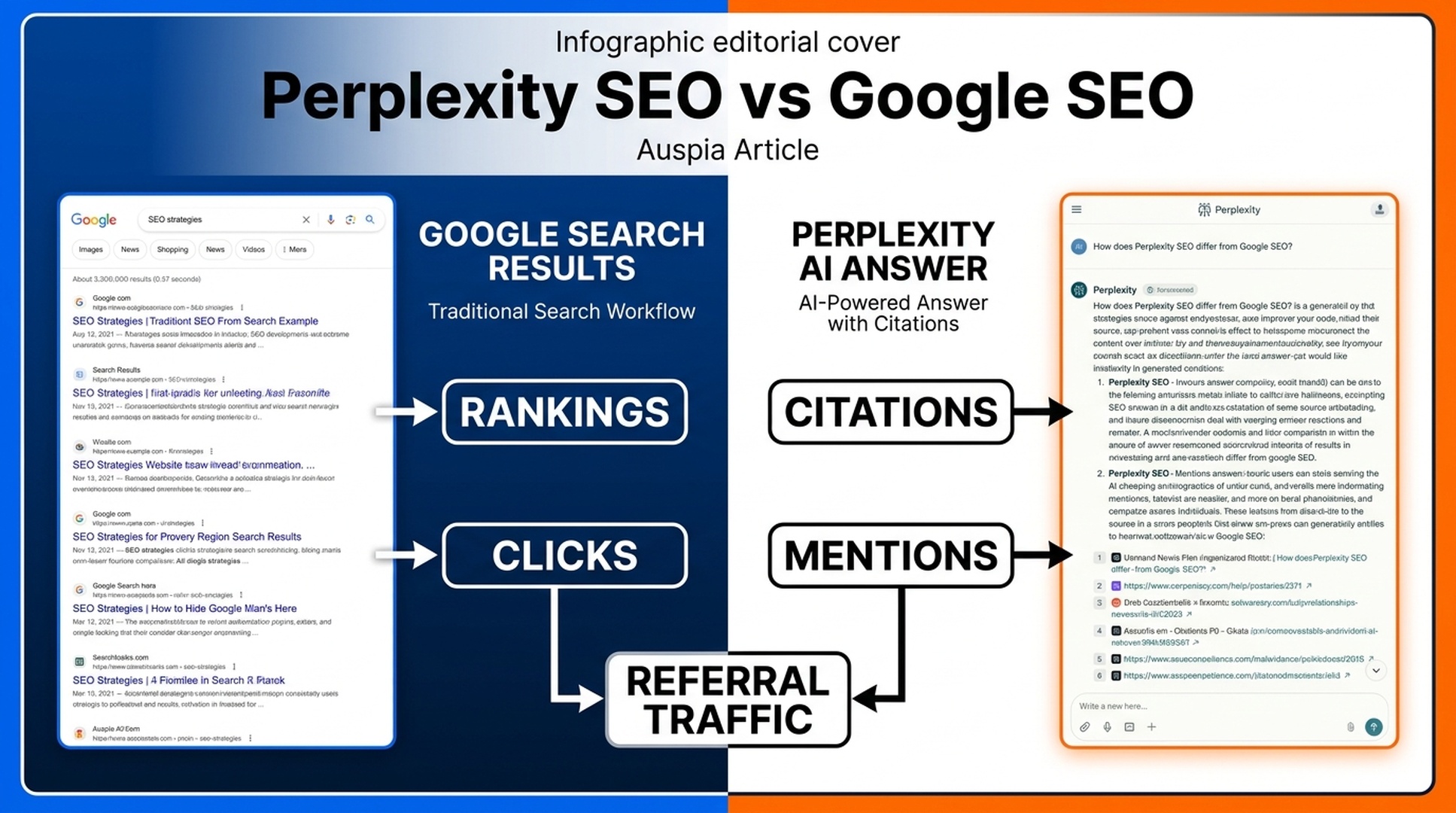
Executive summary
The loudest AI search tactic this week is not the one most teams should chase first. Ahrefs looked at 137,000 domains and found that 28% had an llms.txt file, but 97% of those files received zero requests in May 2026. Meanwhile, separate research on Claude visibility suggests that Claude's web answers are still closely tied to conventional search results, especially Brave Search and Google-visible pages. At the same time, OpenAI's ad tooling is moving toward product-feed automation, which matters for ecommerce teams long before they have a perfect GEO stack.
The practical takeaway: treat AI search as an extension of search operations, not a separate magic channel. Keep llms.txt tidy if you already use it, but put most of this month's effort into crawlable pages, current titles, structured product data, citation-ready content, and measured visibility checks.
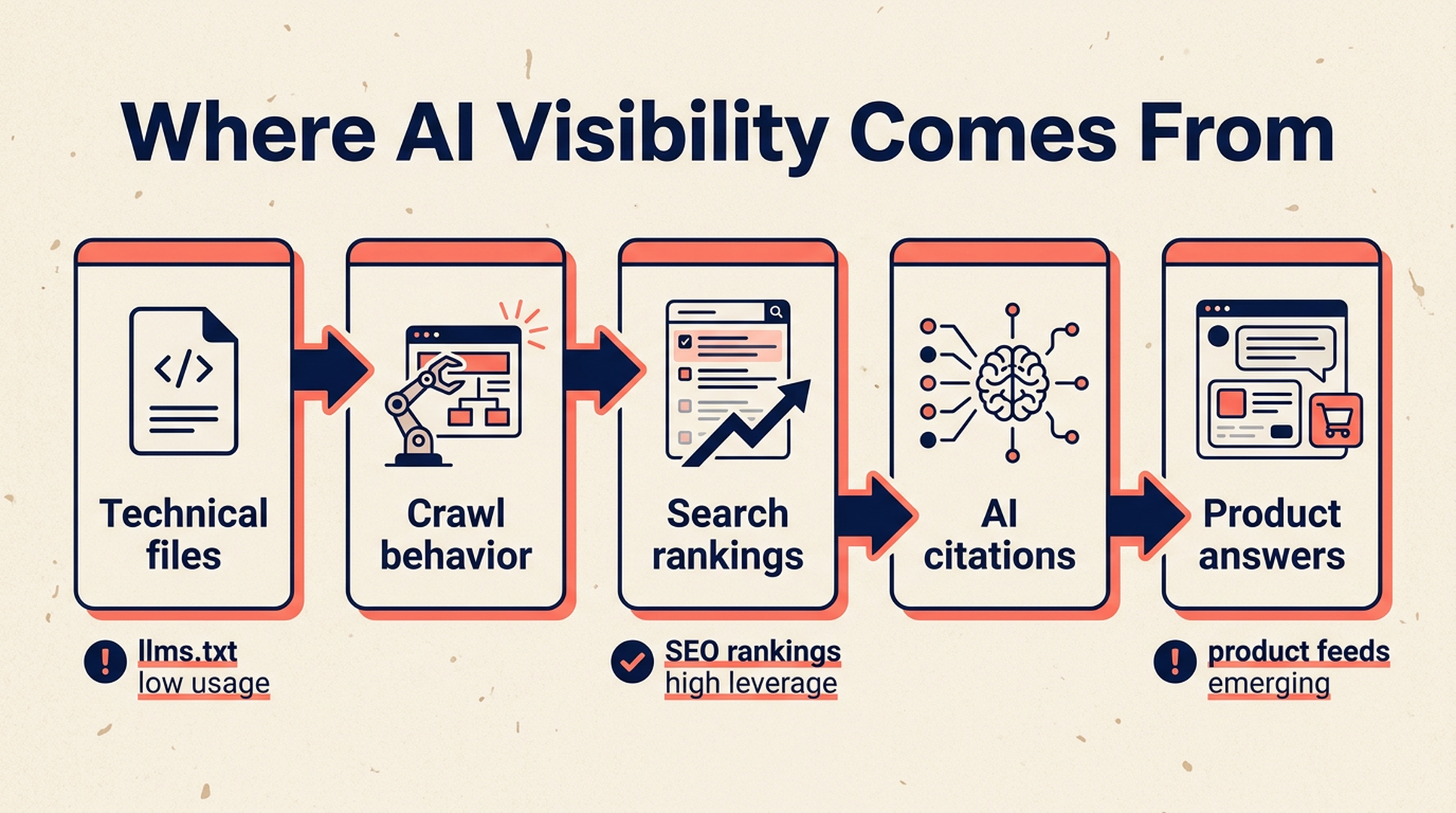
AI visibility still comes from boring inputs: pages that rank, pages that can be crawled, and data that machines can trust.
What happened
Three signals landed at roughly the same time:
- Ahrefs studied 137,000 domains and reported that 28% had deployed
llms.txt, yet 97% of those files received no visits in May 2026. Of the small set that did get visits, Ahrefs found that AI crawlers were not the whole story, and that many crawlers do not appear to actively search for missingllms.txtfiles. - Search Engine Land covered research from Profound's Jonathan Clark showing a strong relationship between Claude visibility and Brave Search rankings. The same report said Claude triggered web search far less often than ChatGPT in the tested prompts, and that Claude citations overlapped more with Google results than with ChatGPT results.
- Search Engine Land also reported that OpenAI's ads manager beta added product-feed ads, allowing advertisers to upload product catalogs so ads can be generated from feed data instead of one ad at a time.
None of these signals proves that one tactic now dominates AI visibility. But together they point in a useful direction: AI answer systems are still borrowing heavily from search infrastructure, crawl behavior, and structured commercial data.
The llms.txt lesson: useful file, weak priority signal
llms.txt is easy to like because it feels controllable. A team can create a file, list useful pages, and tell itself that the site is now prepared for large language models.
The problem is adoption. If a file exists but almost nobody requests it, it should not sit at the top of the GEO roadmap.
That does not mean llms.txt is useless. It may still help some crawlers, internal documentation, and future AI indexing workflows. It can also force a useful editorial exercise: deciding which pages best explain the company, products, use cases, pricing logic, and proof. But it should not distract from pages that already shape discovery.
A better rule for most teams:
| Task | Priority | Why |
|---|---|---|
| Make important pages crawlable and internally linked | High | Search and AI systems need discoverable source pages first. |
| Keep commercial and comparison pages current | High | Freshness and ranking-style prompts often trigger search behavior. |
| Add schema and clean product data | High | Product, review, FAQ, and organization data help machines parse the page. |
| Maintain | Medium | Low cost, but current crawler demand looks limited. |
| Build dozens of thin AI-only pages | Low | Thin pages rarely improve trust and can dilute crawl quality. |
If your team has already handled technical SEO basics, add a simple llms.txt. If not, fix the site first.
Claude visibility still looks search-led
The more useful signal is Claude's apparent dependence on search results. According to the reported Profound analysis, Claude often draws from Brave Search, and its cited pages overlap meaningfully with Google results.
That matters because many teams have been treating GEO as if it replaced SEO. It does not. At least for search-triggered answers, a model still needs sources. Those sources often come from search indexes, retrieval systems, or pages that already have enough authority and relevance to rank.
For Claude optimization, the playbook looks surprisingly familiar:
- Own pages that answer ranking, comparison, and freshness-driven queries.
- Keep titles and intros current when the query deserves a year or version signal.
- Build pages with quotable summaries, tables, and clear claims rather than dense brand copy.
- Track which URLs are visible in Google and Brave, not only which URLs mention your target entity.
- Test prompts repeatedly, because query fan-out can turn one user question into several search-like subqueries.
This is why AI search visibility should be audited beside traditional rankings. If a page cannot win or even appear in the search layer, it has a harder path into an AI answer.
Product feeds are becoming AI ad infrastructure
The OpenAI product-feed ads update points to a different part of the same pattern. AI platforms do not want every commercial answer or ad unit written manually. They want structured inputs: product titles, prices, availability, categories, images, descriptions, and landing pages.
For ecommerce and DTC brands, that is not a small detail. Feed quality may become as important for AI ad surfaces as landing-page quality is for paid search.
A product feed built for AI needs more than SKU names and prices. It should include:
- Plain-language product names that match how people ask questions.
- Category and attribute fields that map to comparison intent.
- Clean availability, shipping, and return information.
- Product descriptions that explain use cases, not only materials.
- Landing pages that support the feed's claims with visible evidence.
Bad feed data creates bad generated ads. Worse, it can create ads that send people to pages that do not answer the question they asked.
Auspia take: stop separating SEO, GEO, and feed ops
The mistake is building three separate workstreams: one team tweaks llms.txt, another team chases AI citations, and a performance team cleans product feeds only when ad platforms complain.
Auspia's view is simpler: AI visibility is now a shared operating layer across SEO, GEO, AEO, and paid discovery. The inputs overlap.
A page that ranks well, answers clearly, uses structured data, earns citations, and matches feed claims is more useful across every AI surface. A page that hides important details behind vague copy is weak everywhere.
Use llms.txt as a map, not as the territory.
What teams should do this week
Start with a seven-day audit instead of a six-month AI visibility program.

The fastest wins usually come from search, crawl, freshness, and feed hygiene rather than isolated AI files.
Day 1: identify the pages AI systems should cite
Pick 10 to 20 pages that should represent the brand in AI answers. Include homepage, product pages, comparison pages, category pages, pricing pages, best-use-case pages, and proof pages.
Do not start with every URL. Start with the pages that would be painful if an AI system ignored them.
Day 2: check crawl access
Review robots.txt, sitemap coverage, canonical tags, redirects, JavaScript rendering, and status codes. If you use llms.txt, confirm that it points to the same core pages and does not list stale URLs.
You can use an AI crawler and robots.txt checker to catch obvious access conflicts before deeper analysis.
Day 3: compare Google, Brave, and AI answer visibility
For each target prompt, check whether your preferred URL appears in search results and whether AI tools cite it. Keep the prompt set small and repeatable:
| Prompt type | Example pattern | Why it matters |
|---|---|---|
| Best/list | "best tools for X in 2026" | Often triggers retrieval and ranking-style answers. |
| Comparison | "X vs Y for ecommerce teams" | Pulls from pages with clear tables and claims. |
| Local/near me | "best X near me" | Useful for service and local brands. |
| Product fit | "which X is best for [use case]" | Connects organic content to feed and landing-page data. |
Day 4: refresh titles and summaries where freshness matters
Do not add a year everywhere. Add freshness only where users expect it: best tools, pricing, platform comparisons, market maps, regulations, product alternatives, and benchmarks.
The first 150 words matter. Write a direct answer, then show supporting detail.
Day 5: strengthen structured data
Check organization, product, FAQ, article, breadcrumb, review, and software application schema where relevant. Schema will not rescue a weak page, but it reduces ambiguity.
Day 6: align product feeds with landing pages
For ecommerce or SaaS catalogs, compare feed claims against page claims. If the feed says "for small agencies," the landing page should say the same thing and explain why.
Day 7: decide what to keep, pause, and test
Keep tactics that improve crawlability, ranking, citation clarity, and feed quality. Pause tactics that only create a feeling of AI readiness.
A good test has a prompt set, source URLs, target markets, measurement dates, and a clear before/after record. Without that, it is just an opinion.
A simple operating checklist
Use this checklist before adding another AI-search experiment:
- Can search engines and AI crawlers access the page?
- Does the page answer the target question in the opening section?
- Is the page visible in Google or Brave for related searches?
- Does the page contain quotable facts, tables, or comparison points?
- Are claims supported by visible evidence, not just brand adjectives?
- Does structured data match what users and crawlers see on the page?
- If the page is commercial, does the product feed say the same thing?
- Is
llms.txtaccurate, current, and limited to useful URLs?
What not to overreact to
Do not delete llms.txt because of one study. Also do not treat it as a growth channel.
Do not assume Claude, ChatGPT, Gemini, Perplexity, and future AI ad surfaces behave the same way. Their retrieval triggers, indexes, ranking signals, and commercial incentives differ.
Do not create AI-only pages that humans would never read. AI systems are becoming better at finding thin content, and humans already are.
FAQ
Is llms.txt useless for GEO?
No. It is a low-cost support file, but current evidence suggests most deployed files receive little or no traffic. Treat it as a secondary task after crawlability, rankings, structured data, and content quality.
Should we optimize for Brave Search because Claude may use it?
You should at least monitor Brave results for important prompts, especially if Claude visibility matters to your audience. But the broader lesson is not "Brave only." It is that AI answers often depend on search-visible pages.
Does traditional SEO still matter for AI search?
Yes. For search-triggered answers, SEO can influence what sources are available for retrieval and citation. GEO adds new measurement and formatting needs, but it does not remove the need to rank, be crawlable, and answer clearly.
What should ecommerce teams do about AI ads?
Clean product feeds now. Use clear product names, complete attributes, accurate availability, use-case descriptions, and landing pages that support feed claims. AI ad systems can only work with the data they receive.
How often should we audit AI visibility?
For active categories, run a lightweight weekly check on a fixed prompt set and a deeper monthly audit across search visibility, AI citations, crawler access, schema, and feed data.
Related sources
This article is based on public reports and industry coverage from Ahrefs, Search Engine Journal, and Search Engine Land about llms.txt usage, Claude search behavior, and OpenAI product-feed ads. The recommendations are Auspia's interpretation for SEO, GEO, AEO, ecommerce, and AI search teams.