Direct answer
If GEO is not bringing leads, the problem is usually not "AI search does not work." It is more often a broken chain: the brand is not mentioned in answer engines, the mention is not trusted enough to earn a citation, the cited page does not match buying intent, or the team measures only sessions while the real influence happens before the click.
The fix is to treat GEO as an acquisition system, not a content label. Build a prompt set from real buyer questions, measure visibility across ChatGPT, Perplexity, Gemini, and Google AI experiences, repair the pages that should be cited, add third-party proof where AI systems already look, and connect AI-referred visits to pipeline quality. Do this for 60 to 90 days before calling GEO a failure.
| Symptom | Likely cause | What to fix first |
|---|---|---|
| No AI mentions | Weak entity signals or wrong prompt set | Brand facts, category language, prompt library |
| Mentions without citations | Thin proof or hard-to-extract content | Source pages, schema, comparison tables, data blocks |
| Citations without leads | Informational pages only | Buyer-intent landing pages and CTAs |
| AI traffic is tiny | Wrong KPI expectation | Share of answer, citation rate, assisted conversions |
| Competitors appear instead | They own trusted third-party sources | Review pages, listicles, partner pages, PR, community mentions |
Why GEO acquisition often feels disappointing
Most teams start GEO with the wrong mental model. They publish a few "AI-ready" blog posts, ask ChatGPT a couple of questions, then wait for demo requests. That is too shallow.
GEO, or generative engine optimization, is about improving how often and how accurately a brand is named, summarized, recommended, and cited inside AI-generated answers. The academic paper that popularized the term tested methods for improving visibility in generative engines, including adding citations, statistics, and clearer source signals. That matters because answer engines synthesize from many sources instead of showing a simple list of ten blue links.
Google also frames AI features as part of Search rather than a separate channel. Its guidance for site owners still points back to durable search fundamentals: make useful, people-first content available for crawling and indexing, use clear technical signals, and provide content that can be understood by Google Search systems. In other words, GEO is not a magic replacement for SEO. It sits on top of crawlability, entity clarity, content quality, and external trust.
The acquisition problem starts when teams skip those foundations and only change wording on a few pages.
The seven failure points in a weak GEO funnel
1. The prompt set is not based on buyer behavior
A keyword list is not enough. AI search queries are often longer, more comparative, and more task-oriented than classic SEO keywords.
Weak prompts sound like this:
- "best CRM"
- "GEO software"
- "AI SEO"
Useful GEO prompts sound closer to how a buyer talks when they are almost ready to act:
- "What are the best tools to measure AI search visibility for a B2B SaaS company?"
- "Which GEO agencies help startups get cited in ChatGPT and Perplexity?"
- "How should a marketing team diagnose why AI search mentions are not converting?"
- "Compare tool A, tool B, and tool C for tracking AI citations."
A team can rank for a keyword and still disappear from these decision prompts. Start with 30 to 50 prompts across problem-aware, solution-aware, vendor-comparison, and implementation stages. Run them weekly across the answer engines that matter to your market.
2. The brand entity is fuzzy
AI systems need a stable answer to simple questions: what the company is, who it serves, what category it belongs to, what it does better than alternatives, and where those facts are confirmed.
If your homepage says "AI growth platform," your About page says "content intelligence suite," your LinkedIn page says "marketing automation," and third-party listings put you under "SEO tools," the model has to guess. It may not mention you at all, or it may describe you in a way that attracts the wrong buyer.
Fix the entity layer first:
- Use one primary category phrase across the homepage, About page, product pages, schema, profiles, and boilerplates.
- Add a concise "What is [brand]?" answer block near the top of the About or company page.
- Publish a comparison-friendly feature matrix, not just a benefits page.
- Keep leadership, location, product names, pricing model, and support facts consistent across the web.
This is not glamorous work. It is also where many GEO programs start to recover.
3. The content is readable to humans but hard for AI to extract
A page can be well written and still be a bad citation source. Answer engines prefer pages where the useful facts are easy to lift, summarize, and verify.
Look for these problems:
- Long intros before the actual answer
- Vague headings such as "Our approach" instead of question-led headings
- Claims with no source, example, table, or data point nearby
- Product pages that avoid direct comparisons
- Missing FAQ sections for real buying objections
- No schema or inconsistent structured data
A better page gives the answer early, then supports it with proof. Use short answer blocks, tables, definitions, examples, pros and cons, and dated evidence. If a section answers a question, make the heading look like the question.
For example, replace "Platform intelligence" with "How does Auspia measure AI search visibility?" That small change gives both users and AI systems a clearer retrieval target.
4. There is no third-party proof layer
Your own website is only one source. AI systems often lean on repeated consensus across review sites, comparison pages, partner ecosystems, news mentions, community discussions, documentation, and industry lists.
This is where many GEO projects stall. The team keeps editing its own blog while competitors are repeatedly mentioned in "best tools" articles, Reddit threads, YouTube roundups, integration pages, and analyst-style comparisons.
Build a proof map for each money prompt:
| Prompt type | Sources AI may trust | Action |
|---|---|---|
| "Best tools for..." | Listicles, review pages, category pages | Pitch inclusion with accurate positioning |
| "Compare A vs B" | Comparison pages, user forums, help docs | Publish honest comparison pages and collect third-party mentions |
| "How to solve..." | Tutorials, docs, templates, community answers | Create practical guides with examples and citations |
| "Is [brand] legit?" | Reviews, case studies, security pages, company profiles | Strengthen trust pages and external profiles |
This is not old-school link building with a new name. The goal is not raw backlink count. The goal is source agreement around the facts you want answer engines to repeat.
5. GEO content stops at awareness
A common pattern: the blog finally earns a citation, but the cited page is a beginner guide with no next step. The user reads the AI answer, maybe clicks, then lands on an article that does not move them toward a diagnostic, demo, template, checklist, or comparison.
That is how you get "visibility" without acquisition.
Every GEO target page needs a conversion job:
- Definition pages should point to a diagnostic tool or checklist.
- Comparison pages should point to a demo, pricing page, or migration guide.
- How-to pages should offer a template, audit, or workflow.
- Case-style pages should point to the method behind the result.
For this topic, a natural next step is an AI visibility audit. A reader who asks why GEO is not working should not be sent to a generic newsletter CTA. They need a way to test whether their brand appears, where it appears, and which page or source is missing. Auspia's AI Search Visibility Checker is a better fit than a broad product pitch.
6. Measurement stops at sessions
AI search often changes the path before the click. A buyer may ask an answer engine for options, see your brand summarized, search your brand later, ask a colleague, and convert through direct or branded organic traffic. If your dashboard only counts direct AI referrals, GEO will look weaker than it is.
Track three layers instead:
| Layer | Metric | Why it matters |
|---|---|---|
| Answer visibility | Mention rate, citation rate, share of answer, sentiment | Shows whether AI systems include you |
| Source quality | Which URLs are cited, which competitors appear, citation context | Shows what to repair or reinforce |
| Business impact | AI-referred sessions, engaged visits, assisted conversions, demo quality | Shows whether visibility creates pipeline |
Set up a custom AI search channel in analytics for known referrers such as Perplexity, ChatGPT, Gemini, Copilot, Claude, and similar tools. Then add a weekly manual prompt-tracking sheet or a dedicated GEO measurement tool. The dashboard does not need to be fancy at first. It needs to be consistent.
7. The time horizon is too short
GEO does not behave like paid search. You cannot change a headline today and expect stable answer-engine visibility tomorrow. Crawling, indexing, retrieval, model behavior, third-party source updates, and query variation all add lag.
A fair test usually needs:
- Week 1: baseline prompts, competitor map, analytics setup
- Weeks 2-4: entity cleanup, page restructuring, schema, internal links
- Weeks 4-8: third-party proof building and page refreshes
- Weeks 8-12: measurement review, prompt expansion, conversion repair
If the team has only done two weeks of blog edits, it has not really tested GEO acquisition yet.
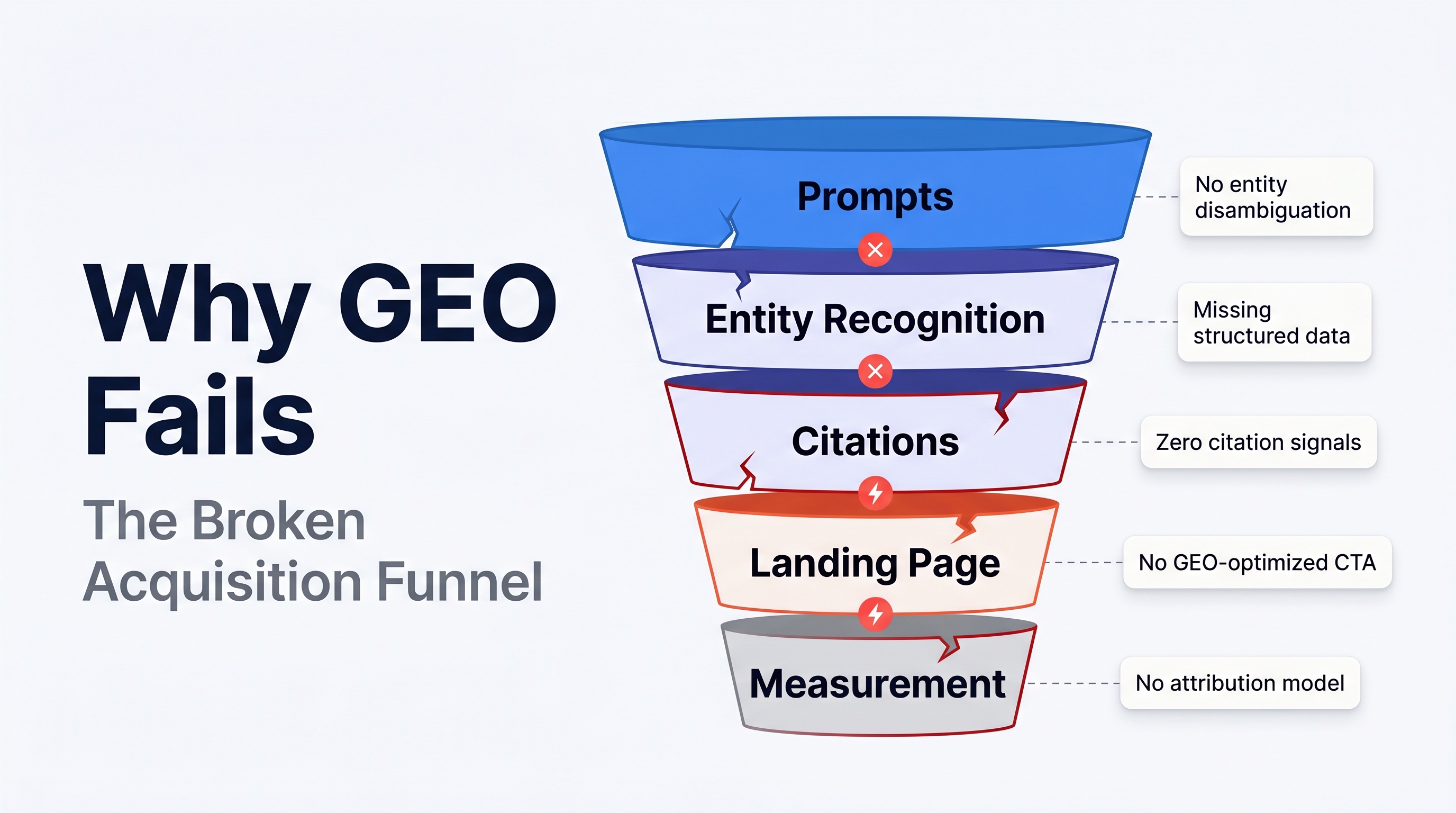
The broken GEO funnel usually starts before the click: weak prompts, fuzzy entity signals, uncited pages, dead-end landing pages, and incomplete measurement.
A practical 30-day repair plan
Week 1: diagnose the break
Create a simple table with 30 to 50 prompts. For each prompt, record:
- Does the brand appear?
- Is it cited or only mentioned?
- Which URL is cited?
- Which competitors appear?
- Is the description accurate?
- Does the cited page have a clear next step?
Run the same prompt set across at least three surfaces: ChatGPT with browsing or search where available, Perplexity, Gemini, and Google AI experiences when relevant. Do not overreact to one answer. Look for patterns.
Week 2: fix the pages that should be cited
Pick the ten prompts closest to revenue. For each one, assign a target URL. Then update the page:
- Add a direct answer block in the first screen.
- Rewrite headings as real questions.
- Add comparison tables where buyers need comparison.
- Add examples, dates, screenshots, data points, and source references.
- Add schema where appropriate.
- Add one clear CTA that matches the intent.
If no target URL exists, create one. Do not expect a generic blog post to win a high-intent comparison prompt.
Week 3: build source consensus
For each priority prompt, list the external pages answer engines already cite. Then ask: can we be accurately included there?
Possible actions:
- Update partner profiles and marketplace listings.
- Pitch category list inclusions with concise, factual copy.
- Publish an original benchmark or checklist others can cite.
- Turn customer proof into a public case page, if allowed.
- Answer community questions without forcing a link.
The useful test is simple: if an AI answer looked for independent confirmation, would it find the same facts in more than one credible place?
Week 4: connect visibility to conversion
Review the prompts where the brand now appears or has a realistic path to appear. For each cited or target page, check the conversion path:
- Is there a next step above the fold?
- Does the CTA match the question?
- Is the page written for the buyer stage, not just the topic?
- Are AI referrals grouped in analytics?
- Are demo forms asking how the visitor found you, with "AI search" as an option?
This is where GEO becomes acquisition work. A citation that lands on a dead-end article is a vanity metric. A citation that lands on a diagnostic, comparison, or proof page can become pipeline.

A 90-day GEO repair plan should track answer visibility, citation quality, source consensus, and business impact instead of treating AI referrals as the only KPI.
What to measure before declaring GEO a failure
Use a scorecard like this for 90 days:
| Metric | Good early signal | Warning sign |
|---|---|---|
| Brand mention rate | Rising across priority prompts | Only appears for branded prompts |
| Citation rate | Your URLs cited for problem and comparison prompts | Mentions without source links |
| Share of answer | Competitors displaced in some prompts | Same competitors dominate every run |
| Description accuracy | AI describes the category and use case correctly | Wrong category or outdated facts |
| Source diversity | Own site plus third-party mentions | Only your own blog mentions the claim |
| Conversion quality | Longer sessions, tool starts, demos, assisted conversions | Clicks land on low-intent posts |
The early goal is not instant lead volume. It is evidence that answer engines are learning the right facts and users who arrive from those answers find a page that matches their intent.
Common mistakes to avoid
Do not rename ordinary SEO work as GEO and stop there. Technical SEO, structured data, indexability, internal links, and content quality still matter.
Do not chase every prompt. A visibility score for broad informational questions is less useful than a smaller prompt set tied to purchase intent.
Do not publish synthetic "AI content" at scale without evidence. Pages that repeat generic advice rarely become trusted sources.
Do not overuse schema as a cure-all. Structured data helps clarify content, but it cannot make weak claims credible.
Do not ignore third-party sources. If answer engines consistently cite competitor mentions from external pages, your own blog edits will not close the gap by themselves.
Auspia's take
Bad GEO programs optimize assets. Good GEO programs optimize the path from question to answer to proof to action.
That path has five parts:
- Prompt: What does the buyer ask?
- Entity: Does the AI system understand who you are?
- Source: Is there a page worth citing?
- Proof: Do other trusted sources confirm the claim?
- Conversion: Does the landing page help the user take the next step?
If one part is missing, GEO can look busy and still produce no leads. The repair is not more content volume. It is a tighter acquisition loop.
If you need a starting point, audit one high-intent topic cluster with the GEO Score Checker , then rebuild the pages and proof sources around the prompts that actually influence buyers.
FAQ
How long does GEO take to generate leads?
Most teams should allow 60 to 90 days for a serious first test. The first signals are usually mention rate, citation rate, and description accuracy. Lead volume comes later, once the cited pages and CTAs match buyer intent.
Why does my brand appear in ChatGPT but not in Perplexity or Google AI results?
Each answer engine uses different retrieval systems, sources, freshness signals, and presentation rules. That is why GEO measurement should cover several platforms instead of treating one model response as the truth.
Is GEO separate from SEO?
No. GEO depends on many SEO basics: crawlable pages, clear structure, helpful content, internal links, schema, and trusted external references. The difference is the output you are optimizing for. SEO often aims for rankings and clicks. GEO aims for mentions, citations, answer inclusion, and influenced decisions.
What is the fastest GEO fix?
The fastest useful fix is usually not a new blog post. It is improving an existing page that already matches a high-intent prompt: add a direct answer, comparison table, evidence, schema, and a relevant CTA.
Should we measure AI traffic or AI citations first?
Measure both, but start with citations and mentions. AI referral traffic can be undercounted or delayed. If answer engines do not mention or cite you, traffic analysis will not explain much.
Author: Martin Hayes, GEO Playbook Builder for 200+ Execution Checklists at Auspia. Martin writes practical GEO workflows, audit steps, and execution checklists for teams turning AI visibility into pipeline.