實用重點
技術 GEO 大多是技術 SEO,只是對清晰度要求更高。如果一個頁面無法被抓取、索引、渲染,或無法展示有用摘要,它就很難成為搜尋可見性和 AI 答案可見性的強候選。
Google 對 AI 功能的說明中有一個重點很清楚:除了被索引並有資格展示摘要之外,出現在 AI Overviews 或 AI Mode 中沒有額外特殊技術要求。這意味著新手技術工作流不應該追逐神秘 AI 標籤。先從可抓取性、可索引性、摘要控制、canonicals、sitemap 健康度、內部連結,以及與可見內容匹配的結構化資料開始。
Hermes 可以讀取匯出檔案,並把它們轉成有優先順序的審計報告。但它不應該自己修改技術設定。
這次審計檢查什麼
使用這份新手清單:
| 區域 | Hermes 應該回答的問題 | 為什麼重要 |
|---|---|---|
| 可抓取性 | 搜尋爬蟲能訪問這個 URL 嗎? | 被阻止頁面無法可靠進入搜尋索引。 |
| 可索引性 | 頁面允許被索引嗎? | noindex 頁面不應該被期待獲得排名或出現在 AI 搜尋功能中。 |
| 摘要資格 | 頁面是否受到 nosnippet 或 max-snippet 限制? | Google AI 功能要求頁面有資格展示摘要。 |
| Canonical | 頁面是否指向正確 canonical URL? | 錯誤 canonical 會把訊號合併到錯誤頁面。 |
| Sitemap | 重要 URL 是否在 sitemap 中且乾淨? | Sitemap 有助於發現和審計。 |
| 結構化資料 | Schema 是否匹配可見頁面內容? | 結構化資料能澄清實體和頁面用途。 |
| 內部連結 | 重要頁面能否透過內部連結被發現? | 孤立頁面更難被發現和理解。 |
| 渲染 | 關鍵內容是否存在於可抓取 HTML 中,或能可靠渲染? | 隱藏或延遲載入內容可能削弱檢索。 |
輸出應該是一份技術問題佇列,包含證據、影響、負責人和審批級別。
第 1 步:收集技術輸入
建立這個資料夾:
/hermes-seo-agent
/technical-audit
crawl-export.csv
robots.txt
sitemap-urls.csv
url-inspection-export.csv
structured-data-export.csv
server-log-sample.csv
technical-audit-report.md
technical-fix-queue.md
/qa
technical-seo-geo-gate.md
/prompts
technical-audit-prompt.md
最少檔案:
| 檔案 | 新手來源 |
|---|---|
|
| Screaming Frog、Sitebulb、Ahrefs、Semrush 或其他爬蟲 |
|
| 從 |
|
| 匯出 sitemap URLs 或抓取 XML sitemap |
|
| 手動 GSC URL Inspection 記錄,或可用時使用 API 匯出 |
|
| Rich Results Test 記錄、Schema validator 輸出,或爬蟲 schema 匯出 |
|
| 新手可選 |
如果你只有爬蟲匯出,就從那裡開始。Hermes 應該把缺失檔案標記為缺失。
第 2 步:讓 Hermes 分類技術風險
建立 prompts/technical-audit-prompt.md:
你是技術 SEO/GEO 審計員。
讀取 /technical-audit 中的檔案。
不要做線上改動。
不要編造缺失資料。
如果某個檔案缺失,寫“缺失”。
審計這些區域:
1. 可抓取性
2. 可索引性
3. 摘要控制
4. Canonicals
5. Sitemap 收錄
6. 結構化資料
7. 內部可發現性
8. 如有資料,渲染或內容可見性問題
對每個問題返回:
- URL
- 問題型別
- 證據
- SEO 影響
- GEO 影響
- 風險等級:低、中、高
- 推薦修復
- 審批負責人
- 是否需要開發者
輸出表:
| URL | Issue type | Evidence | SEO impact | GEO impact | Fix | Risk | Owner |
|---|---|---|---|---|---|---|---|
有用的技術審計應該說出具體設定,而不是隻說“修復抓取問題”。
第 3 步:檢查 robots.txt 和抓取阻塞
Robots.txt 控制抓取,本身不直接控制索引。被阻止的 URL 在某些情況下仍可能出現在搜尋中,如果 Google 從其他地方發現它;但阻止重要頁面仍然是重大審計項。
提示詞:
審查 robots.txt 和爬蟲匯出。
找出:
1. 被 robots.txt 阻止的重要目錄。
2. 被阻止抓取的重要頁面。
3. 可能影響渲染的 CSS 或 JavaScript 檔案阻止。
4. 可能影響發現的 AI 或搜尋爬蟲規則。
5. 需要人工審查的 Disallow 規則。
只返回有證據支援的發現。
未經技術審批,不要建議修改 robots.txt。
Robots 發現表:
| 發現 | 為什麼重要 | 審批 |
|---|---|---|
|
| 重要資訊頁面可能無法被抓取 | 需要技術審批 |
|
| 通常正常,但要檢查關鍵資源是否被阻止 | 開發者審查 |
| AI 爬蟲規則近期變化 | 可能影響某些 AI 檢索系統 | SEO 和法務/政策審查 |
不要讓 Hermes 簡單地說“全部開放”。Robots 規則可能有合理原因。
第 4 步:檢查可索引性和 noindex
可索引性檢查應該檢視:
noindex- X-Robots-Tag headers
- canonical 衝突
- 應該被抓取但被阻止的頁面
- 返回非 200 狀態碼的頁面
- URL inspection 資料中被排除的頁面
提示詞:
使用 crawl-export.csv 和 url-inspection-export.csv(如可用)審查可索引性。
找出:
1. 被標記為 noindex 的重要頁面。
2. 帶有 X-Robots-Tag noindex 的重要頁面。
3. 預期應為 200 但返回 3xx、4xx 或 5xx 的頁面。
4. 如果有 URL inspection 資料,找出 Google 報告未索引的頁面。
5. 被 robots 阻止但預期要排名的頁面。
將每個發現分類為預期或非預期。
預期 noindex 頁面可能包括站內搜尋結果、篩選頁、staging URLs、thank-you pages 或重複工具頁。非預期 noindex 頁面需要審查。
第 5 步:檢查摘要控制
摘要控制對 GEO 很重要,因為 Google 表示,頁面必須有資格展示摘要,才有資格進入 AI Overviews 和 AI Mode。
檢查:
nosnippetmax-snippet:0- 非常嚴格的
max-snippet - 用在重要內容上的
data-nosnippet - meta descriptions 與文章不匹配的頁面
提示詞:
審查摘要資格。
找出帶有這些情況的頁面:
1. nosnippet
2. max-snippet:0
3. 非常嚴格的 max-snippet 值
4. data-nosnippet 包住重要答案內容
5. 缺失或誤導性的 meta descriptions
對每個頁面解釋該限制是預期行為,還是會影響 SEO/GEO 可見性的風險。
未經審批,不要建議移除摘要控制。
使用這張決策表:
| 設定 | 通常安全的情況 | 有風險的情況 |
|---|---|---|
|
| 頁面不應展示文字摘要 | 頁面目標是獲得搜尋或 AI 可見性 |
|
| 存在法律或合規原因 | 它隱藏了有用答案內容 |
|
| 需要排除特定隱私或法律文字 | 它包住了主要答案或產品細節 |
第 6 步:檢查 canonicals
Canonical 標籤告訴搜尋引擎哪個 URL 應被視為首選版本。它們很強大,也很容易出錯。
提示詞:
從爬蟲匯出中審查 canonical 訊號。
找出:
1. 重要頁面 canonical 到另一個 URL。
2. Canonical loops 或 chains。
3. Canonicals 指向非 200 URLs。
4. Canonicals 不一致的重複頁面。
5. Canonical 選擇與內部連結或 sitemap URLs 衝突的頁面。
只返回有證據的推薦修復。
將所有 canonical 改動標記為需要技術審批。
Canonical 問題表:
| URL | Current canonical | Expected canonical | Evidence | Risk | Approval |
|---|---|---|---|---|---|
不要讓 Hermes 自動改 canonical。錯誤 canonical 可能讓錯誤頁面從搜尋考慮中消失。
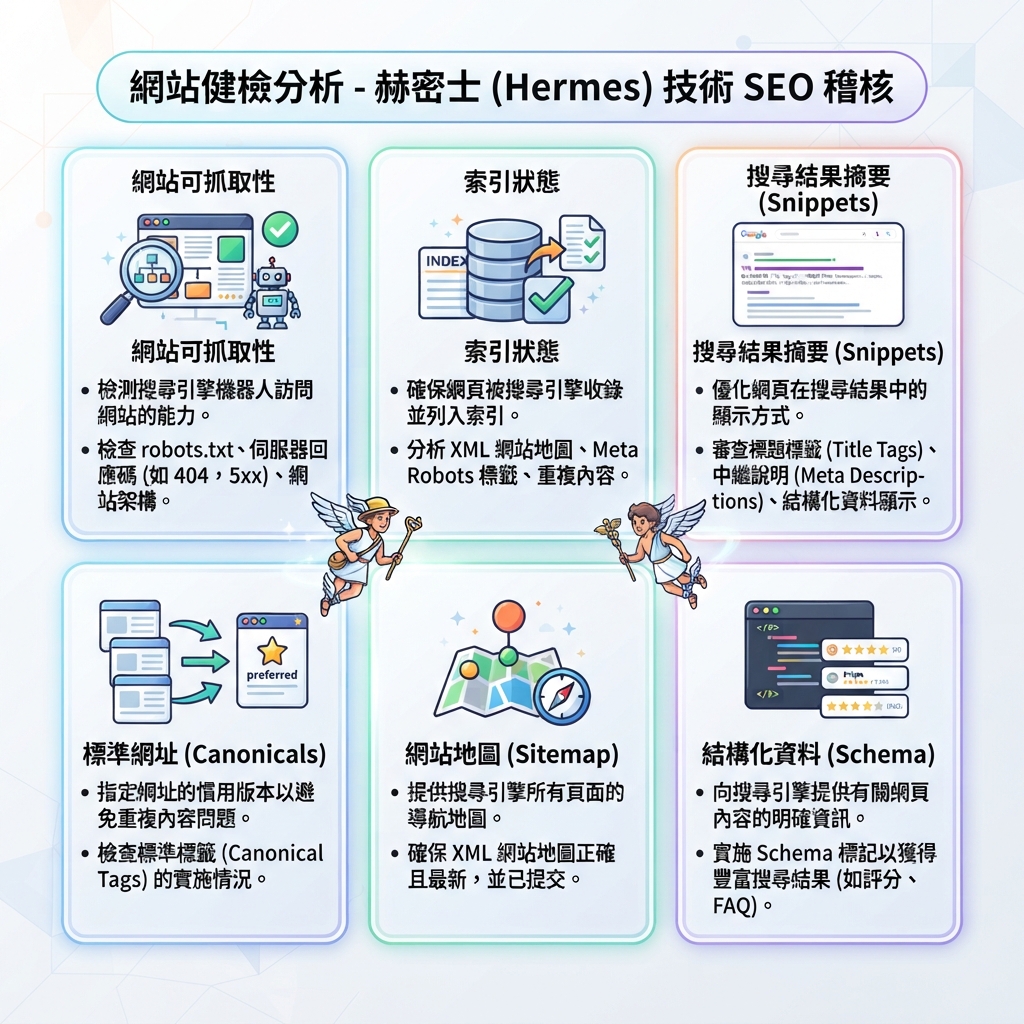
第 7 步:檢查 sitemap 健康度
Sitemap 應該幫助發現和審計。它不應該成為破損、跳轉、重複或不可索引 URL 的垃圾場。
提示詞:
比較 sitemap-urls.csv 和 crawl-export.csv。
找出 sitemap URLs 中:
1. 非 200 的 URL
2. Redirected URL
3. Noindex URL
4. Canonicalized 到另一個 URL 的 URL
5. 被 robots.txt 阻止的 URL
6. 缺少內部連結的 URL
7. 重要但缺失於 sitemap 的頁面
返回 sitemap 清理建議,包含風險等級和審批負責人。
Sitemap 清理通常需要 SEO 審批,有時也需要開發支援,具體取決於 CMS。
第 8 步:檢查結構化資料
結構化資料應該描述可見頁面內容。它不是神奇 GEO 開關,但在使用正確時,可以幫助澄清實體、頁面型別、麵包屑、產品、FAQ、文章和組織資訊。
提示詞:
審查 structured-data-export.csv 和爬蟲匯出。
找出:
1. 有結構化資料錯誤的頁面。
2. Schema 與可見內容不匹配的頁面。
3. 缺少有用 schema 的重要頁面型別。
4. 重複或衝突的 schema types。
5. Breadcrumb 或 organization schema 不一致。
每條推薦都包含支援該 schema 的可見內容。
不要推薦沒有可見頁面內容支援的 schema。
新手 schema 清單:
| 頁面型別 | 可考慮的 Schema |
|---|---|
| 部落格文章 | Article、BreadcrumbList |
| FAQ 小節 | 只有在 FAQ 可見且符合當前指南時,才使用 FAQPage |
| 產品/工具頁 | 適當情況下使用 SoftwareApplication、Product、Organization、BreadcrumbList |
| 本地/服務頁 | 只有準確時,才使用 LocalBusiness 或 Service |
| 檔案頁 | 頁面確實符合時,使用 TechArticle 或 HowTo |
Schema 應該先準確,再追求複雜。
第 9 步:建立修復佇列
現在讓 Hermes 把發現轉成佇列。
根據審計發現建立 technical-fix-queue.md。
按這些組分類修復:
1. 關鍵阻塞
2. 可索引性風險
3. 摘要資格風險
4. Canonical 和重複問題
5. Sitemap 清理
6. 結構化資料改進
7. 內部可發現性問題
對每個修復包含:
- URL
- 證據
- 推薦修復
- 預期 SEO 影響
- 預期 GEO 影響
- 實施負責人
- 所需審批
- 是否需要回滾計劃:是/否
修復佇列範本:
# 技術 SEO/GEO 修復佇列
## 關鍵阻塞
| Priority | URL | Issue | Evidence | Fix | Owner | Approval |
|---|---|---|---|---|---|---|
## 中優先順序修復
| Priority | URL | Issue | Evidence | Fix | Owner | Approval |
|---|---|---|---|---|---|---|
## 低風險改進
| Priority | URL | Issue | Evidence | Fix | Owner | Approval |
|---|---|---|---|---|---|---|
不要把 100 個問題塞進一個 sprint。先處理會阻塞重要頁面的少數問題。
第 10 步:執行技術審批門
建立 qa/technical-seo-geo-gate.md:
# 技術 SEO/GEO 審批門
- [ ] 每個問題都有證據。
- [ ] 缺失資料已標記為缺失。
- [ ] 關鍵頁面與低價值頁面已分開。
- [ ] Robots.txt 改動有技術審批。
- [ ] Noindex 改動有 SEO 和技術審批。
- [ ] Canonical 改動有技術審批。
- [ ] Sitemap 改動有 SEO 或開發審批。
- [ ] 結構化資料匹配可見內容。
- [ ] 如有需要,摘要控制改動有 SEO 和政策審批。
- [ ] 高風險改動有回滾計劃。
- [ ] 已安排修復後驗證日期。
提示詞:
根據 qa/technical-seo-geo-gate.md 審查 technical-fix-queue.md。
返回:
1. 可批准實施的修復
2. 需要更多證據的修復
3. 需要開發者審批的修復
4. 應拒絕的修復
5. 修復後驗證步驟
如果某個修復會改變索引、抓取、canonical、redirects 或 schema,就把它當作真正的技術改動。不要把它埋在內容工單裡。
第 11 步:修復後驗證
技術工作不是工單關閉就結束。必須驗證。
修復後清單:
# 修復後驗證
- [ ] 重新抓取受影響 URLs。
- [ ] 確認狀態碼。
- [ ] 確認 robots 訪問。
- [ ] 確認可索引性。
- [ ] 確認 canonical。
- [ ] 確認摘要控制。
- [ ] 驗證結構化資料。
- [ ] 如果 sitemap 變更,檢查 sitemap。
- [ ] 適當時使用 URL Inspection。
- [ ] 記錄基線和下次審查日期。
Hermes 提示詞:
為已批准的技術修復建立修復後驗證計劃。
對每個修復包含:
- URL
- 改了什麼
- 如何驗證
- 使用工具
- 預期結果
- 如果驗證失敗怎麼辦
- 審查日期
很多新手審計失敗在驗證環節。報告看起來很好,但沒人檢查修復是否真的生效。
新手範例:一個技術 GEO 審計發現
場景:一篇指南本應覆蓋 AI 搜尋可見性提示詞,但搜尋表現較弱。
| 資料 | 發現 |
|---|---|
| 爬蟲匯出 | 頁面可索引,狀態 200 |
| 摘要檢查 | 頁面 header 中存在 |
| GSC | 頁面有展示,但點選低 |
| GEO 提示詞檢查 | AI 答案沒有引用該頁面 |
Hermes 建議:
問題:摘要限制可能限制搜尋摘要和 AI 功能資格。
證據:Header 包含 max-snippet:0。
SEO 影響:搜尋結果摘要可能受限。
GEO 影響:頁面對需要摘要資格的 AI 功能總結可能不具備資格或較弱。
推薦修復:審查 max-snippet:0 存在原因。如果沒有法律或產品原因,移除或放寬它。
風險:中。
審批:SEO 負責人;如果該限制原本有意設定,還需要政策/法務稽核者。
這才是合適的謹慎程度。Hermes 不應該直接說“刪除 max-snippet”。
常見錯誤
| 錯誤 | 為什麼有害 | 更好的做法 |
|---|---|---|
| 把 GEO 當作特殊標籤問題 | 把時間浪費在無依據技巧上 | 修復抓取、索引、摘要、canonical、schema 和內容清晰度 |
| 太快修改 robots.txt | 可能阻止重要頁面 | 和技術負責人審查每條規則 |
| 不看上下文就移除 noindex | 可能索引低價值或私密頁面 | 區分預期和非預期 noindex |
| 忽略摘要控制 | 可能削弱搜尋功能資格 | 審計 nosnippet 和 max-snippet 設定 |
| 新增不可見內容不支援的 schema | 可能違反結構化資料質量預期 | 讓 schema 匹配可見內容 |
| 修復後不驗證 | 問題可能繼續存在 | 重新抓取並檢查受影響 URLs |
Auspia 觀點
技術 SEO/GEO 審計最好是“無聊”的:找到真實阻塞、展示證據、分配負責人,並阻止高風險改動未經審批上線。
Hermes 在這裡有用,是因為它可以整理大型匯出,並生成可讀的修復佇列。它不應該變成半夜修改 robots.txt 的人。在技術負責人批准修復前,讓 agent 保持審計員角色。
如果你想做一個入門審計,先檢查六件事:可抓取、可索引、摘要資格、正確 canonical、乾淨 sitemap 和有效結構化資料。
FAQ
技術 GEO 和技術 SEO 不同嗎?
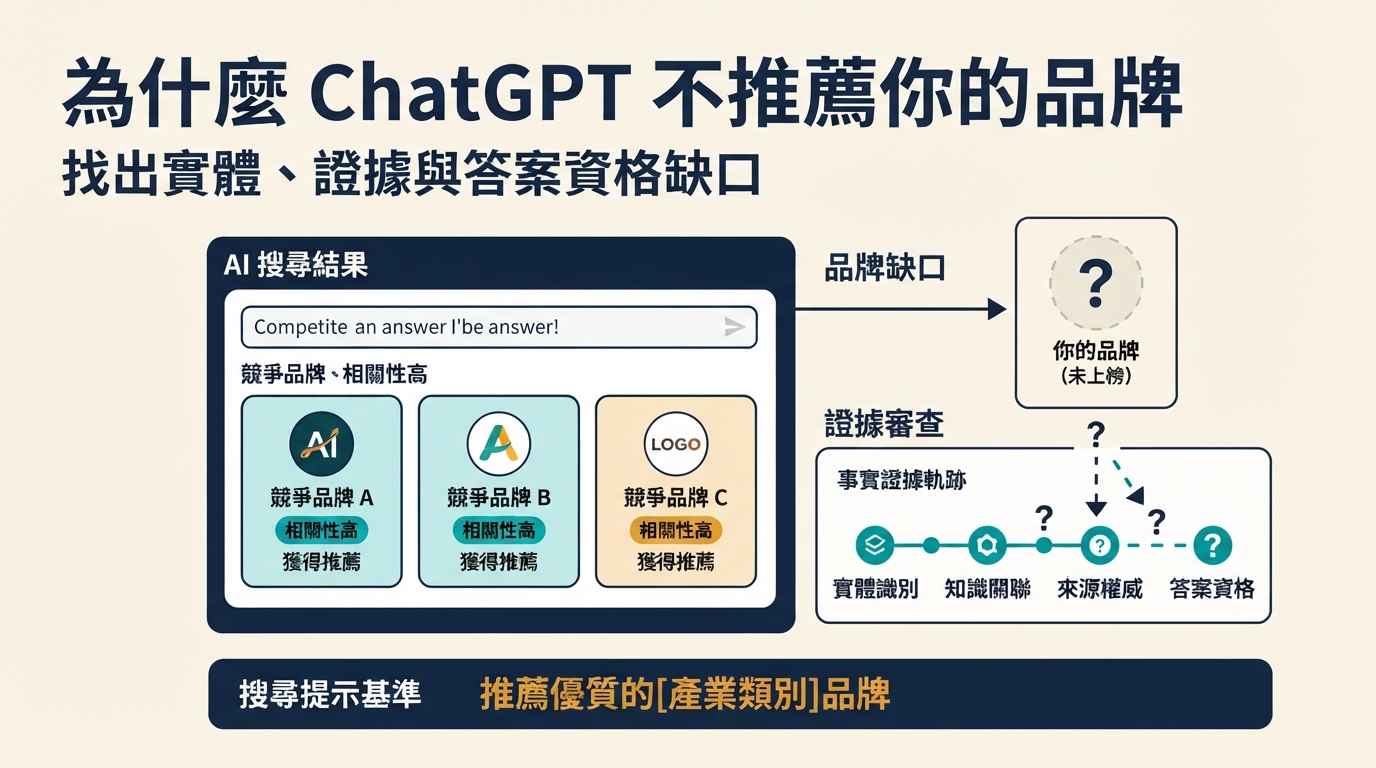
大部分情況下,它是把技術 SEO 應用於 AI 搜尋準備度。GEO 仍然依賴可抓取、可索引、可理解的頁面。額外重點是摘要資格、實體清晰度、答案可提取性和證據質量。
AI Overviews 需要特殊 schema 嗎?
沒有任何特殊 schema 能保證進入 AI Overview。只有當結構化資料準確描述可見頁面內容並符合頁面型別時,才使用它。
什麼是摘要資格?
摘要資格是指頁面允許在搜尋結果中展示文字摘要。nosnippet 或非常嚴格的 max-snippet 等限制,可能影響內容在搜尋功能中的呈現方式。
Hermes 應該自動修改 robots.txt 或 canonicals 嗎?
不應該。Hermes 可以識別問題並推薦修復,但 robots.txt、noindex、canonical、redirect、sitemap 和結構化資料改動都需要人工技術審批。
新手應該匯出哪些爬蟲資料?
從 URL、狀態碼、可索引性、title、meta description、canonical、H1、字數、inlinks、outlinks 開始;如果可用,再加入結構化資料欄位。
技術 SEO/GEO 審計應該多頻繁執行?
活躍網站每月執行一次輕量爬蟲。遷移、CMS 變更、範本變更、流量下降或重大內容釋出後,執行更深入審計。
技術修復能保證 AI 引用嗎?
不能。技術修復讓頁面具備資格,並更容易被理解。它不能保證排名、AI 引用或 AI Overview 收錄。
繼續閱讀 Hermes SEO/GEO 系列
- 從這裡開始: Hermes SEO/GEO 操作員指南 。
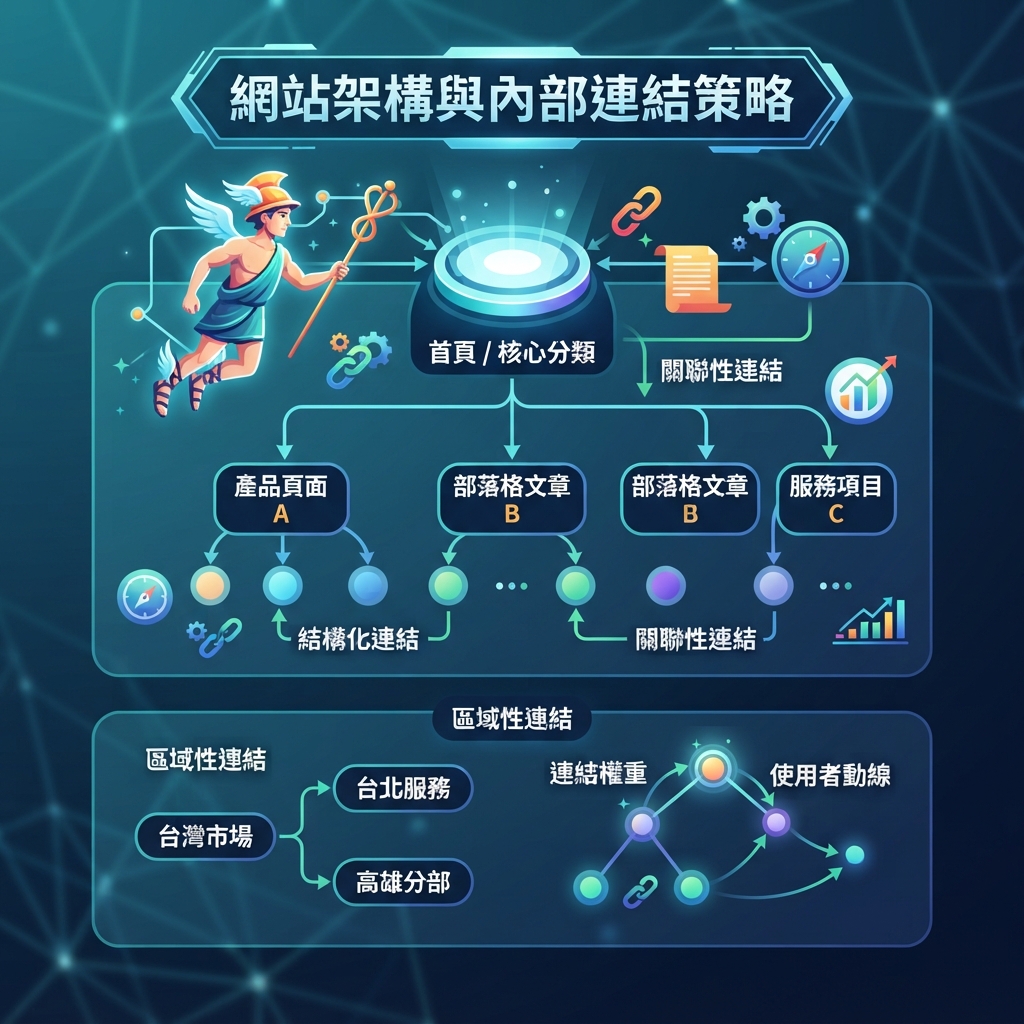
- 上一篇指南: 如何用 Hermes 做內部連結和站點架構 。
- 下一篇指南: 如何搭建 Hermes SEO/GEO swarm 工作流 。
- 密切相關: 如何配置你的第一個 Hermes SEO Agent 、 Hermes SEO/GEO 質量門 。
使用來源
- Google AI features and your website: https://developers.google.com/search/docs/appearance/ai-features
- Google robots.txt introduction: https://developers.google.com/search/docs/crawling-indexing/robots/intro
- Google robots meta tag and X-Robots-Tag: https://developers.google.com/search/docs/crawling-indexing/robots-meta-tag
- Google canonical documentation: https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls
- Google structured data intro: https://developers.google.com/search/docs/appearance/structured-data/intro-structured-data
- Hermes Agent documentation: https://hermes-agent.nousresearch.com/docs/
作者:Julian Mercer,Auspia 14 年技術 SEO 實踐者。Julian 專注於可抓取性、schema、渲染、站點架構和 AI 可讀內容的技術基礎。