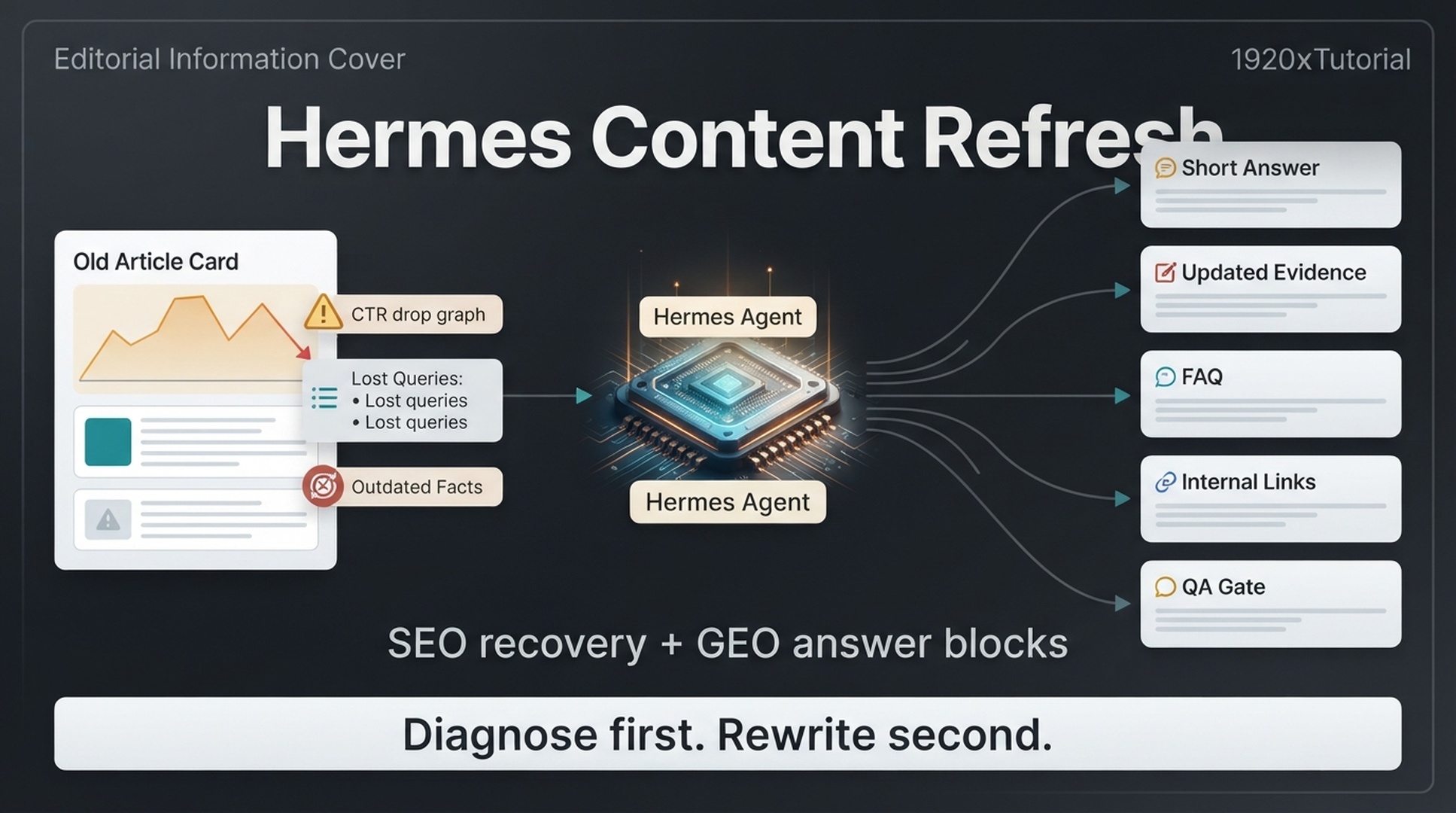
The 2026 Problem: AI Answers Can Turn Old Brand Data Into New Buyer Risk
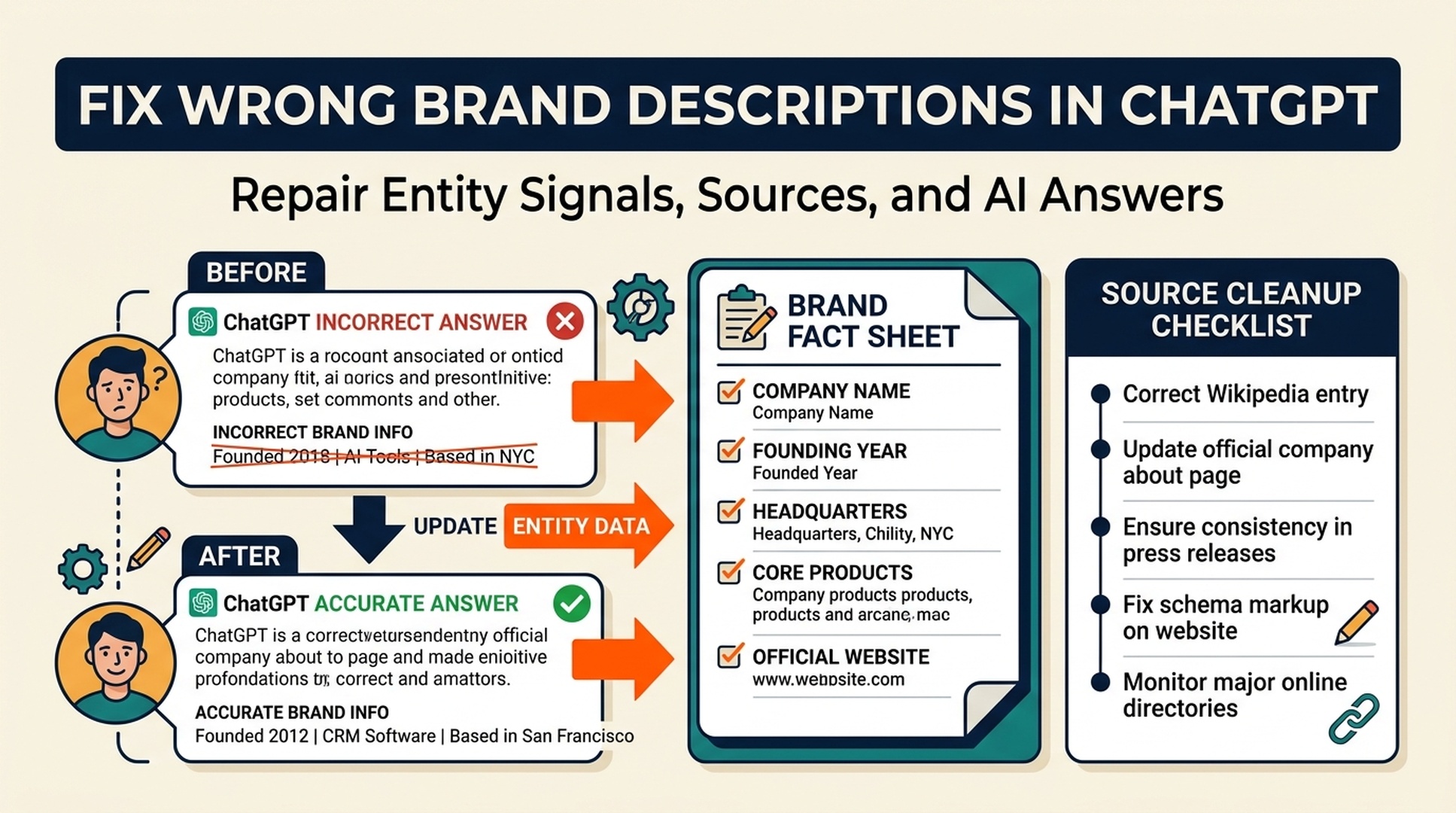
In 2026, one of the easiest GEO details to overlook is not keyword coverage. It is brand fact accuracy.
When AI search systems answer buyer questions, they often synthesize information from many pages: your site, old partner pages, outdated listings, comparison posts, scraped product databases, forum answers, media coverage, review sites, and competitor content. If those sources disagree, the answer can still sound confident. The buyer may see a wrong implementation timeline, an old price range, a missing integration, or a biased comparison before they ever reach your website.
That is AI data pollution in a GEO context: polluted or inconsistent source material gets retrieved, blended, and repeated as if it were current knowledge. For B2B and SaaS brands, this is not just a reputation issue. It can affect demo intent, sales objections, procurement trust, and which vendor gets shortlisted.
The practical fix is to build a 2026 GEO truth layer: a controlled set of current brand facts, structured pages, third-party proof, correction workflows, and recurring AI-answer monitoring. GEO is no longer only about being mentioned. It is about making sure the mention is accurate enough to move a buyer forward.
Caption: A 2026 GEO program should treat inaccurate AI answers as a repairable source-quality problem, not just a visibility problem.
What AI Data Pollution Looks Like In GEO
AI data pollution usually starts small. A brand changes packaging, pricing, positioning, or product capabilities. The official website updates, but older pages remain live elsewhere. A few affiliates keep the old copy. A review site summarizes the product incorrectly. A competitor comparison page frames the brand around an outdated weakness. A help-center article uses legacy terminology. Then AI systems retrieve pieces of that mixed record.
The result is brand fact drift: the public information layer slowly separates from the current business reality.
Common symptoms include:
| Polluted signal | How it appears in AI answers | Why it hurts growth |
|---|---|---|
| Outdated pricing | AI quotes old plans, wrong free-trial rules, or inaccurate enterprise ranges | Buyers self-disqualify before contacting sales |
| Wrong feature scope | AI says the product lacks a feature that now exists, or supports one that does not | Sales teams inherit preventable objections |
| Weak category language | AI describes the brand with generic or outdated positioning | The brand loses differentiation in comparison prompts |
| Biased competitor framing | AI repeats old comparison claims from third-party pages | High-intent evaluation traffic shifts toward competitors |
| Inconsistent implementation facts | AI gives the wrong setup time, integration path, or compliance status | Procurement and technical buyers lose confidence |
| Unclear source hierarchy | AI cites secondary pages instead of official documentation | Correct pages fail to become the trusted reference |
This is why a brand can have decent SEO traffic and still perform poorly in AI search. Ranking pages are not enough if the retrieved facts are noisy.
Why This Detail Is Easy To Miss
Many GEO programs start with prompt tracking: “Does ChatGPT mention us?” “Does Perplexity cite us?” “Do we appear in AI Overviews?” Those questions matter, but they can hide a second problem.
A brand mention can be negative, wrong, partial, stale, or commercially useless.
For example, a vendor might appear in an AI answer for “best workflow automation tools for finance teams,” but the answer might also say the vendor is only suitable for small teams, lacks API support, or has unclear security documentation. If those claims are wrong, the visibility win becomes a conversion leak.
The deeper issue is that AI answers are built from source confidence, not brand preference. Models and retrieval systems look for repeated, accessible, semantically clear, and corroborated information. If wrong facts are easier to find than corrected facts, the wrong facts can win.
Auspia’s view: in 2026, GEO teams should track three layers at the same time:
- Presence: whether the brand appears in relevant AI answers.
- Accuracy: whether the answer reflects current brand facts.
- Commercial direction: whether the answer helps a qualified buyer take the next step.
Most teams over-measure presence and under-measure accuracy.
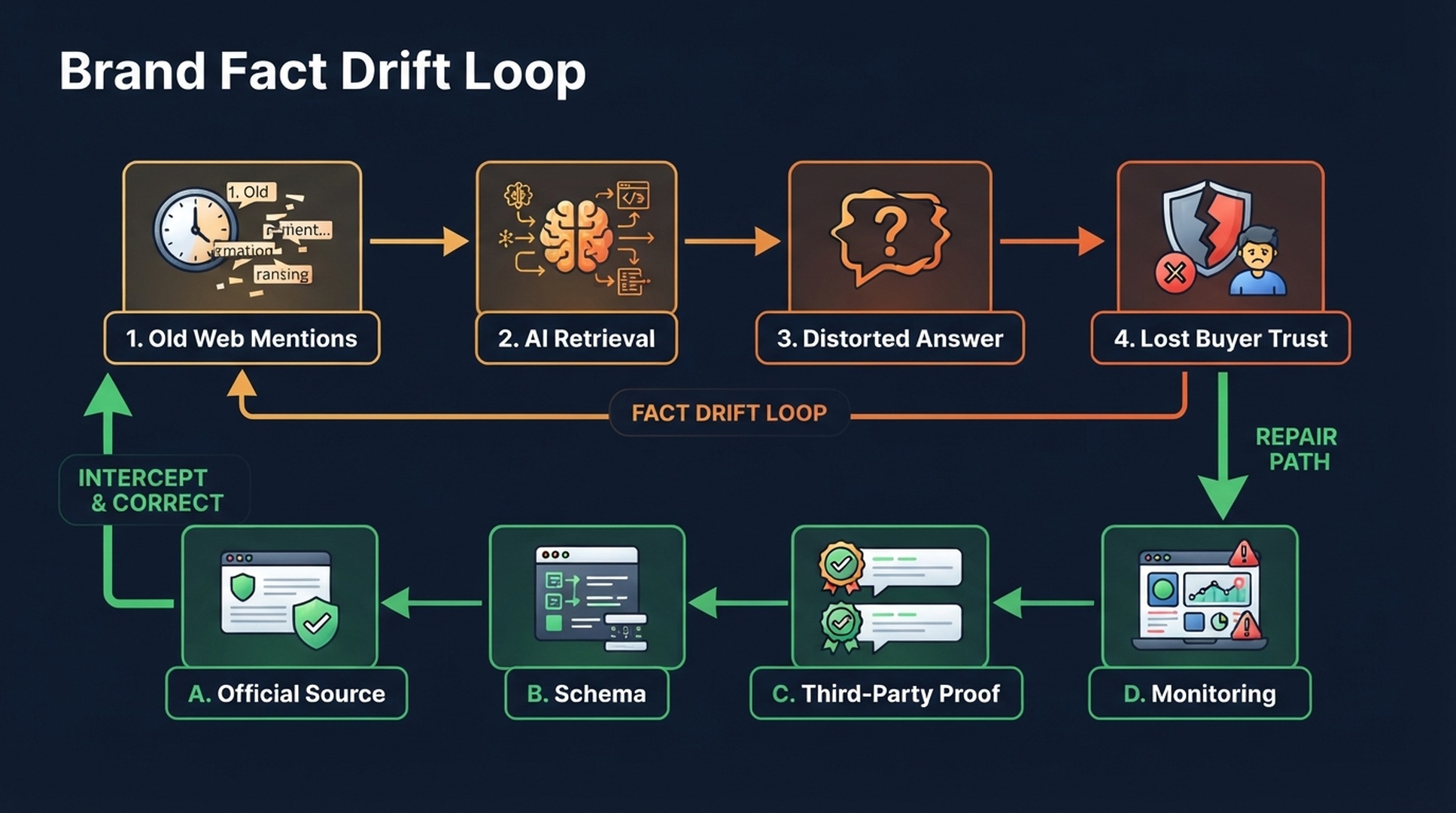
The Brand Fact Drift Loop
AI data pollution usually follows a repeatable loop.
Caption: Brand fact drift compounds when old pages, weak source hierarchy, and unmonitored AI answers reinforce each other.
Here is the loop in plain English:
- The brand changes faster than the web updates. Product, pricing, packaging, integrations, compliance notes, and customer segments evolve.
- Old sources remain crawlable. Old PDFs, comparison pages, listing profiles, partner pages, media mentions, and forum answers keep circulating.
- AI retrieval finds mixed evidence. The system sees both current and stale claims, often without a perfect understanding of recency or authority.
- The answer compresses nuance. Conflicting facts become a confident sentence.
- Buyers act on the compressed answer. They exclude the brand, ask the wrong question, or choose a competitor.
- The polluted answer creates more downstream content. People copy the summary into docs, posts, sales notes, and reviews, which can reinforce the pattern.
Breaking this loop requires more than publishing one corrected blog post. You need a repeatable repair system.
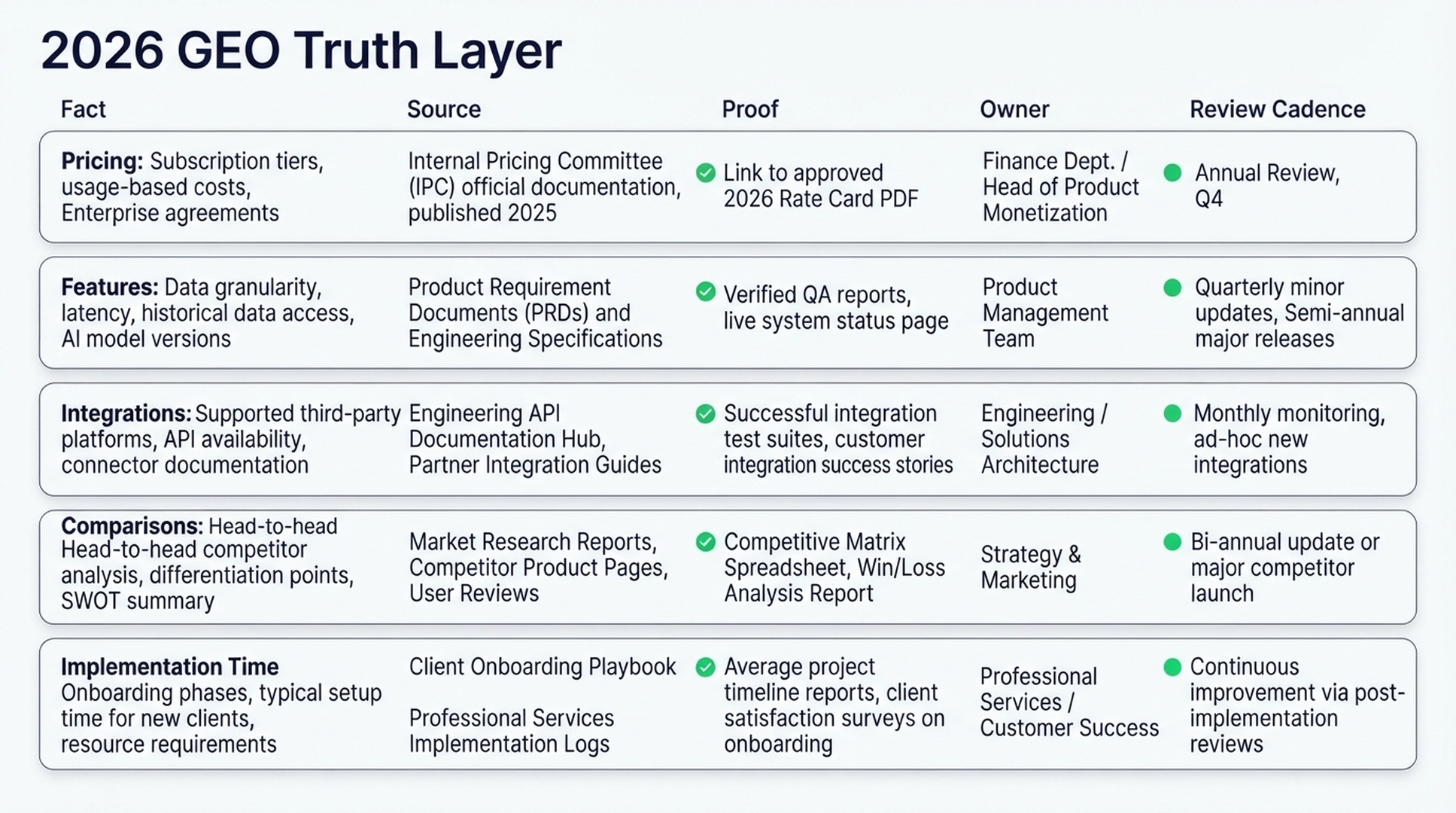
Build A 2026 GEO Truth Layer
A GEO truth layer is a simple operating asset: one source of current, structured, externally verifiable brand facts that both humans and AI systems can understand.
It should not live only in a slide deck. It should be reflected across your website, documentation, schema, comparison pages, partner profiles, review-site descriptions, PR boilerplate, help-center language, and sales enablement assets.
A practical truth layer includes five parts:
| Truth layer asset | What it controls | Example fields |
|---|---|---|
| Brand fact registry | The canonical version of important claims | Category, target users, use cases, pricing boundaries, deployment model |
| Official proof pages | Pages that AI systems can retrieve and cite | Product pages, docs, security pages, integration pages, customer stories |
| Structured data and clear entities | Machine-readable context | Organization schema, Product schema, FAQ schema, sameAs, author/publisher clarity |
| Third-party corroboration | Evidence beyond your own site | Partner listings, analyst mentions, review profiles, community answers |
| Monitoring and correction queue | The workflow for finding and fixing distortion | Prompt checks, cited-source logs, issue owner, priority, fix status |
A lightweight spreadsheet is enough to start. The key is ownership. Every critical fact needs a source URL, a proof type, a responsible owner, and a review cadence.
Five Small Fixes That Often Improve AI Answer Accuracy
You do not need to rebuild the entire website before acting. Start with the facts that change buyer decisions.
1. Create A “Current Facts” Page For Your Category
Build one page that clearly states what your product is, who it is for, what it does, what it does not do, and which facts were last updated. Use direct language, not brochure copy.
Good sections include:
- What the product does in one sentence
- Primary use cases
- Best-fit customers
- Deployment and integration notes
- Pricing or pricing-boundary explanation
- Security and compliance links
- Common misconceptions
- Last reviewed date
This page can become the reference point for internal teams and external corrections.
2. Rewrite Comparison Pages Around Verifiable Criteria
AI systems frequently use comparison pages for vendor-evaluation prompts. If your comparisons are vague, defensive, or purely promotional, they are less useful as source material.
Make comparison content easier to extract:
- State the comparison criteria before the conclusion.
- Separate facts from opinion.
- Link to official docs for features, integrations, pricing, and compliance.
- Include “when not to choose us” where appropriate.
- Avoid attacking competitors with claims you cannot verify.
Clear comparison pages can reduce the chance that AI answers repeat a competitor’s framing as the neutral market view.
3. Add Misconception Blocks To High-Intent Pages
If AI systems repeatedly make the same mistake, answer that mistake directly on the relevant page.
Example format:
Common misconception: Some older sources describe Product X as only suitable for small teams. As of the 2026 product line, Product X supports enterprise SSO, role-based access control, audit logs, and private deployment options. See the security documentation and enterprise deployment guide for details.
This works because it gives retrieval systems a clear correction, a current date, and supporting links.
4. Clean Up Third-Party Profiles Before Publishing More Content
Many teams publish new GEO content while ignoring outdated profiles on review sites, marketplaces, partner directories, GitHub pages, app stores, documentation mirrors, and old media kits.
Make a list of the 20 pages most likely to be retrieved for brand and comparison prompts. Update those before creating another generic thought-leadership post.
Prioritize pages that already rank, get cited, or appear in AI answer sources.
5. Track Accuracy, Not Just Mentions
A prompt tracker should not only record whether your brand appears. Add accuracy labels.
Use a simple scoring system:
| Score | Meaning | Action |
|---|---|---|
| 0 | Brand absent | Add or strengthen relevant source content |
| 1 | Brand mentioned but wrong | Identify the wrong claim and source path |
| 2 | Brand mentioned but incomplete | Add missing proof or clearer page sections |
| 3 | Brand accurate but weakly positioned | Improve comparison criteria and use-case clarity |
| 4 | Brand accurate and commercially useful | Monitor and preserve source consistency |
This turns GEO from a vanity visibility report into an operating workflow.
A 14-Day Repair Sprint For Distorted Brand Information
If you suspect AI search is misrepresenting your brand, run a focused two-week sprint.
Days 1-2: collect prompts
Gather 30-50 prompts from sales calls, SEM queries, support tickets, comparison searches, and buyer objections. Include brand, category, feature, pricing, integration, implementation, and competitor prompts.
Days 3-4: capture AI answers
Test the prompts across the AI surfaces your buyers use. Record the answer, brand position, cited sources if available, wrong claims, and commercial impact.
Days 5-6: trace polluted sources
For each wrong claim, identify the likely source family: official page, old PDF, review profile, comparison article, partner page, forum answer, marketplace listing, or competitor content.
Days 7-9: repair official sources
Update the pages you control first. Add clearer definitions, updated dates, schema, FAQ blocks, misconception sections, and proof links.
Days 10-11: repair external profiles
Update high-authority third-party profiles, partner descriptions, review-site boilerplate, and marketplace listings. Where direct editing is impossible, publish a better public reference and ask partners to use it.
Days 12-13: publish corroborating proof
Create one or two high-quality proof assets: a customer story, integration guide, security explainer, implementation guide, benchmark page, or comparison article. Make it factual and citable.
Day 14: retest and prioritize the queue
Run the prompt set again. Some answers may not change immediately, but you should see which issues are source gaps, crawl/retrieval delays, or third-party contamination problems.
For teams that want a faster baseline, use a visibility audit tool such as Auspia’s AI Search Visibility Checker to turn prompts, answers, and brand presence checks into a repeatable review process.
What To Measure After The Cleanup
Do not expect every AI answer to update overnight. Different systems use different retrieval methods, indexes, citations, browsing behavior, and answer-generation rules. Measure trend direction rather than one perfect snapshot.
Track these metrics weekly:
| Metric | What it tells you |
|---|---|
| Brand answer accuracy rate | Whether AI answers reflect current facts |
| Wrong-claim frequency | Which distortions are still repeating |
| Source concentration | Whether AI systems cite official and high-quality sources |
| High-intent prompt coverage | Whether buyer-stage questions include your brand |
| Commercial usefulness score | Whether answers help a buyer evaluate, compare, or contact you |
| Correction latency | How long it takes for repaired sources to influence AI answers |
The strongest GEO programs create a feedback loop: AI answer audit, source repair, content proof, third-party correction, retest, and sales-team learning.
Common Mistakes
Mistake 1: treating GEO as PR distribution. Publishing more articles does not fix polluted facts if the source hierarchy remains messy.
Mistake 2: correcting only the official website. AI answers often draw from external sources. Review sites, partner pages, and old comparison content need cleanup too.
Mistake 3: using vague brand positioning. “All-in-one AI platform” is not a fact. AI systems need specific use cases, entities, integrations, industries, and constraints.
Mistake 4: hiding important facts inside PDFs or images. If the information matters for AI answers, make it crawlable and extractable in HTML.
Mistake 5: measuring only share of voice. A visible but inaccurate brand answer can damage the buyer journey more than absence.
FAQ
What is AI data pollution in GEO?
AI data pollution in GEO is the presence of outdated, wrong, biased, duplicated, or inconsistent public information that AI search systems may retrieve and synthesize into brand answers. It becomes a GEO problem when those answers affect brand visibility, buyer trust, or conversion.
Why do AI tools give wrong brand information?
AI tools can give wrong brand information when public sources disagree, official pages are unclear, older pages remain accessible, third-party profiles are outdated, or comparison content is easier to retrieve than current documentation. The answer may sound confident even when the underlying evidence is mixed.
How do you fix distorted brand facts in AI search?
Start by auditing high-intent prompts, recording wrong claims, tracing likely source families, updating official pages, cleaning third-party profiles, adding structured data, publishing corroborating proof, and retesting the same prompts on a recurring schedule.
Should GEO teams focus on citations or accuracy first?
Accuracy should come first for brand-critical prompts. More citations are not useful if the cited information is wrong or outdated. Once the brand truth layer is stable, citation growth becomes safer and more commercially valuable.
How often should brands monitor AI answer accuracy in 2026?
For high-growth B2B, SaaS, healthcare, finance, ecommerce, and technical categories, weekly monitoring is a practical baseline for high-intent prompts. Monthly monitoring may be enough for lower-risk evergreen categories, but any major product, pricing, or positioning change should trigger a fresh audit.
Final Takeaway
The overlooked GEO detail for 2026 is not whether AI systems can mention your brand. It is whether they can repeat the right version of your brand.
If your public information layer is polluted, AI search can amplify the wrong story at the exact moment a buyer is evaluating vendors. The fix is operational: build a truth layer, clean the highest-risk sources, structure important facts, corroborate them across trusted channels, and monitor answer accuracy over time.
That is how GEO moves from “visibility work” to brand information governance.
Author: Lydia Hart, Brand Entity Strategist for 200+ Entity Audits at Auspia. Lydia writes about brand facts, entity consistency, about pages, category language, and knowledge graph readiness.