הבעיה ב-2026: תשובות AI יכולות להפוך נתוני מותג ישנים לסיכון רכישה חדש
ב-2026, אחד הפרטים שהכי קל לפספס ב-GEO אינו כיסוי מילות מפתח. זהו דיוק עובדות המותג.
כאשר מערכות חיפוש מבוססות AI עונות לשאלות קונים, הן לרוב מסנתזות מידע ממקורות רבים: האתר שלכם, עמודי שותפים ישנים, ספריות לא מעודכנות, מאמרי השוואה, בסיסי נתוני מוצר, פורומים, מדיה, אתרי ביקורות ותוכן מתחרים. גם אם המקורות סותרים זה את זה, התשובה עדיין יכולה להישמע בטוחה. הקונה עשוי לראות זמן הטמעה שגוי, טווח מחיר ישן, אינטגרציה חסרה או השוואה מוטה עוד לפני שהוא מגיע לאתר שלכם.
זו זיהום נתוני AI בהקשר GEO: מקורות ציבוריים מזוהמים או לא עקביים נשלפים, מעורבבים וחוזרים כאילו היו ידע עדכני. עבור מותגי B2B ו-SaaS, זו לא רק בעיית מוניטין. היא משפיעה על כוונת demo, התנגדויות מכירה, אמון רכש והאם המותג נכנס ל-shortlist.
הפתרון המעשי הוא לבנות שכבת אמת GEO 2026: עובדות מותג עדכניות, עמודים מובנים, הוכחות צד שלישי, תהליכי תיקון וניטור חוזר של תשובות AI. GEO כבר אינו רק להופיע. האזכור צריך להיות מדויק מספיק כדי לעזור לקונה להתקדם.
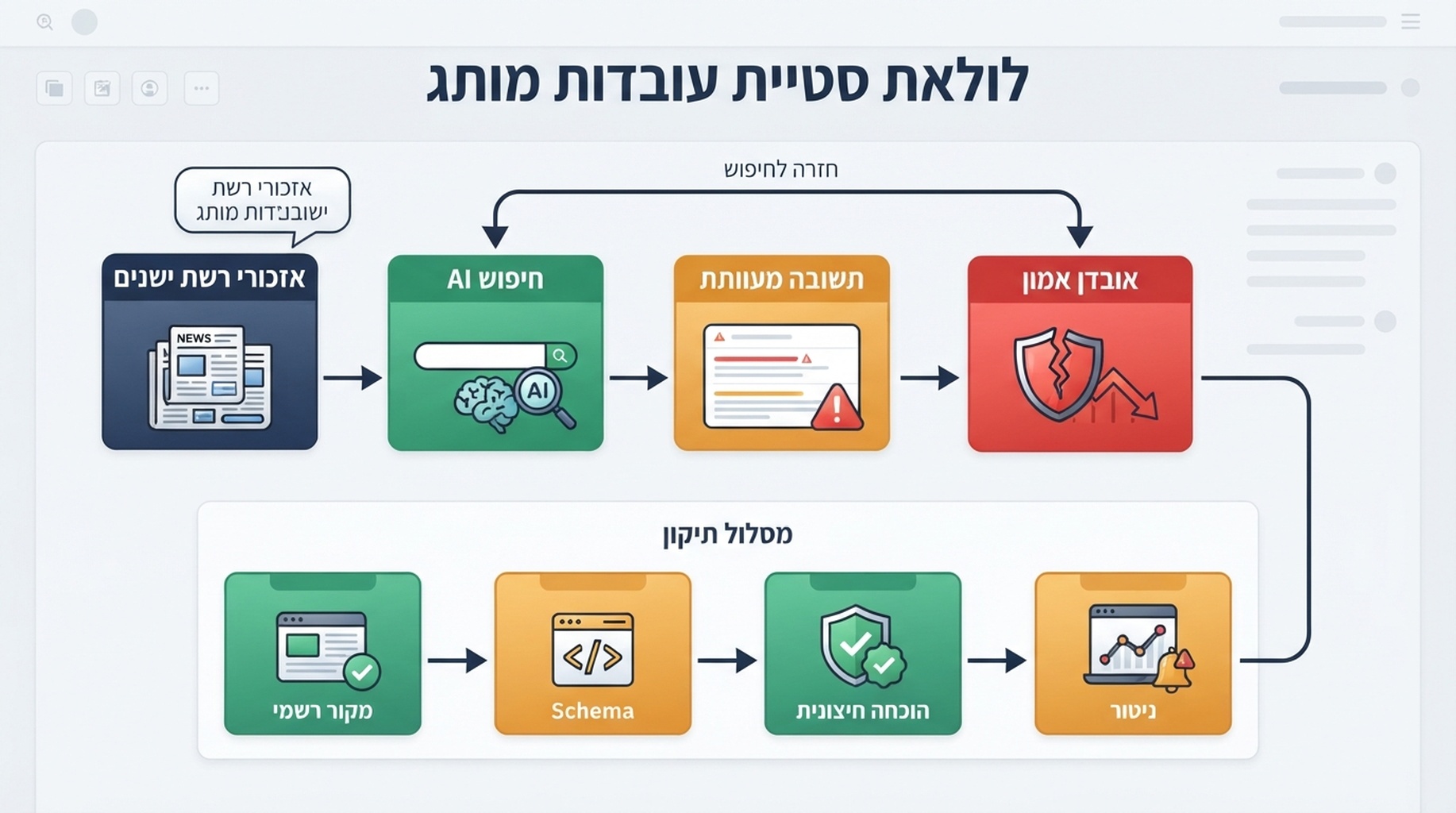
כיתוב: תוכנית GEO ב-2026 צריכה להתייחס לתשובות AI לא מדויקות כבעיית איכות מקורות הניתנת לתיקון, לא רק כבעיית נראות.
איך נראה זיהום נתוני AI ב-GEO
הזיהום לרוב מתחיל בסטייה קטנה. המותג משנה חבילה, תמחור, מיצוב או יכולות מוצר. האתר הרשמי מתעדכן, אבל עמודים ישנים נשארים במקומות אחרים. שותפים ממשיכים להשתמש בטקסט ישן. אתר ביקורות מסכם את המוצר לא נכון. עמוד השוואה של מתחרה ממסגר את המותג סביב חולשה שכבר אינה רלוונטית. מאמר עזרה שומר מונחים ישנים. ואז מערכות AI שולפות חלקים מהרשומה המעורבת הזאת.
התוצאה היא סטיית עובדות מותג: שכבת המידע הציבורית מתרחקת בהדרגה מהמציאות העסקית הנוכחית.
| אות מזוהם | איך הוא מופיע בתשובות AI | למה זה פוגע בצמיחה |
|---|---|---|
| תמחור ישן | AI מצטט תוכניות ישנות, כללי trial שגויים או טווחי enterprise לא מדויקים | קונים פוסלים את עצמם לפני שיחה עם sales |
| היקף פונקציונלי שגוי | AI אומר שפיצ'ר קיים חסר או מבטיח פיצ'ר שאינו קיים | sales יורש התנגדויות שניתן היה למנוע |
| שפת קטגוריה חלשה | המותג מתואר באופן גנרי או מיושן | בידול נאבד בשאלות השוואה |
| מסגור מתחרים מוטה | AI חוזר על claims ישנים מצדדים שלישיים | תנועת הערכה עוברת למתחרים |
| נתוני הטמעה לא עקביים | זמן setup, אינטגרציה או compliance שגויים | צוותי רכש וטכנולוגיה מאבדים אמון |
| היררכיית מקורות לא ברורה | AI מצטט מקורות משניים במקום תיעוד רשמי | העמודים הנכונים לא הופכים לרפרנס |
לכן מותג יכול ליהנות מתנועת SEO ועדיין להיכשל בחיפוש AI. עמודים מדורגים אינם מספיקים אם העובדות הנשלפות רועשות.
למה הפרט הזה מתפספס
תוכניות GEO רבות מתחילות במעקב prompts: האם ChatGPT מזכיר אותנו, האם Perplexity מצטט אותנו, האם אנו מופיעים ב-AI Overviews. השאלות חשובות, אבל מסתירות בעיה שנייה.
אזכור מותג יכול להיות שלילי, שגוי, חלקי, מיושן או חסר ערך מסחרי.
לדוגמה, ספק יכול להופיע בתשובה על “כלי workflow automation הטובים ביותר לצוותי finance”, אך אותה תשובה עשויה לטעון שהוא מתאים רק לצוותים קטנים, שאין לו API או שתיעוד security שלו לא ברור. אם זה שגוי, הנראות הופכת לדליפת conversion.
תשובות AI נבנות מאמון במקורות, לא מהעדפת מותג. מודלים ומערכות retrieval מחפשים מידע חוזר, נגיש, ברור ומאומת. אם העובדות השגויות קלות יותר למציאה מהעובדות המתוקנות, הן עלולות לנצח.
העמדה של Auspia: ב-2026 צוותי GEO צריכים למדוד שלוש שכבות יחד:
- נוכחות: האם המותג מופיע בתשובות רלוונטיות.
- דיוק: האם התשובה משקפת עובדות עדכניות.
- כיוון מסחרי: האם התשובה עוזרת לקונה מתאים להתקדם.
רוב הצוותים מודדים יותר מדי נוכחות ופחות מדי דיוק.
לולאת סטיית עובדות מותג
זיהום נתוני AI לרוב עוקב אחר לולאה חוזרת.
כיתוב: עמודים ישנים, היררכיית מקורות חלשה ותשובות AI לא מנוטרות מגבירים סטיית עובדות מותג.
- המותג משתנה מהר יותר מהווב. מוצר, מחיר, אינטגרציות, compliance וסגמנטים מתפתחים.
- מקורות ישנים נשארים crawlable. PDFs, השוואות, profiles, עמודי שותפים, מדיה ופורומים ממשיכים להסתובב.
- AI מוצא ראיות מעורבות. הוא רואה claims חדשים וישנים בלי להבין תמיד עדכניות וסמכות.
- התשובה דוחסת ניואנס. עובדות סותרות הופכות למשפט בטוח.
- הקונה פועל על בסיס הסיכום. הוא פוסל את המותג, שואל שאלה שגויה או בוחר מתחרה.
- התשובה המזוהמת יוצרת תוכן המשך. סיכומים מועתקים למסמכים, פוסטים, sales notes וביקורות.
כדי לשבור את הלולאה צריך מערכת תיקון חוזרת, לא מאמר תיקון אחד.
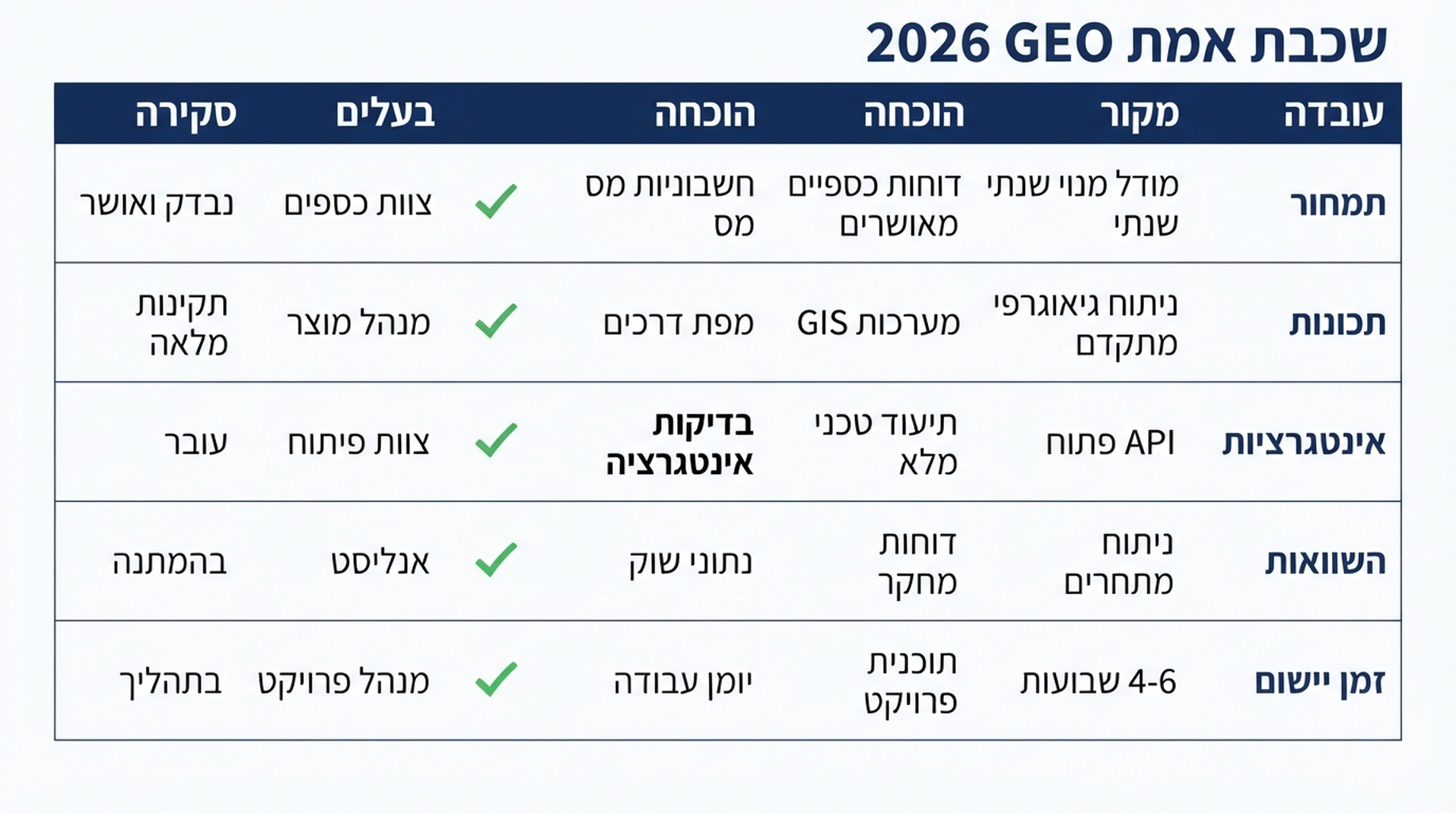
בונים שכבת אמת GEO 2026
שכבת אמת GEO היא נכס תפעולי: מקור עדכני, מובנה ובר אימות של עובדות מותג, שאנשים ומערכות AI יכולים להבין.
היא צריכה להופיע באתר, בתיעוד, ב-Schema, בעמודי השוואה, בפרופילי שותפים, באתרי ביקורות, ב-PR boilerplate, ב-help center ובחומרי sales.
| נכס | מה הוא שולט בו | דוגמאות |
|---|---|---|
| רישום עובדות מותג | הגרסה הקנונית של claims חשובים | קטגוריה, משתמשים, use cases, גבולות מחיר, deployment |
| עמודי הוכחה רשמיים | עמודים ש-AI יכול לשלוף ולצטט | מוצר, docs, security, integrations, סיפורי לקוחות |
| נתונים מובנים וישויות | הקשר קריא למכונה | Organization schema, Product schema, FAQ schema, sameAs, author/publisher |
| אימות חיצוני | הוכחות מחוץ לאתר | partners, analysts, reviews, community |
| ניטור ותור תיקונים | workflow נגד עיוות | prompts, cited sources, owner, priority, status |
אפשר להתחיל בגיליון קל. כל עובדה קריטית צריכה URL מקור, סוג הוכחה, בעלים וקצב סקירה.
חמישה תיקונים קטנים שמשפרים דיוק AI
1. צרו עמוד “עובדות עדכניות” לקטגוריה
הסבירו מה המוצר, למי הוא מיועד, מה הוא עושה, מה אינו עושה ומתי העובדות נבדקו. כללו הגדרה במשפט אחד, use cases, לקוח מתאים, deployment, integrations, מחיר, security, אי הבנות נפוצות ותאריך סקירה.
2. כתבו מחדש עמודי השוואה עם קריטריונים ניתנים לאימות
הציגו קריטריונים לפני המסקנה. הפרידו עובדות מדעה. קשרו docs רשמיים לפיצ'רים, אינטגרציות, מחיר ו-compliance. הסבירו מתי לא לבחור בכם. הימנעו מ-claims לא מוכחים נגד מתחרים.
3. הוסיפו בלוקי אי-הבנה בעמודים בעלי כוונה גבוהה
אם AI חוזר על אותה טעות, תקנו אותה ישירות.
אי הבנה נפוצה: מקורות ישנים מתארים את Product X כמתאים רק לצוותים קטנים. בקו 2026, Product X תומך ב-enterprise SSO, RBAC, audit logs ו-private deployment. ראו תיעוד security ומדריך enterprise.
4. נקו פרופילים חיצוניים לפני פרסום עוד תוכן
עדכנו אתרי ביקורות, marketplaces, ספריות partner, GitHub, app stores, mirrors של docs ו-media kits ישנים. רשמו את 20 העמודים שסביר שיישלפו ב-prompts של מותג והשוואה, ותעדפו כאלה שכבר מדורגים או מצוטטים.
5. מדדו דיוק, לא רק אזכורים
| ציון | משמעות | פעולה |
|---|---|---|
| 0 | המותג חסר | הוסיפו או חזקו מקורות |
| 1 | מוזכר אבל שגוי | זהו claim שגוי ונתיב מקור |
| 2 | מוזכר אבל לא שלם | הוסיפו הוכחה או סעיפים ברורים |
| 3 | נכון אבל ממוצב חלש | שפרו קריטריונים ו-use cases |
| 4 | נכון ומועיל מסחרית | נטרו ושמרו עקביות |
כך GEO הופך ל-workflow תפעולי, לא לדוח vanity.
ספרינט 14 יום לתיקון מידע מעוות
ימים 1-2: איסוף prompts. אספו 30-50 prompts מ-sales calls, SEM, support, חיפושי השוואה והתנגדויות.
ימים 3-4: לכידת תשובות AI. בדקו בפלטפורמות שהקונים משתמשים בהן. תעדו תשובה, מיקום מותג, citations, טעויות והשפעה מסחרית.
ימים 5-6: איתור מקורות מזוהמים. סווגו כל טעות: עמוד רשמי, PDF ישן, review, comparison, partner, forum, marketplace או competitor.
ימים 7-9: תיקון מקורות רשמיים. הוסיפו definitions, תאריכים, Schema, FAQ, בלוקי אי-הבנה וקישורי הוכחה.
ימים 10-11: תיקון פרופילים חיצוניים. עדכנו מקורות צד שלישי חזקים, טקסטי partner, reviews ו-marketplaces. אם אי אפשר לערוך, פרסמו רפרנס טוב יותר.
ימים 12-13: פרסום הוכחות. צרו case study, integration guide, security explainer, implementation guide, benchmark או comparison עובדתי.
יום 14: בדיקה חוזרת ותעדוף. הריצו את אותם prompts כדי להבחין בין פערי מקור, עיכובי crawl וזיהום חיצוני.
לקו בסיס מהיר, AI Search Visibility Checker של Auspia יכול להפוך prompts, תשובות ונוכחות מותג לתהליך סקירה חוזר.
מה למדוד אחרי הניקוי
אל תצפו לעדכון מיידי. מערכות שונות ב-retrieval, index, citations, browsing ו-generation. מדדו מגמה.
| מדד | מה הוא מראה |
|---|---|
| דיוק תשובות מותג | האם AI משקף עובדות עדכניות |
| תדירות claims שגויים | אילו עיוותים חוזרים |
| ריכוז מקורות | האם מצוטטים מקורות רשמיים ואיכותיים |
| כיסוי prompts בעלי כוונה גבוהה | האם המותג מופיע בשאלות קנייה |
| שימושיות מסחרית | האם התשובה עוזרת להעריך, להשוות או ליצור קשר |
| זמן השפעת תיקון | כמה זמן לוקח למקור מתוקן להשפיע על AI |
תוכניות GEO חזקות יוצרות לולאה: audit תשובות, תיקון מקורות, הוכחות, תיקון חיצוני, retest ולמידה לצוות sales.
טעויות נפוצות
טעות 1: להתייחס ל-GEO כהפצת PR. עוד מאמרים לא מתקנים עובדות מזוהמות אם היררכיית המקורות מבולגנת.
טעות 2: לתקן רק את האתר הרשמי. תשובות AI מגיעות לעיתים קרובות ממקורות חיצוניים.
טעות 3: להשתמש במיצוב עמום. “פלטפורמת AI all-in-one” אינה עובדה.
טעות 4: להסתיר עובדות ב-PDF או תמונות. מידע חשוב צריך להיות ב-HTML שניתן לסרוק ולחלץ.
טעות 5: למדוד רק share of voice. תשובה גלויה אך שגויה עלולה להזיק יותר מהיעדרות.
FAQ
מהו זיהום נתוני AI ב-GEO?
זהו קיום מידע ציבורי ישן, שגוי, מוטה, כפול או לא עקבי שמערכות AI search יכולות לשלוף ולסנתז לתשובות על המותג.
למה כלי AI טועים במידע על מותג?
כי מקורות ציבוריים סותרים, עמודים רשמיים לא ברורים, עמודים ישנים נשארים נגישים, פרופילים חיצוניים מיושנים או שתוכן השוואתי קל יותר לשליפה מתיעוד עדכני.
איך מתקנים עובדות מותג מעוותות?
מבצעים audit ל-prompts בעלי כוונה גבוהה, מתעדים claims שגויים, מאתרים משפחות מקור, מעדכנים עמודים רשמיים, מנקים פרופילים חיצוניים, מוסיפים structured data, מפרסמים הוכחות ובודקים שוב בקביעות.
ציטוטים או דיוק קודם?
ב-prompts קריטיים למותג, דיוק קודם. עוד citations לא עוזרים אם המידע המצוטט שגוי או ישן.
באיזו תדירות לנטר ב-2026?
ב-B2B, SaaS, בריאות, פיננסים, ecommerce וטכנולוגיה בצמיחה מהירה, ניטור שבועי של prompts בעלי כוונה גבוהה הוא בסיס מעשי. שינוי גדול במוצר, מחיר או מיצוב צריך להפעיל audit חדש.
סיכום
פרט ה-GEO הנשכח ב-2026 אינו האם AI יכול להזכיר את המותג. השאלה היא האם הוא יכול לחזור על הגרסה הנכונה של המותג.
אם שכבת המידע הציבורית מזוהמת, AI search מגביר את הסיפור הלא נכון בדיוק ברגע שבו קונה מעריך ספקים. הפתרון תפעולי: שכבת אמת, ניקוי מקורות מסוכנים, מבנה לעובדות, אימות בערוצים אמינים וניטור דיוק רציף.
כך GEO עובר מעבודת visibility לממשל מידע מותג.
Author: Lydia Hart, אסטרטגית ישויות מותג ב-Auspia שעבדה על יותר מ-200 entity audits. Lydia כותבת על עובדות מותג, עקביות ישויות, עמודי About, שפת קטגוריה ומוכנות ל-knowledge graph.