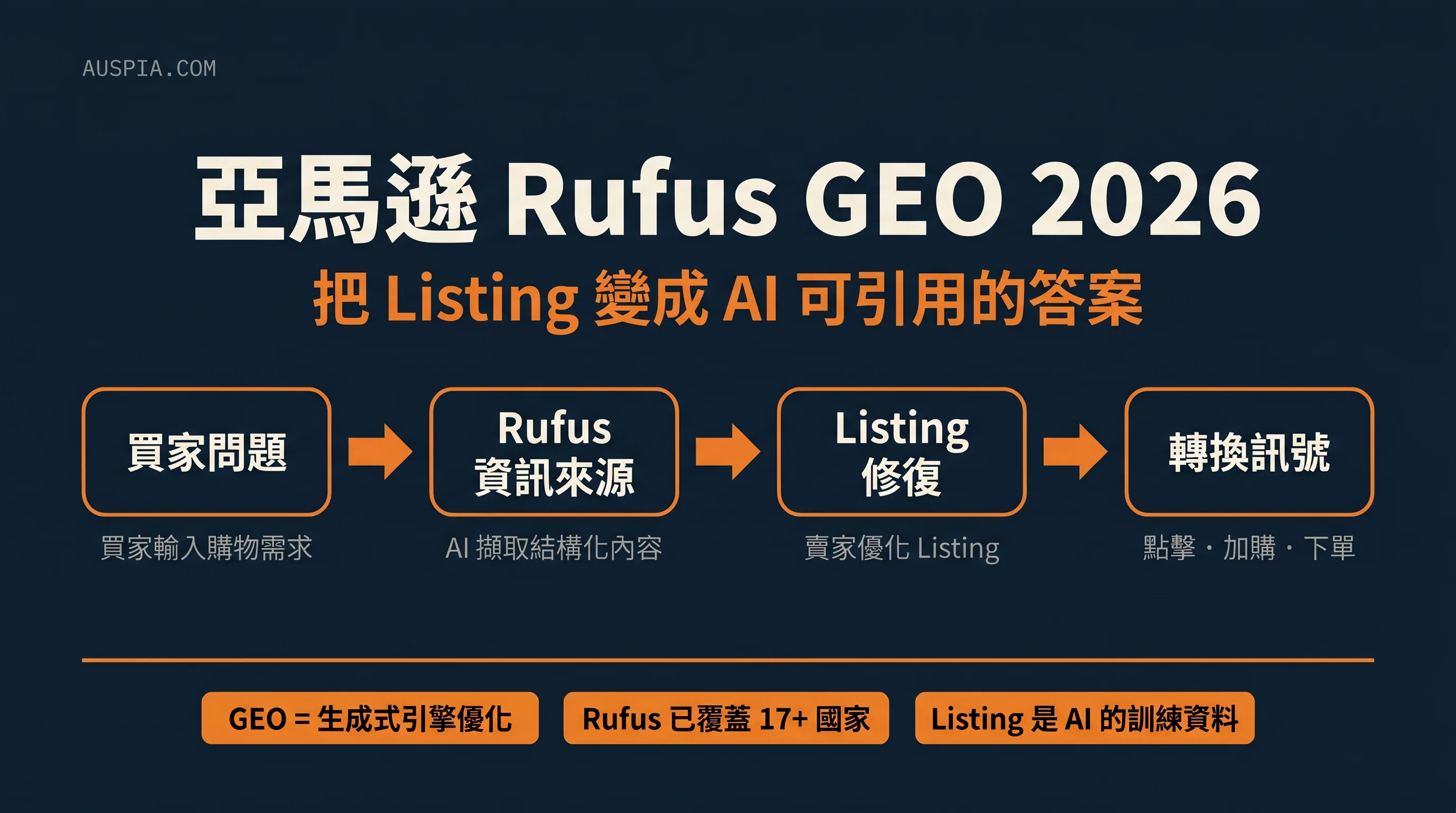
快速回答
Generative Engine Optimization(GEO)是让你的内容更可能作为被引用来源出现在 AI 生成答案中的实践。SEO 仍然重要,但 GEO 增加了新一层:页面必须容易抓取、容易提取、容易验证,并且有用到足以让答案引擎引用。
如果你从零开始,不要先写 50 篇新文章。先做五件事:
- 确认 AI 和搜索爬虫能访问重要页面。
- 重写优先页面,让每个章节都以直接答案开头。
- 添加具体证据:日期、数字、定义、作者和来源。
- 在合适场景添加 Article、FAQ、Product、Organization 或 HowTo schema。
- 创建一个指向最佳页面的
llms.txt文件。
这就是实用版本。GEO 不是魔法。它主要是更好的信息架构、更干净的证据,以及更少模糊写作。
SEO 试图赢得排名结果和点击。GEO 试图进入检索集合,并成为答案中的被引用来源。
用直白话解释 GEO
GEO 意味着针对 ChatGPT search、Perplexity、Google AI Overviews、Gemini、具备网页访问能力的 Claude,以及其他基于检索的助手优化内容。
传统搜索通常是这样工作的:用户搜索,浏览结果页,点击链接,然后判断页面是否有帮助。AI 搜索压缩了这段旅程。用户提问,系统检索来源,写出答案,并可能显示引用。如果你的页面不在检索集合中,用户可能永远看不到你。
第一篇正式提出 GEO 的学术论文于 2023 年 11 月 16 日提交到 arXiv,后来被 KDD 2024 接收。论文把生成式引擎描述为会综合多个来源信息的系统,并研究如何提高来源在生成回答中的可见性。其实验报告显示,根据策略和领域不同,生成式引擎回答中的可见性最多可提升 40%。
对增长团队来说,结论很简单:页面现在要竞争两次。第一,竞争被发现。第二,竞争被信任到足以被引用。
SEO vs GEO:什么变了,什么没变
GEO 不替代 SEO。它改变的是终点线。
| 领域 | SEO 目标 | GEO 目标 | 该做什么 |
| --- | --- | --- | --- |
| 可见性 | 在结果页排名 | 出现在综合答案中 | 写出能独立成立的章节 |
| 内容格式 | 综合页面 | 带证明的可提取答案 | 把答案放在第一句 |
| 权威 | 链接、声誉、主题深度 | 来源信任加可验证主张 | 添加作者、日期、引用、schema |
| 技术访问 | 可抓取、可索引页面 | 可抓取、可索引、机器可读页面 | 检查 robots、sitemap、schema、llms.txt |
| 衡量 | 排名、点击、展示 | AI 引用、referral traffic、品牌提及 | 追踪 AI referrers 并运行 prompt tests |
一个页面可以排名,却仍然在 GEO 上失败,因为有用答案埋在长开头下面。一个页面也可能在成为主要 SEO 胜者之前就被 AI 引用,尤其是在狭窄 B2B 主题里,如果它解释清楚、证据比大站更好。
这就是 Auspia 把 GEO 看作 SEO 之上层级的原因,而不是一种独立宗教。
AI 答案引擎如何选择来源
大多数 AI 答案产品都会使用某种 retrieval-augmented generation。细节不同,但对营销人员来说,工作模型足够清楚:
- 用户提出问题。
- 系统把问题转换成检索任务。
- 它从搜索索引、合作数据、浏览工具或内部来源池收集候选文档。
- 它提取看起来相关的段落。
- 它写出答案,并可能附上引用。
这条链路里,你的内容可能在四个地方失败。
| 失败点 | 表现 | 修复 |
| --- | --- | --- |
| 访问失败 | 爬虫无法到达页面 | 在 robots.txt 和 sitemap.xml 中开放正确页面 |
| 匹配失败 | 页面没有清楚回答查询 | 添加答案优先标题和 FAQ 区块 |
| 信任失败 | 主张没有支持或太促销 | 添加来源、日期、作者细节和平衡措辞 |
| 提取失败 | 页面视觉丰富但文本贫乏 | 添加 HTML 文本、schema、transcripts 和干净 markdown-like 结构 |
这里有一个不舒服的事实:AI 系统不会奖励你最好看的页面。它们奖励自己能解析并解释为什么使用的页面。
第 1 步:打开门,但不要放弃控制
从爬虫访问开始。访问:
https://yourdomain.com/robots.txt https://yourdomain.com/sitemap.xml
你的 robots 文件不应该意外阻止你希望被引用的页面。Google 官方文档解释,robots.txt 告诉爬虫可以访问哪些 URL,主要用于抓取管理,并不是隐藏敏感页面的正确方式。这个区别对 GEO 也重要。如果页面有商业价值,在 robots 层阻止它可能会把它移出来源池。
简单起点如下:
`User-agent: * Allow: /
Sitemap: https://yourdomain.com/sitemap.xml`
然后根据你的政策检查具名 AI 爬虫。一些品牌允许搜索和 AI 答案爬虫,同时阻止训练爬虫。另一些品牌做出更严格的法律选择。这都可以。错误在于没有政策,后来才发现最好的页面被旧插件设置阻止了。
对 WordPress,还要检查“discourage search engines”设置和任何 SEO 插件的 robots 编辑器。对 headless 网站,检查构建时 robots 生成。对大型网站,审查 staging、faceted navigation 和内部搜索 URL,避免打开抓取陷阱。
第 2 步:写出可以被引用的页面
AI 答案引擎引用段落,而不是品牌战略文档。可引用段落有四个特征:
- 它直接回答一个问题。
- 没有前一段也能理解。
- 包含主张的条件或限制。
- 避免销售语言。
弱版本:
我们的平台以强大 AI 能力改变现代内容工作流,帮助团队释放新的增长机会。
GEO-ready 版本:
内容审计应该按搜索意图、流量趋势、转化角色和新鲜度给页面分组。对 B2B 网站来说,每 30 到 60 天审查高意图产品页、对比页和解决方案页,因为价格、竞争对手和买家问题变化很快。
第二个版本给 AI 有用内容可引用。它定义任务、命名维度、给出时间窗口,并解释原因。
Auspia 的规则是:每个重要章节都应该通过“复制一个段落”测试。如果一个段落被放进 AI 答案里,它是否仍然说得通?如果不行,就重写。
第 3 步:在答案需要信任的地方添加证据
最初的 GEO 论文发现,优化方法因领域而异。这和实践观察一致。旅游页面、SaaS 对比页和医疗页面需要的证明不一样。
使用这个证据阶梯:
| 主张类型 | 弱证据 | 更好证据 |
| --- | --- | --- |
| 定义 | “专家说” | 具名标准、论文、文档页面或术语表 |
| 表现主张 | “很快” | 测试设置、日期、样本量、指标和限制 |
| 产品主张 | 功能列表 | 截图、文档、changelog、价格页和用例 |
| 本地/服务主张 | 泛泛 landing page | 地址、服务区域、许可证、评论、项目和 FAQ |
| 研究主张 | 博客摘要 | 论文、数据集、作者和发布日期链接 |
不要伪造权威。AI 系统越来越擅长忽略薄主张,人类读者也早就擅长。清楚限制通常会提高信任:“这个 benchmark 使用项目管理品类的 120 个英文查询”比“我们的工具是 best in class”更强。
第 4 步:建立技术 GEO 文件
有用的 GEO 设置包含四个技术组件。
robots.txt
这是访问层。确认重要公开页面可抓取。低价值或私有区域应该被有意阻止,而不是意外阻止。
sitemap.xml
这是发现层。包含 canonical URLs,在 CMS 支持时加入更新日期,并保持 sitemap 干净。不要让爬虫从数千个垃圾 URL 中筛选。
structured data
这是机器描述层。使用与页面匹配的 schema,而不是能找到多少类型就加多少。大多数增长型网站应从这些开始:
- 编辑页面使用
Article或BlogPosting - 有真实 FAQ 区块时使用
FAQPage - 品牌身份使用
Organization - 商业页面使用
Product、SoftwareApplication或Service - 网站结构使用
BreadcrumbList
llms.txt
llms.txt 是建议放在 /llms.txt 的 markdown 文件。Jeremy Howard 于 2024 年 9 月 3 日发布了这个提案。其想法是给 LLM 一个简洁的网站地图:网站是什么、哪些页面重要,以及干净 markdown 资源在哪里。
实用版本可以很短:
`# Acme Analytics
Acme Analytics 帮助 B2B SaaS 团队衡量产品驱动收入、激活和留存。
核心页面
指南
- 激活指标指南 :关于激活、价值实现时间和同期群分析的定义与公式。
可选
- 公司博客 : 额外产品更新和评论。`
保持诚实。llms.txt 是指南,不是排名 hack。当它指向真正有用的页面时效果最好。
把它当作第一轮审计:访问、答案质量、证据和实体一致性。
第 5 步:创建 AI-friendly FAQ 区块
FAQ 区块有效,因为它们匹配人们向 AI 系统提问的方式。它们也迫使作者停止隐藏答案。
好的 FAQ 答案简短、具体、独立完整。先给答案,再补充细节。
| 糟糕 FAQ 问题 | 更好 FAQ 问题 |
| --- | --- |
| “GEO 的战略重要性是什么?” | “什么是 GEO?” |
| “我们的解决方案如何帮助现代团队?” | “如何让页面更容易被 AI 工具引用?” |
| “高级优化有什么好处?” | “基础 GEO 清理需要多久?” |
对大多数页面来说,五到八个问题就够了。覆盖定义、流程、时间、成本、错误和对比问题。不要为了填空间添加 20 个薄 FAQ。
第 6 步:按平台调整,但不要追逐每个传闻
不同答案引擎有不同来源池。Perplexity 通常更像重引用的研究助手。Google AI Overviews 接近 Google Search 生态。ChatGPT search 可能根据查询和产品状态,组合 Bing、第一方浏览、合作内容和模型行为。企业助手可能比公开网页更依赖私有文档。
这意味着同一个页面不会在所有地方表现一样。
有用的平台计划如下:
| 平台类型 | 通常有帮助的因素 | 要注意什么 |
| --- | --- | --- |
| 搜索支持的 AI 答案 | 强 SEO 页面、schema、新鲜度、爬虫访问 | 摘要弱或答案埋得深的页面 |
| 引用优先 AI 工具 | 清楚段落、来源链接、带日期主张 | 无支持主张和模糊开头 |
| 社群权重高的结果 | 第三方提及、评论、讨论 | 只有品牌自说自话、没有外部证据 |
| 企业 AI 检索 | 干净 docs、PDF、knowledge-base structure | 权限错误和重复文件 |
团队常跳过的一点是:自有网站之外的一致性。如果你的价格、产品品类、创始人姓名、地址和功能主张在目录、评论网站、文档和社交 profiles 中互相不同,AI 系统就必须解决混乱。让核心事实在网站、知识库、合作伙伴页面和主要 profiles 中保持一致。
第 7 步:衡量 GEO,但不要假装它很精确
GEO 衡量仍然混乱。但这不是不衡量的理由。
追踪四个信号:
- 来自
chatgpt.com、perplexity.ai、claude.ai、gemini.google.com等域名,以及 analytics 中出现的 AI browser surfaces 的 referral traffic。 - Prompt visibility:每周运行固定 prompt set,记录品牌或 URL 是否出现。
- Citation quality:记录哪个页面被引用、使用了什么主张,以及引用是否准确。
- Assisted conversions:标记 AI referrals,并将线索质量与自然搜索和付费渠道对比。
一开始用简单表格即可。列:日期、prompt、engine、location、cited source、answer position、competitor sources、notes。四周后,模式会变得清楚。你会看到哪些主题引用你,哪些竞争对手持续出现,哪些页面需要更强答案块。
如果想要更快的第一眼,可以用 AI Search Visibility Checker 建立初始 prompt set,然后在做决策前手动审查重要 prompts。
10 点 GEO 启动清单
第一周使用这份清单。
| 优先级 | 任务 | 完成 |
| --- | --- | --- |
| 1 | 选择 10 个优先页面:产品、对比、解决方案、指南和 FAQ 页面 | |
| 2 | 确认这些页面可抓取并在 sitemap 中 | |
| 3 | 重写每个页面的前 100 字,让答案立即出现 | |
| 4 | 添加或更新作者、日期和组织细节 | |
| 5 | 为统计、定义和 benchmark 主张添加来源 | |
| 6 | 给有明确用户问题的页面添加 FAQ 区块 | |
| 7 | 验证 Article、FAQ、Product、Organization 或 Breadcrumb schema | |
| 8 | 发布 /llms.txt,包含最佳页面和简短描述 | |
| 9 | 为 AI referral domains 设置 GA4 exploration | |
| 10 | 每周运行 25 个 prompts 并记录引用 | |
在把它变成公司级项目前,先完成前十个页面。团队从战略工作坊开始时,GEO 很容易变空。它在重写买家和答案引擎已经关心的页面时才有用。
常见错误
最大错误是把 GEO 当成技巧。添加 llms.txt 无法拯救薄内容。Schema 无法让没有支持的主张变可信。发布 100 篇 AI 写的术语页,可能制造的清理工作多于可见性。
第二个错误是过度照搬 SEO 内容模式。长开头、关键词重复和宽泛主题覆盖,在某些情况下仍然能排名,但 AI 答案引擎需要紧凑、可辩护的段落。
第三个错误是忽略第三方证据。你自己的网站可以定义你的产品,但外部来源常常验证品类。评论、分析师页面、合作伙伴页面、marketplace listings、documentation 和客户故事,都能帮助答案引擎理解你是什么。
Auspia 结论
最好的第一个 GEO 项目并不光鲜。选择十个页面。让它们可抓取。让答案明显。添加证明。添加 schema。发布 llms.txt。追踪 prompts 一个月。
这项工作给 AI 系统一个更干净的业务版本可读,也给人类买家一个更好的页面。这就是为什么即使归因尚不完美,GEO 也值得做。
FAQ
什么是 GEO?
GEO 是 Generative Engine Optimization,指改进内容,让 AI 答案引擎能在生成答案中找到、理解、信任并引用它。
GEO 和 SEO 不同吗?
不同,但它依赖 SEO 基础。SEO 关注排名和点击。GEO 关注进入 AI 生成答案并被引用。如果同一页面可抓取、有权威,并用直接答案写成,它可以同时支持两者。
GEO 需要 llms.txt 吗?
不是严格必需,但它是低成本的有用补充。好的 llms.txt 文件给 AI 系统一份简洁网站地图,列出最重要页面并解释每个页面包含什么。
基础 GEO 清理需要多久?
10 个优先页面的基础清理通常需要一到两周。最快胜利包括 robots 和 sitemap 检查、答案优先重写、FAQ 添加、schema 验证和 llms.txt 发布。
AI 工具会引用没有 Google 排名的页面吗?
会,尤其是在小众主题中。但强 SEO 信号仍然帮助发现和信任。把 SEO 当成基础,把 GEO 当成引用层。
应该先衡量什么?
从 prompt visibility、被引用 URL、AI referral traffic 和 assisted conversions 开始。不要依赖单一指标。AI 搜索归因仍不完整,所以要把多个信号结合起来看。
来源
- GEO: Generative Engine Optimization, arXiv:2311.09735
- The /llms.txt file proposal
- Google Search Central: Introduction to robots.txt