2026 年的問題:AI 回答會把舊品牌資料變成新的買家風險
在 2026 年,GEO 中最容易被忽略的細節之一不是關鍵字覆蓋,而是品牌事實的準確性。
當 AI 搜尋系統回答買家問題時,往往會綜合許多頁面的資訊:你的網站、舊合作夥伴頁面、過期目錄、比較文章、被抓取的產品資料庫、論壇回答、媒體報導、評論網站以及競品內容。即使這些來源彼此矛盾,AI 回答仍可能顯得非常篤定。買家可能在造訪你的網站之前,就看到錯誤的導入週期、舊價格區間、缺失的整合能力,或帶有偏見的競品比較。
這就是 GEO 語境下的 AI 資料污染:被污染或不一致的來源被檢索、混合,並被當作當前知識反覆輸出。對 B2B 和 SaaS 品牌來說,這不只是聲譽問題。它會影響預約 demo 的意願、銷售異議、採購信任,以及品牌是否進入供應商候選名單。
務實的修復方式,是建立一個 2026 GEO 真相層:一組受控的當前品牌事實、結構化頁面、第三方證據、糾錯流程,以及持續的 AI 回答監測。GEO 不再只是「被提到」。它還要求這次提及足夠準確,能讓買家繼續往下一步前進。
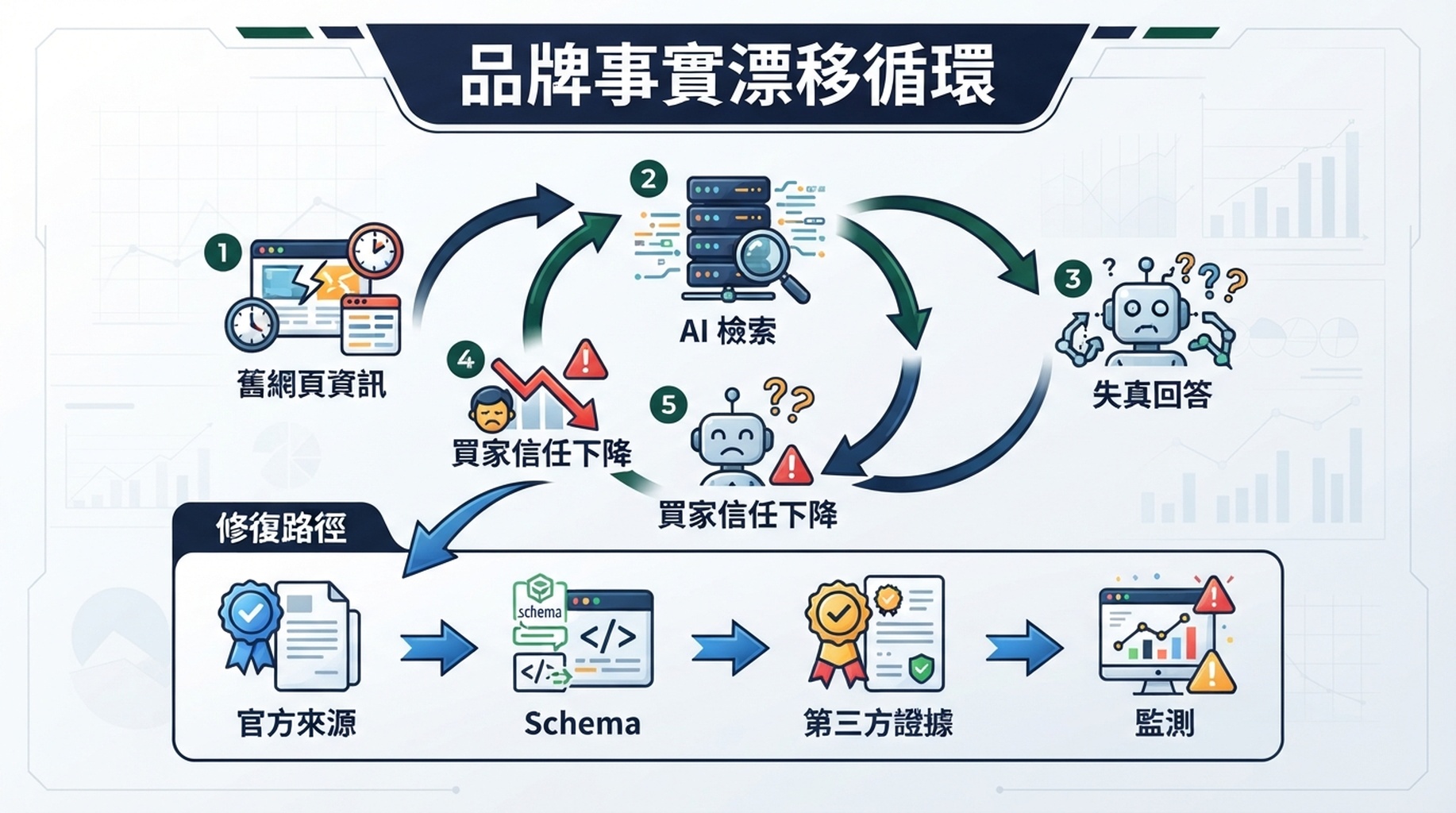
說明:2026 年的 GEO 專案應該把不準確的 AI 回答視為可修復的資訊源品質問題,而不只是能見度問題。
GEO 中的 AI 資料污染長什麼樣
AI 資料污染通常從很小的偏差開始。品牌調整了包裝、定價、定位或產品能力。官網更新了,但舊頁面仍在其他地方存在。一些聯盟頁面繼續使用舊文案。評論網站錯誤概括了產品。競品比較頁用已經過時的弱點來描述品牌。說明中心文章仍使用舊術語。隨後,AI 系統會檢索到這批混雜記錄的一部分。
結果就是品牌事實漂移:公開資訊層逐漸脫離當前業務現實。
常見症狀包括:
| 被污染的訊號 | 在 AI 回答中的表現 | 為什麼傷害成長 |
|---|---|---|
| 過期定價 | AI 引用舊方案、錯誤試用規則或不準確的企業價區間 | 買家在聯絡銷售前就自我排除 |
| 錯誤功能範圍 | AI 說產品缺少已經具備的功能,或支援並不存在的功能 | 銷售團隊要處理本可避免的異議 |
| 薄弱的品類語言 | AI 用泛化或過時定位描述品牌 | 品牌在比較類問題中失去差異化 |
| 有偏見的競品框架 | AI 重複第三方頁面裡的舊比較說法 | 高意圖評估流量流向競品 |
| 不一致的導入資訊 | AI 給出錯誤設定時間、整合路徑或合規狀態 | 採購和技術買家信心下降 |
| 資訊源層級不清 | AI 引用二手頁面而非官方文件 | 正確頁面無法成為可信參考 |
這也是為什麼一個品牌可能 SEO 流量不錯,卻在 AI 搜尋中表現很弱。如果被檢索到的事實充滿噪音,僅有排名頁面並不夠。
為什麼這個細節容易被忽略
很多 GEO 專案從提示詞追蹤開始:「ChatGPT 有沒有提到我們?」「Perplexity 有沒有引用我們?」「我們是否出現在 AI Overviews?」這些問題重要,但也可能掩蓋第二個問題。
一次品牌提及可能是負面的、錯誤的、不完整的、過時的,或對商業轉化沒有幫助。
例如,某供應商可能出現在「適合財務團隊的最佳工作流程自動化工具」這類 AI 回答中,但回答同時聲稱該供應商只適合小團隊、缺少 API 支援,或安全文件不清楚。如果這些說法是錯的,能見度勝利就會變成轉化漏損。
更深層的問題是,AI 回答來自資訊源信心,而不是品牌偏好。模型和檢索系統會尋找重複出現、容易存取、語義清晰且有相互印證的資訊。如果錯誤事實比糾正後的事實更容易找到,錯誤事實就可能勝出。
Auspia 的觀點是:2026 年的 GEO 團隊應同時追蹤三層指標:
- 存在感:品牌是否出現在相關 AI 回答中。
- 準確性:回答是否反映當前品牌事實。
- 商業方向:回答是否幫助合格買家進入下一步。
多數團隊過度衡量存在感,卻低估了準確性。
品牌事實漂移循環
AI 資料污染通常遵循一個可重複的循環。
說明:舊頁面、薄弱的資訊源層級和未監測的 AI 回答疊加時,品牌事實漂移會持續放大。
用直白的話說,這個循環是:
- 品牌變化快於網頁更新。 產品、定價、包裝、整合、合規說明和客戶群都會變化。
- 舊來源仍可被抓取。 舊 PDF、比較頁、目錄資料、合作夥伴頁面、媒體提及和論壇回答繼續流通。
- AI 檢索發現混合證據。 系統同時看到當前說法和過期說法,卻未必能完美判斷新鮮度和權威性。
- 回答壓縮了細節。 相互矛盾的事實變成一句看似確定的話。
- 買家基於壓縮回答行動。 他們排除品牌、提出錯誤問題,或選擇競品。
- 被污染的回答產生更多下游內容。 人們把摘要複製進文件、貼文、銷售筆記和評論,進一步強化模式。
打斷這個循環,不能只靠發布一篇糾正文章。你需要一個可重複的修復系統。
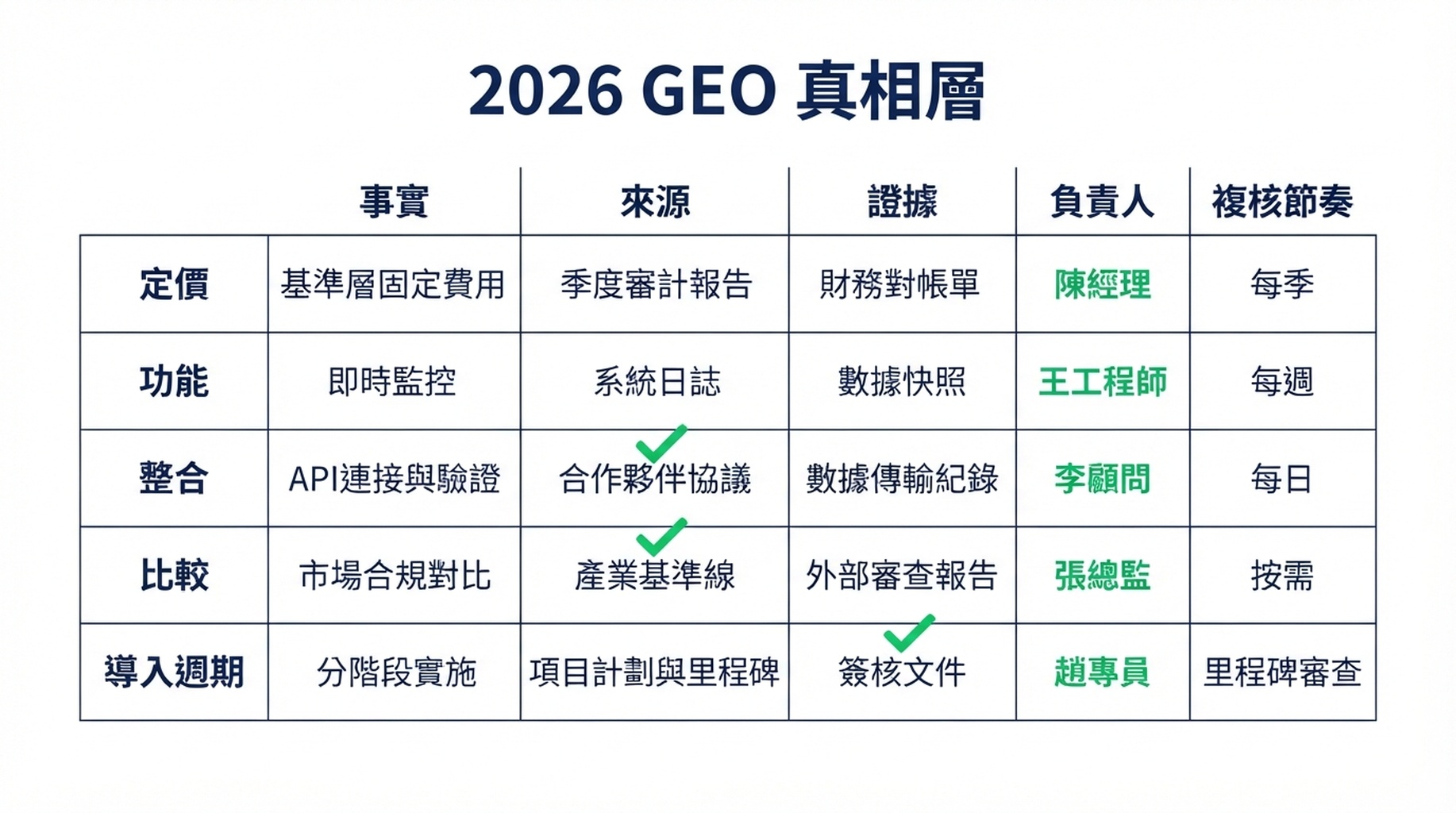
建立 2026 GEO 真相層
GEO 真相層是一個簡單的營運資產:一套當前、結構化、可被外部驗證的品牌事實,讓人和 AI 系統都能理解。
它不應該只存在於簡報裡。它應反映在網站、文件、Schema、比較頁面、合作夥伴資料、評論網站描述、PR 樣板文、說明中心語言和銷售素材中。
一個實用的真相層包括五部分:
| 真相層資產 | 控制什麼 | 示例欄位 |
|---|---|---|
| 品牌事實登記表 | 重要主張的標準版本 | 品類、目標使用者、用例、定價邊界、部署模式 |
| 官方證據頁面 | AI 系統可以檢索和引用的頁面 | 產品頁、文件、安全頁、整合頁、客戶故事 |
| 結構化資料和清晰實體 | 機器可讀上下文 | Organization schema、Product schema、FAQ schema、sameAs、作者/發布者清晰度 |
| 第三方佐證 | 自有網站之外的證據 | 合作夥伴列表、分析師提及、評論資料、社群回答 |
| 監測與糾錯佇列 | 發現和修復失真的流程 | 提示詞檢查、引用來源日誌、負責人、優先級、修復狀態 |
一張輕量試算表就足以開始。關鍵是所有權。每個關鍵事實都需要來源 URL、證據類型、負責人和複核節奏。
常能改善 AI 回答準確性的五個小修復
你不需要先重建整個網站。先從會改變買家決策的事實開始。
1. 為你的品類建立「當前事實」頁面
建立一個頁面,清楚說明產品是什麼、面向誰、能做什麼、不能做什麼,以及這些事實何時更新。使用直接語言,而不是宣傳冊式文案。
建議包含:
- 一句話說明產品做什麼
- 主要用例
- 最適合的客戶
- 部署和整合說明
- 定價或定價邊界解釋
- 安全與合規連結
- 常見誤解
- 最後複核日期
這個頁面可以成為內部團隊和外部糾錯的參考點。
2. 圍繞可驗證標準重寫比較頁
AI 系統經常使用比較頁回答供應商評估問題。如果你的比較內容含糊、防禦性強或過度宣傳,它作為來源的價值就會下降。
讓比較內容更容易被擷取:
- 先說明比較標準,再給結論。
- 區分事實和觀點。
- 在功能、整合、定價和合規上連結官方文件。
- 適當加入「不適合選擇我們」的情境。
- 不用無法驗證的說法攻擊競品。
清晰的比較頁能減少 AI 把競品框架當作中立市場觀點重複的可能。
3. 在高意圖頁面加入誤解澄清區塊
如果 AI 系統反覆犯同一個錯誤,就在相關頁面直接回應這個錯誤。
示例:
常見誤解:一些舊來源將 Product X 描述為只適合小團隊。截至 2026 年產品線,Product X 已支援企業 SSO、基於角色的存取控制、稽核日誌和私有部署選項。詳情請查看安全文件和企業部署指南。
這樣做有效,是因為它給檢索系統提供了清晰糾正、當前日期和支撐連結。
4. 發布更多內容前,先清理第三方資料
很多團隊一邊發布新的 GEO 內容,一邊忽略評論網站、市集目錄、合作夥伴目錄、GitHub 頁面、應用商店、文件鏡像和舊媒體資料中的過時資訊。
列出最可能被品牌和比較提示詞檢索到的 20 個頁面。先更新它們,再建立另一篇泛泛的思想領導文章。
優先處理已經排名、被引用,或出現在 AI 回答來源中的頁面。
5. 不只追蹤提及,還要追蹤準確性
提示詞追蹤器不應只記錄品牌是否出現。加入準確性標籤。
可以使用簡單評分:
| 分數 | 含義 | 行動 |
|---|---|---|
| 0 | 品牌缺席 | 新增或強化相關來源內容 |
| 1 | 品牌被提到但錯誤 | 找出錯誤主張和來源路徑 |
| 2 | 品牌被提到但不完整 | 增加缺失證據或更清晰的頁面段落 |
| 3 | 品牌準確但定位較弱 | 改進比較標準和用例清晰度 |
| 4 | 品牌準確且有商業價值 | 持續監控並保持來源一致性 |
這會把 GEO 從虛榮的能見度報告,變成營運工作流程。
修復失真品牌資訊的 14 天衝刺
如果你懷疑 AI 搜尋正在錯誤描述品牌,可以執行一個聚焦的兩週衝刺。
第 1-2 天:收集提示詞
從銷售通話、SEM 查詢、客服工單、比較搜尋和買家異議中收集 30-50 個提示詞。覆蓋品牌、品類、功能、定價、整合、導入和競品問題。
第 3-4 天:記錄 AI 回答
在買家使用的 AI 平台上測試這些提示詞。記錄回答、品牌位置、可用引用來源、錯誤主張和商業影響。
第 5-6 天:追蹤污染來源
對每條錯誤主張,識別可能的來源類型:官方頁面、舊 PDF、評論資料、比較文章、合作夥伴頁面、論壇回答、市集目錄或競品內容。
第 7-9 天:修復官方來源
先更新你能控制的頁面。加入更清晰的定義、更新日期、Schema、FAQ 區塊、誤解澄清段和證據連結。
第 10-11 天:修復外部資料
更新高權重第三方資料、合作夥伴描述、評論網站樣板文和市集目錄。無法直接編輯時,發布更好的公開參考,並請合作夥伴使用它。
第 12-13 天:發布佐證內容
建立一到兩個高品質證據資產:客戶故事、整合指南、安全說明、導入指南、基準頁面或比較文章。保持事實化、可引用。
第 14 天:複測並確定佇列優先級
再次執行同一組提示詞。有些回答不會立即變化,但你會看出問題是來源缺口、抓取/檢索延遲,還是第三方污染。
如果團隊想更快建立基準,可以使用 Auspia 的 AI Search Visibility Checker 這樣的能見度稽核工具,把提示詞、回答和品牌存在檢查變成可重複的評審流程。
清理後應該衡量什麼
不要期待所有 AI 回答一夜之間更新。不同系統有不同檢索方式、索引、引用、瀏覽行為和回答生成規則。衡量趨勢方向,而不是一次完美快照。
每週追蹤這些指標:
| 指標 | 說明什麼 |
|---|---|
| 品牌回答準確率 | AI 回答是否反映當前事實 |
| 錯誤主張頻率 | 哪些失真仍在重複 |
| 來源集中度 | AI 系統是否引用官方和高品質來源 |
| 高意圖提示詞覆蓋 | 買家階段問題是否包含你的品牌 |
| 商業有用性得分 | 回答是否幫助買家評估、比較或聯絡你 |
| 糾正延遲 | 修復來源影響 AI 回答需要多久 |
最強的 GEO 專案會形成回饋循環:AI 回答稽核、來源修復、證據內容、第三方糾正、複測,以及銷售團隊學習。
常見錯誤
錯誤 1:把 GEO 當成 PR 分發。 如果來源層級混亂,發布更多文章不會修復被污染的事實。
錯誤 2:只修正官網。 AI 回答常來自外部來源。評論網站、合作夥伴頁面和舊比較內容也需要清理。
錯誤 3:使用模糊品牌定位。 「一體化 AI 平台」不是事實。AI 系統需要具體用例、實體、整合、產業和限制。
錯誤 4:把重要事實藏在 PDF 或圖片裡。 如果資訊會影響 AI 回答,就應該以 HTML 形式可抓取、可擷取。
錯誤 5:只衡量聲量份額。 可見但不準確的品牌回答,對買家旅程的傷害可能超過缺席。
FAQ
GEO 中的 AI 資料污染是什麼?
GEO 中的 AI 資料污染,是指過時、錯誤、有偏、重複或不一致的公開資訊可能被 AI 搜尋系統檢索,並合成為品牌回答。當這些回答影響品牌能見度、買家信任或轉化時,它就成為 GEO 問題。
為什麼 AI 工具會給出錯誤的品牌資訊?
當公開來源彼此矛盾、官方頁面不清晰、舊頁面仍可存取、第三方資料過期,或比較內容比當前文件更容易被檢索時,AI 工具就可能給出錯誤品牌資訊。即使底層證據混雜,回答也可能顯得很確定。
如何修復 AI 搜尋中的失真品牌事實?
從稽核高意圖提示詞開始,記錄錯誤主張,追蹤可能的來源類型,更新官方頁面,清理第三方資料,新增結構化資料,發布佐證內容,並按固定節奏複測同一組提示詞。
GEO 團隊應該先關注引用還是準確性?
對品牌關鍵提示詞而言,準確性應優先。被引用的資訊如果錯誤或過時,更多引用並沒有價值。當品牌真相層穩定後,引用成長才更安全,也更有商業價值。
2026 年品牌應多久監測一次 AI 回答準確性?
對高成長 B2B、SaaS、醫療健康、金融、電商和技術類目,高意圖提示詞每週監測是實用基準。低風險常青類目可以每月監測,但任何重大產品、定價或定位變化都應觸發一次新稽核。
最後結論
2026 年被忽略的 GEO 細節,不是 AI 系統能否提到你的品牌,而是它們能否重複正確版本的品牌。
如果公開資訊層被污染,AI 搜尋會在買家評估供應商的關鍵時刻放大錯誤故事。解決方法是營運化:建立真相層,清理最高風險來源,結構化重要事實,用可信管道進行佐證,並持續監測回答準確性。
這就是 GEO 如何從「能見度工作」升級為品牌資訊治理。
Author: Lydia Hart,Auspia 品牌實體策略師,參與 200+ 次實體稽核。Lydia 關注品牌事實、實體一致性、About 頁面、品類語言和知識圖譜準備度。