O problema de 2026: respostas de IA podem transformar dados antigos da marca em novo risco de compra
Em 2026, um dos detalhes de GEO mais fáceis de ignorar não é a cobertura de palavras-chave. É a precisão dos fatos da marca.
Quando sistemas de busca com IA respondem a perguntas de compradores, normalmente sintetizam informações de muitas páginas: site oficial, páginas antigas de parceiros, diretórios desatualizados, comparativos, bases de produtos raspadas, fóruns, mídia, sites de avaliação e conteúdo de concorrentes. Mesmo quando essas fontes discordam, a resposta pode soar confiante. O comprador pode ver um prazo de implementação errado, uma faixa de preço antiga, uma integração ausente ou uma comparação enviesada antes de chegar ao seu site.
Isso é poluição de dados de IA no contexto de GEO: fontes públicas poluídas ou inconsistentes são recuperadas, misturadas e repetidas como se fossem conhecimento atual. Para marcas B2B e SaaS, isso não é só reputação. Afeta intenção de demo, objeções de vendas, confiança de compras e a lista curta de fornecedores.
A solução prática é criar uma camada de verdade GEO 2026: fatos atuais da marca, páginas estruturadas, provas de terceiros, fluxos de correção e monitoramento recorrente de respostas de IA. GEO não é apenas ser mencionado. A menção precisa ser precisa o bastante para mover o comprador adiante.
Legenda: Um programa GEO em 2026 deve tratar respostas imprecisas de IA como um problema reparável de qualidade de fonte, não apenas como visibilidade.
Como a poluição de dados de IA aparece em GEO
A poluição começa pequena. A marca muda embalagem, preço, posicionamento ou capacidades. O site oficial é atualizado, mas páginas antigas continuam online. Afiliados usam textos antigos. Um site de avaliação resume o produto errado. Uma página comparativa concorrente enquadra a marca por uma fraqueza superada. Um artigo de ajuda mantém termos legados. A IA recupera partes desse registro misto.
O resultado é deriva de fatos da marca: a camada pública de informação se afasta da realidade atual.
| Sinal poluído | Como aparece na IA | Por que prejudica crescimento |
|---|---|---|
| Preços antigos | Planos, regras de teste ou faixas enterprise erradas | Compradores se excluem antes de falar com vendas |
| Escopo funcional errado | Função existente aparece como ausente ou o contrário | Vendas recebe objeções evitáveis |
| Linguagem de categoria fraca | Posicionamento genérico ou antigo | Menos diferenciação em prompts comparativos |
| Enquadramento competitivo enviesado | Repetição de claims antigos de terceiros | Tráfego de avaliação vai para concorrentes |
| Dados de implementação inconsistentes | Prazo, integração ou compliance incorretos | Compras e técnicos perdem confiança |
| Hierarquia de fontes confusa | Fontes secundárias citadas em vez da documentação oficial | Páginas corretas não viram referência |
Por isso uma marca pode ter bom SEO e ainda assim falhar em busca com IA. Páginas ranqueadas não bastam se os fatos recuperados são ruidosos.
Por que esse detalhe passa despercebido
Muitos programas GEO começam acompanhando prompts: o ChatGPT nos menciona? O Perplexity nos cita? Aparecemos em AI Overviews? Isso importa, mas pode esconder outra pergunta.
Uma menção pode ser negativa, errada, parcial, antiga ou inútil comercialmente.
Um fornecedor pode aparecer em “melhores ferramentas de automação de workflow para finanças”, enquanto a resposta também diz que ele serve só para equipes pequenas, não tem API ou tem documentação de segurança pouco clara. Se isso for falso, visibilidade vira vazamento de conversão.
Respostas de IA são construídas por confiança nas fontes, não por preferência de marca. Modelos procuram informações repetidas, acessíveis, claras e corroboradas. Se o fato errado é mais fácil de encontrar do que o corrigido, ele pode vencer.
A visão da Auspia: em 2026, equipes GEO devem medir três camadas:
- Presença: a marca aparece nas respostas relevantes?
- Precisão: a resposta reflete fatos atuais?
- Direção comercial: a resposta ajuda um comprador qualificado a avançar?
Muitas equipes medem presença demais e precisão de menos.
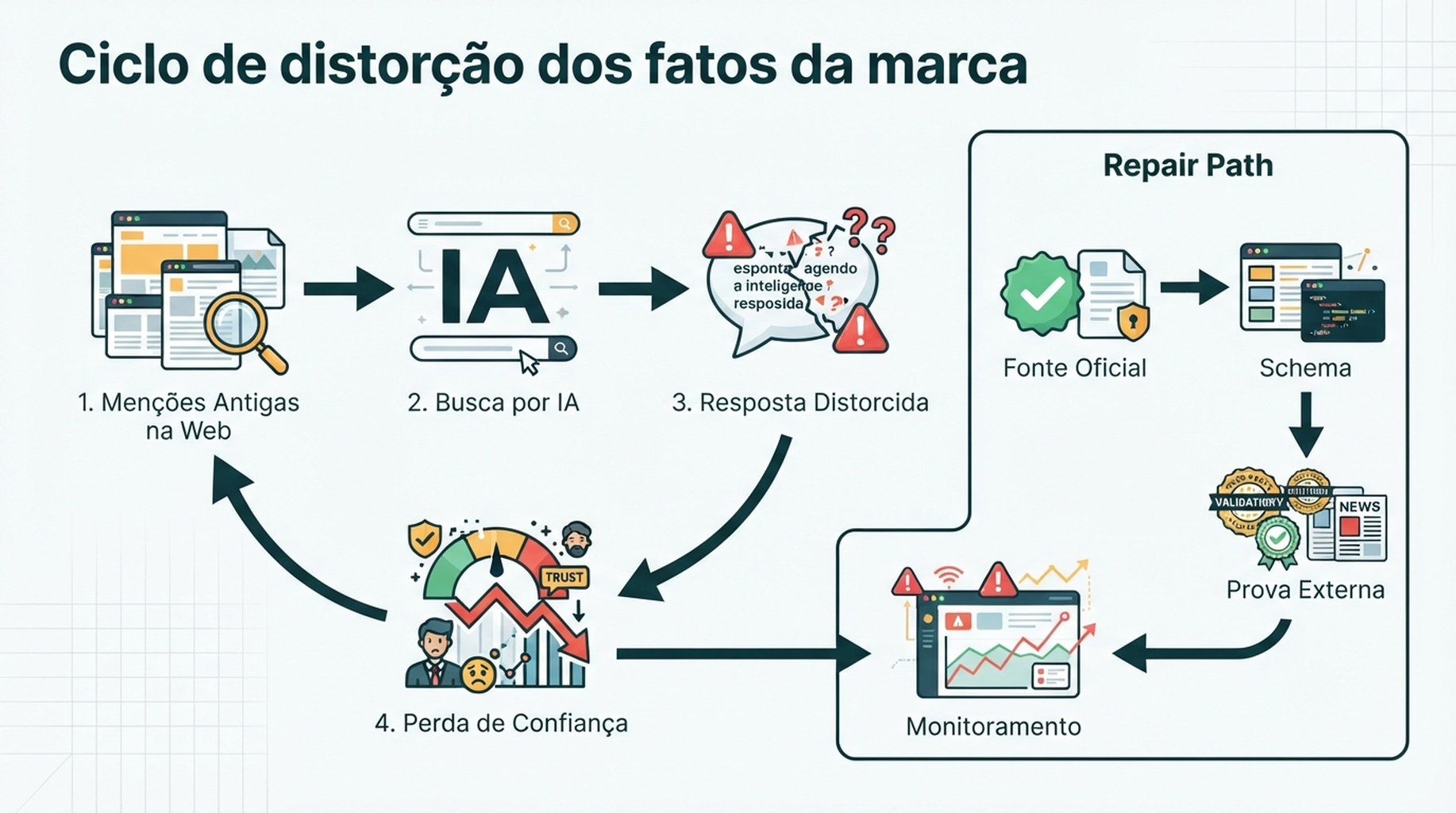
O ciclo de deriva dos fatos da marca
A poluição de dados de IA costuma seguir um ciclo repetível.
Legenda: Páginas antigas, hierarquia fraca de fontes e respostas não monitoradas amplificam a deriva.
- A marca muda mais rápido que a web. Produto, preço, integrações, compliance e segmentos evoluem.
- Fontes antigas continuam rastreáveis. PDFs, comparativos, perfis, parceiros, mídia e fóruns seguem circulando.
- A IA encontra evidência misturada. Vê fatos novos e antigos sem julgar sempre recência e autoridade.
- A resposta comprime nuance. Contradições viram uma frase confiante.
- O comprador age sobre a síntese. Exclui a marca, pergunta errado ou escolhe concorrente.
- A resposta poluída cria conteúdo derivado. Resumos vão para documentos, posts, notas de vendas e avaliações.
Quebrar o ciclo exige um sistema, não apenas um artigo de correção.
Construa uma camada de verdade GEO 2026
Uma camada de verdade GEO é um ativo operacional: uma fonte atual, estruturada e verificável de fatos da marca que humanos e IA conseguem entender.
Ela deve aparecer no site, documentação, Schema, comparativos, perfis de parceiros, avaliações, boilerplates de PR, help center e materiais de vendas.
| Ativo | O que controla | Exemplos |
|---|---|---|
| Registro de fatos da marca | Versão canônica de claims importantes | Categoria, usuários, casos de uso, limites de preço, implantação |
| Páginas oficiais de prova | Páginas recuperáveis e citáveis | Produto, docs, segurança, integrações, clientes |
| Dados estruturados e entidades | Contexto legível por máquina | Organization schema, Product schema, FAQ schema, sameAs, autor/editor |
| Corroboração externa | Evidência fora do site | Parceiros, analistas, avaliações, comunidade |
| Monitoramento e fila de correção | Workflow contra distorção | Prompts, fontes citadas, dono, prioridade, status |
Uma planilha leve é suficiente para começar. Cada fato crítico precisa de URL, tipo de prova, responsável e cadência de revisão.
Cinco ajustes pequenos que melhoram a precisão
1. Crie uma página de “fatos atuais” da categoria
Explique o que o produto é, para quem serve, o que faz, o que não faz e quando os fatos foram revisados. Inclua definição em uma frase, casos de uso, cliente ideal, implantação, integrações, preço, segurança, equívocos comuns e data de revisão.
2. Reescreva comparativos com critérios verificáveis
Declare critérios antes da conclusão. Separe fatos de opinião. Linke docs oficiais para funções, integrações, preços e compliance. Inclua quando não escolher vocês. Evite claims contra concorrentes sem prova.
3. Adicione blocos de equívoco em páginas de alta intenção
Se a IA repete o mesmo erro, responda diretamente.
Equívoco comum: algumas fontes antigas descrevem Product X como adequado apenas para equipes pequenas. Na linha 2026, Product X oferece SSO enterprise, controle por papéis, logs de auditoria e implantação privada. Veja a documentação de segurança e o guia enterprise.
4. Limpe perfis de terceiros antes de publicar mais
Atualize sites de avaliação, marketplaces, diretórios de parceiros, GitHub, app stores, espelhos de docs e media kits. Liste as 20 páginas mais prováveis em prompts de marca/comparação e priorize as que já ranqueiam ou são citadas.
5. Meça precisão, não só menções
| Nota | Significado | Ação |
|---|---|---|
| 0 | Marca ausente | Adicionar ou fortalecer fontes |
| 1 | Marca citada mas errada | Identificar claim e caminho da fonte |
| 2 | Marca citada mas incompleta | Adicionar prova ou seções claras |
| 3 | Marca correta mas fraca | Melhorar critérios e casos de uso |
| 4 | Marca correta e útil | Monitorar e preservar consistência |
Assim GEO vira fluxo operacional, não relatório de vaidade.
Sprint de 14 dias para corrigir informação distorcida
Dias 1-2: colete prompts. Reúna 30-50 prompts de vendas, SEM, suporte, comparações e objeções.
Dias 3-4: capture respostas. Teste nas superfícies de IA usadas pelos compradores. Registre resposta, posição, citações, erros e impacto.
Dias 5-6: rastreie fontes poluídas. Classifique cada erro: página oficial, PDF antigo, avaliação, comparativo, parceiro, fórum, marketplace ou concorrente.
Dias 7-9: repare fontes oficiais. Atualize páginas com definições, datas, Schema, FAQ, blocos de equívoco e links de prova.
Dias 10-11: repare perfis externos. Corrija perfis de autoridade, textos de parceiros, avaliações e marketplaces. Se não puder editar, publique uma referência melhor.
Dias 12-13: publique provas. Crie caso de cliente, guia de integração, explicação de segurança, guia de implantação, benchmark ou comparativo factual.
Dia 14: reteste e priorize. Rode os prompts novamente para separar lacunas de fonte, atraso de rastreamento e poluição externa.
Para uma linha de base rápida, o AI Search Visibility Checker da Auspia ajuda a transformar prompts, respostas e presença de marca em revisão repetível.
O que medir depois da limpeza
Não espere atualização imediata. Sistemas variam em recuperação, índice, citações, navegação e geração. Meça tendência.
| Métrica | O que mostra |
|---|---|
| Precisão das respostas | Se a IA reflete fatos atuais |
| Frequência de claims errados | Quais distorções persistem |
| Concentração de fontes | Se fontes oficiais e boas são citadas |
| Cobertura de prompts de compra | Se a marca aparece em perguntas decisivas |
| Utilidade comercial | Se a resposta ajuda a avaliar, comparar ou contatar |
| Latência de correção | Tempo para a fonte reparada influenciar a IA |
Programas GEO fortes criam um loop: auditoria, reparo de fontes, provas, correção externa, reteste e aprendizado para vendas.
Erros comuns
Erro 1: tratar GEO como distribuição de PR. Mais artigos não corrigem fatos poluídos com hierarquia de fontes bagunçada.
Erro 2: corrigir só o site oficial. Respostas de IA vêm muito de fontes externas.
Erro 3: usar posicionamento vago. “Plataforma de IA tudo em um” não é fato.
Erro 4: esconder fatos em PDFs ou imagens. Informação importante deve estar em HTML rastreável e extraível.
Erro 5: medir só share of voice. Uma resposta visível e errada pode prejudicar mais que ausência.
FAQ
O que é poluição de dados de IA em GEO?
É a presença de informação pública antiga, errada, enviesada, duplicada ou inconsistente que sistemas de busca com IA podem recuperar e sintetizar em respostas de marca.
Por que ferramentas de IA erram informações de marca?
Porque fontes públicas discordam, páginas oficiais são pouco claras, páginas antigas continuam acessíveis, perfis de terceiros estão desatualizados ou comparativos são mais fáceis de recuperar que a documentação atual.
Como corrigir fatos de marca distorcidos?
Audite prompts de alta intenção, registre claims errados, rastreie fontes, atualize páginas oficiais, limpe perfis externos, adicione dados estruturados, publique provas e reteste regularmente.
Citações ou precisão primeiro?
Para prompts críticos, precisão primeiro. Mais citações não ajudam se a informação citada está errada ou antiga.
Com que frequência monitorar em 2026?
Para B2B, SaaS, saúde, finanças, ecommerce e tecnologia de alto crescimento, semanalmente para prompts de alta intenção. Mudanças grandes de produto, preço ou posicionamento exigem nova auditoria.
Conclusão
O detalhe GEO esquecido em 2026 não é se a IA pode mencionar sua marca. É se ela consegue repetir a versão correta da sua marca.
Se a camada pública está contaminada, a busca com IA amplifica a história errada no momento da avaliação. A solução é operacional: camada de verdade, limpeza de fontes de risco, fatos estruturados, corroboração confiável e monitoramento contínuo.
Assim GEO evolui de visibilidade para governança de informação da marca.
Author: Lydia Hart, estrategista de entidades de marca na Auspia, com mais de 200 auditorias de entidade analisadas. Lydia escreve sobre fatos de marca, consistência de entidades, páginas About, linguagem de categoria e preparação para knowledge graphs.