings by itself.
What this audit checks
Use this beginner checklist:
| Area | Question Hermes should answer | Why it matters |
|---|---|---|
| Crawlability | Can search crawlers access the URL? | Blocked pages cannot reliably enter the search index. |
| Indexability | Is the page allowed to be indexed? | A noindex page should not be expected to rank or appear in AI search features. |
| Snippet eligibility | Is the page restricted by nosnippet or max-snippet? | Google AI features require eligibility to appear with a snippet. |
| Canonical | Does the page point to the correct canonical URL? | Wrong canonicals can consolidate signals to the wrong page. |
| Sitemap | Is the important URL included and clean? | Sitemaps help discovery and auditing. |
| Structured data | Does schema match visible page content? | Structured data can clarify entities and page purpose. |
| Internal links | Can important pages be discovered internally? | Orphan pages are harder to find and understand. |
| Rendering | Does critical content load in crawlable HTML or render reliably? | Hidden or delayed content may weaken retrieval. |
The output should be a technical issue queue with evidence, impact, owner, and approval level.
Step 1: collect technical inputs
Create this folder:
/hermes-seo-agent
/technical-audit
crawl-export.csv
robots.txt
sitemap-urls.csv
url-inspection-export.csv
structured-data-export.csv
server-log-sample.csv
technical-audit-report.md
technical-fix-queue.md
/qa
technical-seo-geo-gate.md
/prompts
technical-audit-prompt.md
Minimum files:
| File | Beginner source |
|---|---|
|
| Screaming Frog, Sitebulb, Ahrefs, Semrush, or another crawler |
|
| Download from |
|
| Export sitemap URLs or crawl the XML sitemap |
|
| Manual GSC URL Inspection notes or API export if available |
|
| Rich Results Test notes, Schema validator output, or crawler schema export |
|
| Optional for beginners |
If you only have a crawl export, start there. Hermes should mark missing files as missing.
Step 2: ask Hermes to classify technical risk
Create prompts/technical-audit-prompt.md:
You are a technical SEO/GEO auditor.
Read the files in /technical-audit.
Do not make live changes.
Do not invent missing data.
If a file is missing, write "missing".
Audit these areas:
1. Crawlability
2. Indexability
3. Snippet controls
4. Canonicals
5. Sitemap inclusion
6. Structured data
7. Internal discoverability
8. Rendering or content visibility issues, if data exists
For every issue, return:
- URL
- Issue type
- Evidence
- SEO impact
- GEO impact
- Risk level: low, medium, high
- Recommended fix
- Approval owner
- Whether a developer is required
The output table:
| URL | Issue type | Evidence | SEO impact | GEO impact | Fix | Risk | Owner |
|---|---|---|---|---|---|---|---|
A useful technical audit should name the exact setting, not just say "fix crawlability."
Step 3: check robots.txt and crawl blocks
Robots.txt controls crawling, not indexing by itself. A blocked URL can still appear in search in limited cases if Google discovers it elsewhere, but blocking important pages is still a major audit item.
Prompt:
Review robots.txt and the crawl export.
Find:
1. Important directories blocked by robots.txt.
2. Important pages blocked from crawling.
3. CSS or JavaScript files blocked that may affect rendering.
4. AI or search crawler rules that may affect discovery.
5. Disallow rules that need human review.
Return only evidence-backed findings.
Do not recommend changing robots.txt without technical approval.
Robots findings table:
| Finding | Why it matters | Approval |
|---|---|---|
|
| Important informational pages may not be crawlable | Technical approval required |
|
| Usually normal, but check if critical assets are blocked | Developer review |
| AI crawler rules changed recently | May affect some AI retrieval systems | SEO and legal/policy review |
Do not tell Hermes to "open everything." Robots rules may exist for good reasons.
Step 4: check indexability and noindex
Indexability checks should look for:
noindex- X-Robots-Tag headers
- canonical conflicts
- blocked pages that should be crawled
- pages returning non-200 status codes
- pages excluded in URL inspection data
Prompt:
Review indexability using crawl-export.csv and url-inspection-export.csv if available.
Find:
1. Important pages marked noindex.
2. Important pages with X-Robots-Tag noindex.
3. Pages returning 3xx, 4xx, or 5xx where 200 is expected.
4. Pages Google reports as not indexed, if URL inspection data exists.
5. Pages blocked by robots but expected to rank.
Classify every finding as expected or unexpected.
Expected noindex pages may include internal search results, filtered pages, staging URLs, thank-you pages, or duplicate utility pages. Unexpected noindex pages need review.
Step 5: check snippet controls
Snippet controls matter for GEO because Google says pages must be eligible to appear with a snippet for AI Overviews and AI Mode.
Check:
nosnippetmax-snippet:0- very restrictive
max-snippet data-nosnippetused on important content- pages with meta descriptions that do not match the article
Prompt:
Review snippet eligibility.
Find pages with:
1. nosnippet
2. max-snippet:0
3. very restrictive max-snippet values
4. data-nosnippet around important answer content
5. missing or misleading meta descriptions
For each page, explain whether the restriction is expected or risky for SEO/GEO visibility.
Do not recommend removing snippet controls without approval.
Use this decision table:
| Setting | Usually safe when | Risky when |
|---|---|---|
|
| Page should not show text snippets | Page is meant to earn search or AI visibility |
|
| Legal or compliance reason exists | It hides useful answer content |
|
| Specific private or legal text should be excluded | It wraps the main answer or product details |
Step 6: check canonicals
Canonical tags tell search engines which URL should be treated as the preferred version. They are powerful and easy to get wrong.
Prompt:
Review canonical signals from the crawl export.
Find:
1. Important pages canonicalizing to another URL.
2. Canonical loops or chains.
3. Canonicals pointing to non-200 URLs.
4. Duplicate pages with inconsistent canonicals.
5. Pages where canonical choice conflicts with internal links or sitemap URLs.
Return recommended fixes only with evidence.
Mark all canonical changes as technical approval required.
Canonical issue table:
| URL | Current canonical | Expected canonical | Evidence | Risk | Approval |
|---|---|---|---|---|---|
Do not let Hermes change canonicals automatically. A wrong canonical can remove the wrong page from search consideration.

Step 7: check sitemap health
A sitemap should help discovery and auditing. It should not be a dumping ground for broken, redirected, duplicate, or non-indexable URLs.
Prompt:
Compare sitemap-urls.csv with crawl-export.csv.
Find sitemap URLs that are:
1. Non-200
2. Redirected
3. Noindex
4. Canonicalized to another URL
5. Blocked by robots.txt
6. Missing from internal links
7. Important pages missing from the sitemap
Return sitemap cleanup recommendations with risk level and approval owner.
Sitemap cleanup usually needs SEO approval and sometimes developer support, depending on the CMS.
Step 8: check structured data
Structured data should describe visible page content. It is not a magic GEO switch, but it can help clarify entities, page type, breadcrumbs, products, FAQs, articles, and organization details when used correctly.
Prompt:
Review structured-data-export.csv and the crawl export.
Find:
1. Pages with structured data errors.
2. Pages with schema that does not match visible content.
3. Important page types missing useful schema.
4. Duplicate or conflicting schema types.
5. Breadcrumb or organization schema inconsistencies.
For every recommendation, include the visible content that supports the schema.
Do not recommend schema that is not supported by visible page content.
Beginner schema checklist:
| Page type | Schema to consider |
|---|---|
| Blog article | Article, BreadcrumbList |
| FAQ section | FAQPage only when FAQs are visible and eligible under current guidelines |
| Product/tool page | SoftwareApplication, Product, Organization, BreadcrumbList where appropriate |
| Local/service page | LocalBusiness or Service only when accurate |
| Documentation page | TechArticle or HowTo when the page genuinely fits |
Schema should be accurate before it is ambitious.
Step 9: create a fix queue
Now ask Hermes to turn findings into a queue.
Create technical-fix-queue.md from the audit findings.
Group fixes by:
1. Critical blockers
2. Indexability risks
3. Snippet eligibility risks
4. Canonical and duplicate issues
5. Sitemap cleanup
6. Structured data improvements
7. Internal discoverability issues
For every fix, include:
- URL
- Evidence
- Recommended fix
- Expected SEO impact
- Expected GEO impact
- Implementation owner
- Approval required
- Rollback plan needed: yes/no
Fix queue template:
# Technical SEO/GEO fix queue
## Critical blockers
| Priority | URL | Issue | Evidence | Fix | Owner | Approval |
|---|---|---|---|---|---|---|
## Medium-priority fixes
| Priority | URL | Issue | Evidence | Fix | Owner | Approval |
|---|---|---|---|---|---|---|
## Low-risk improvements
| Priority | URL | Issue | Evidence | Fix | Owner | Approval |
|---|---|---|---|---|---|---|
Do not put 100 issues into one sprint. Start with the few that block important pages.
Step 10: run the technical approval gate
Create qa/technical-seo-geo-gate.md:
# Technical SEO/GEO approval gate
- [ ] Every issue has evidence.
- [ ] Missing data is marked as missing.
- [ ] Critical pages are separated from low-value pages.
- [ ] Robots.txt changes have technical approval.
- [ ] Noindex changes have SEO and technical approval.
- [ ] Canonical changes have technical approval.
- [ ] Sitemap changes have SEO or developer approval.
- [ ] Structured data matches visible content.
- [ ] Snippet control changes have SEO and policy approval if needed.
- [ ] Rollback plan exists for high-risk changes.
- [ ] Post-fix validation date is scheduled.
Prompt:
Review technical-fix-queue.md against qa/technical-seo-geo-gate.md.
Return:
1. Fixes approved for implementation
2. Fixes needing more evidence
3. Fixes needing developer approval
4. Fixes that should be rejected
5. Post-fix validation steps
If a fix changes indexation, crawling, canonicalization, redirects, or schema, treat it as a real technical change. Do not bury it in a content ticket.
Step 11: validate after fixes
Technical work is not done when the ticket closes. Validate.
Post-fix checklist:
# Post-fix validation
- [ ] Re-crawl affected URLs.
- [ ] Confirm status code.
- [ ] Confirm robots access.
- [ ] Confirm indexability.
- [ ] Confirm canonical.
- [ ] Confirm snippet controls.
- [ ] Validate structured data.
- [ ] Check sitemap if changed.
- [ ] Use URL Inspection where appropriate.
- [ ] Record baseline and next review date.
Hermes prompt:
Create a post-fix validation plan for the approved technical fixes.
For each fix, include:
- URL
- What changed
- How to validate
- Tool to use
- Expected result
- What to do if validation fails
- Review date
Validation is where many beginner audits fail. The report looked good, but nobody checked whether the fix worked.
Beginner example: a technical GEO audit finding
Scenario: A guide is meant to appear for AI search visibility prompts, but it has weak search performance.
| Data | Finding |
|---|---|
| Crawl export | Page is indexable, status 200 |
| Snippet check |
|
| GSC | Page has impressions but low clicks |
| GEO prompt check | AI answer does not cite the page |
Hermes recommendation:
Issue: Snippet restriction may limit search snippet and AI feature eligibility.
Evidence: Header contains max-snippet:0.
SEO impact: Search result snippet may be restricted.
GEO impact: Page may be ineligible or weak for AI feature summaries that require snippet eligibility.
Recommended fix: Review why max-snippet:0 exists. If no legal or product reason exists, remove or loosen it.
Risk: Medium.
Approval: SEO owner and policy/legal reviewer if restriction was intentional.
That is the right level of caution. Hermes should not simply say "remove max-snippet."
Common mistakes
| Mistake | Why it hurts | Better approach |
|---|---|---|
| Treating GEO as a special tag problem | Wastes time on unsupported hacks | Fix crawl, index, snippet, canonical, schema, and content clarity |
| Changing robots.txt too quickly | Can block important pages | Review every rule with a technical owner |
| Removing noindex without context | May index low-value or private pages | Classify expected vs unexpected noindex |
| Ignoring snippet controls | Can weaken eligibility for search features | Audit nosnippet and max-snippet settings |
| Adding schema that is not visible | Can violate structured data quality expectations | Match schema to visible content |
| No validation after fixes | Issues may persist unnoticed | Re-crawl and inspect affected URLs |
Auspia take
Technical SEO/GEO audits should be boring in the best way. They should find real blockers, show evidence, assign owners, and prevent risky changes from going live without approval.
Hermes is useful here because it can sort large exports and produce a readable fix queue. It should not become the person changing robots.txt at midnight. Keep the agent in the auditor role until a technical owner approves the fix.
If you want one starter audit, check six things first: crawlable, indexable, snippet eligible, correct canonical, clean sitemap, and valid structured data.
FAQ
Is technical GEO different from technical SEO?
Mostly, it is technical SEO applied to AI search readiness. GEO still depends on crawlable, indexable, understandable pages. The added focus is snippet eligibility, entity clarity, answer extractability, and evidence quality.
Do I need special schema for AI Overviews?
No special schema guarantees AI Overview inclusion. Use structured data when it accurately describes visible page content and fits the page type.
What is snippet eligibility?
Snippet eligibility means the page is allowed to show text snippets in search results. Restrictions such as nosnippet or very restrictive max-snippet settings can affect how content appears in search features.
Should Hermes change robots.txt or canonicals automatically?
No. Hermes can identify issues and recommend fixes, but robots.txt, noindex, canonical, redirect, sitemap, and structured data changes need human technical approval.
What crawl data should beginners export?
Start with URL, status code, indexability, title, meta description, canonical, H1, word count, inlinks, outlinks, and structured data fields if available.
How often should a technical SEO/GEO audit run?
Run a lightweight crawl monthly for active sites. Run a deeper audit after migrations, CMS changes, template changes, traffic drops, or major content launches.
Can technical fixes guarantee AI citations?
No. Technical fixes make pages eligible and easier to understand. They do not guarantee rankings, AI citations, or AI Overview inclusion.
Continue the Hermes SEO/GEO series
- Start here: Hermes SEO/GEO operator guide .
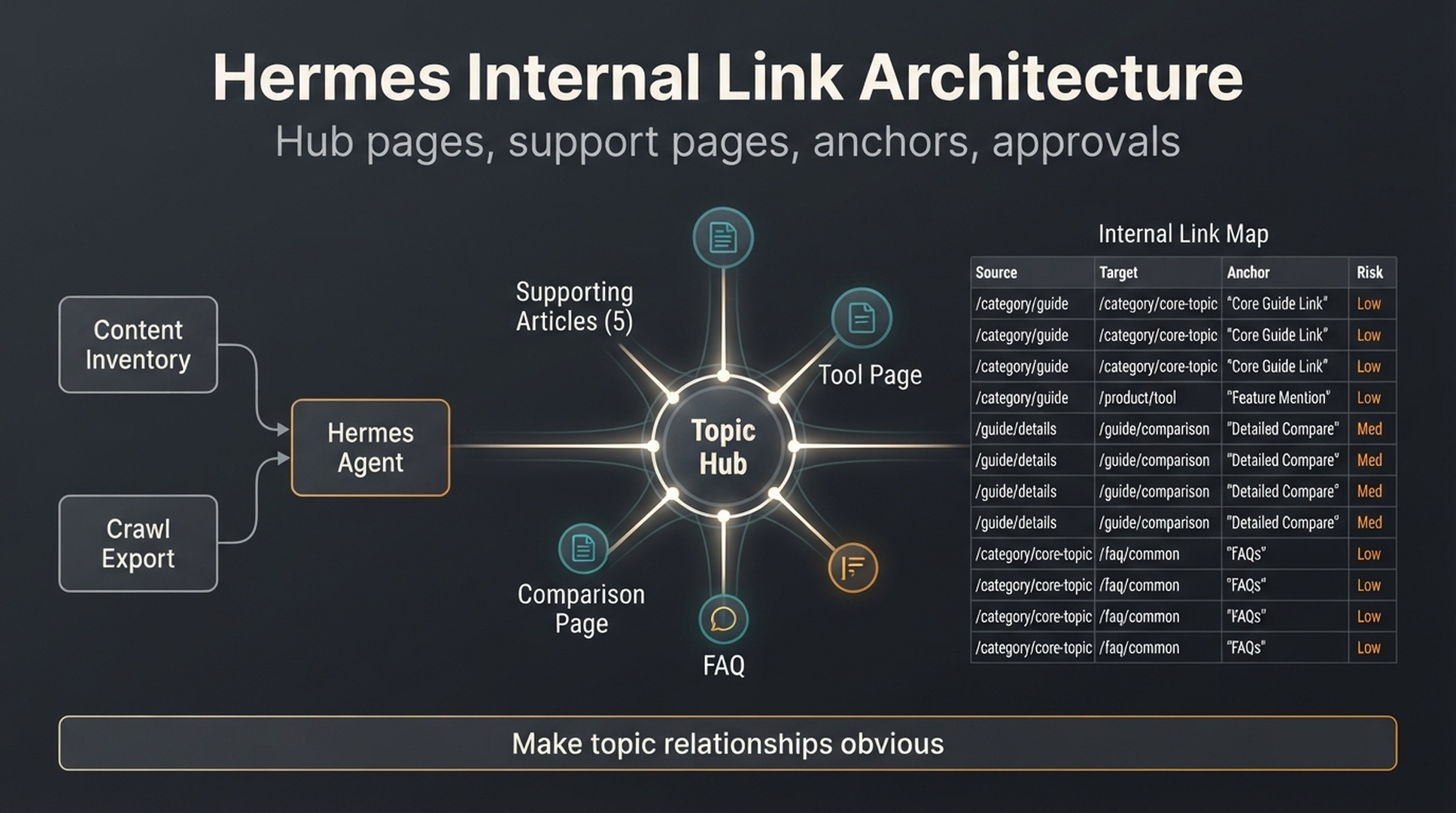
- Previous guide: How to use Hermes for internal linking and site architecture .
- Next guide: How to build a Hermes SEO/GEO swarm workflow .
- Closely related: How to set up your first Hermes SEO Agent , Hermes SEO/GEO quality gates .
Sources used
- Google AI features and your website: https://developers.google.com/search/docs/appearance/ai-features
- Google robots.txt introduction: https://developers.google.com/search/docs/crawling-indexing/robots/intro
- Google robots meta tag and X-Robots-Tag: https://developers.google.com/search/docs/crawling-indexing/robots-meta-tag
- Google canonical documentation: https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls
- Google structured data intro: https://developers.google.com/search/docs/appearance/structured-data/intro-structured-data
- Hermes Agent documentation: https://hermes-agent.nousresearch.com/docs/
Author: Julian Mercer, 14-Year Technical SEO Practitioner at Auspia. Julian writes about crawlability, schema, rendering, site architecture, and technical foundations for AI-readable content.