El problema de 2026: las respuestas de IA pueden convertir datos antiguos de marca en nuevo riesgo comercial
En 2026, uno de los detalles de GEO más fáciles de pasar por alto no es la cobertura de palabras clave. Es la precisión de los hechos de marca.
Cuando los sistemas de búsqueda con IA responden preguntas de compradores, suelen sintetizar información de muchas páginas: tu sitio, páginas antiguas de partners, directorios desactualizados, artículos comparativos, bases de datos de productos extraídas, foros, medios, sitios de reseñas y contenido de competidores. Si esas fuentes no coinciden, la respuesta puede seguir sonando segura. El comprador puede ver un plazo de implementación equivocado, un rango de precios antiguo, una integración omitida o una comparación sesgada antes de llegar a tu web.
Eso es contaminación de datos de IA en GEO: material público contaminado o inconsistente se recupera, se mezcla y se repite como si fuera conocimiento actual. Para marcas B2B y SaaS, no es solo reputación. Afecta intención de demo, objeciones de ventas, confianza de compras y qué proveedor entra en la lista corta.
La solución práctica es crear una capa de verdad GEO 2026: hechos de marca actualizados, páginas estructuradas, pruebas de terceros, flujos de corrección y monitoreo recurrente de respuestas de IA. GEO ya no consiste solo en aparecer. Consiste en que la mención sea lo bastante precisa para ayudar al comprador a avanzar.
Leyenda: Un programa GEO 2026 debe tratar las respuestas inexactas de IA como un problema reparable de calidad de fuentes, no solo como un problema de visibilidad.
Cómo se ve la contaminación de datos de IA en GEO
La contaminación suele empezar en pequeño. La marca cambia empaquetado, precios, posicionamiento o capacidades. El sitio oficial se actualiza, pero las páginas antiguas siguen vivas en otros lugares. Algunos afiliados mantienen el texto viejo. Un sitio de reseñas resume mal el producto. Una página comparativa de un competidor encuadra la marca con una debilidad ya superada. Un artículo de ayuda conserva terminología legacy. Luego los sistemas de IA recuperan partes de ese registro mezclado.
El resultado es deriva de hechos de marca: la capa pública de información se separa lentamente de la realidad actual del negocio.
Síntomas comunes:
| Señal contaminada | Cómo aparece en respuestas de IA | Por qué daña el crecimiento |
|---|---|---|
| Precios desactualizados | La IA cita planes antiguos, reglas de prueba erróneas o rangos enterprise inexactos | Los compradores se descartan antes de hablar con ventas |
| Alcance funcional incorrecto | La IA dice que falta una función existente o promete una que no existe | Ventas hereda objeciones evitables |
| Lenguaje de categoría débil | La IA describe la marca con posicionamiento genérico o antiguo | La marca pierde diferenciación en prompts comparativos |
| Comparaciones sesgadas | La IA repite afirmaciones antiguas de páginas de terceros | El tráfico de evaluación se desplaza a competidores |
| Datos de implementación inconsistentes | La IA da tiempos, rutas de integración o estado de cumplimiento equivocados | Compras y equipos técnicos pierden confianza |
| Jerarquía de fuentes poco clara | La IA cita fuentes secundarias en vez de documentación oficial | Las páginas correctas no se vuelven la referencia confiable |
Por eso una marca puede tener buen tráfico SEO y aun así rendir mal en búsqueda con IA. Las páginas posicionadas no bastan si los hechos recuperados están llenos de ruido.
Por qué este detalle se pasa por alto
Muchos programas GEO empiezan con seguimiento de prompts: “¿ChatGPT nos menciona?”, “¿Perplexity nos cita?”, “¿Aparecemos en AI Overviews?”. Son preguntas importantes, pero pueden ocultar un segundo problema.
Una mención de marca puede ser negativa, incorrecta, parcial, obsoleta o comercialmente inútil.
Por ejemplo, un proveedor puede aparecer en una respuesta para “mejores herramientas de automatización de flujos para equipos financieros”, pero la misma respuesta puede decir que solo sirve para equipos pequeños, que no tiene API o que su documentación de seguridad es poco clara. Si esas afirmaciones son falsas, la visibilidad se convierte en una fuga de conversión.
El problema de fondo es que las respuestas de IA se construyen desde la confianza en las fuentes, no desde la preferencia por una marca. Modelos y sistemas de recuperación buscan información repetida, accesible, semánticamente clara y corroborada. Si los hechos equivocados son más fáciles de encontrar que los corregidos, pueden ganar.
La visión de Auspia: en 2026, los equipos GEO deben medir tres capas a la vez:
- Presencia: si la marca aparece en respuestas relevantes.
- Precisión: si la respuesta refleja hechos actuales.
- Dirección comercial: si la respuesta ayuda a un comprador calificado a dar el siguiente paso.
La mayoría mide demasiado la presencia y demasiado poco la precisión.
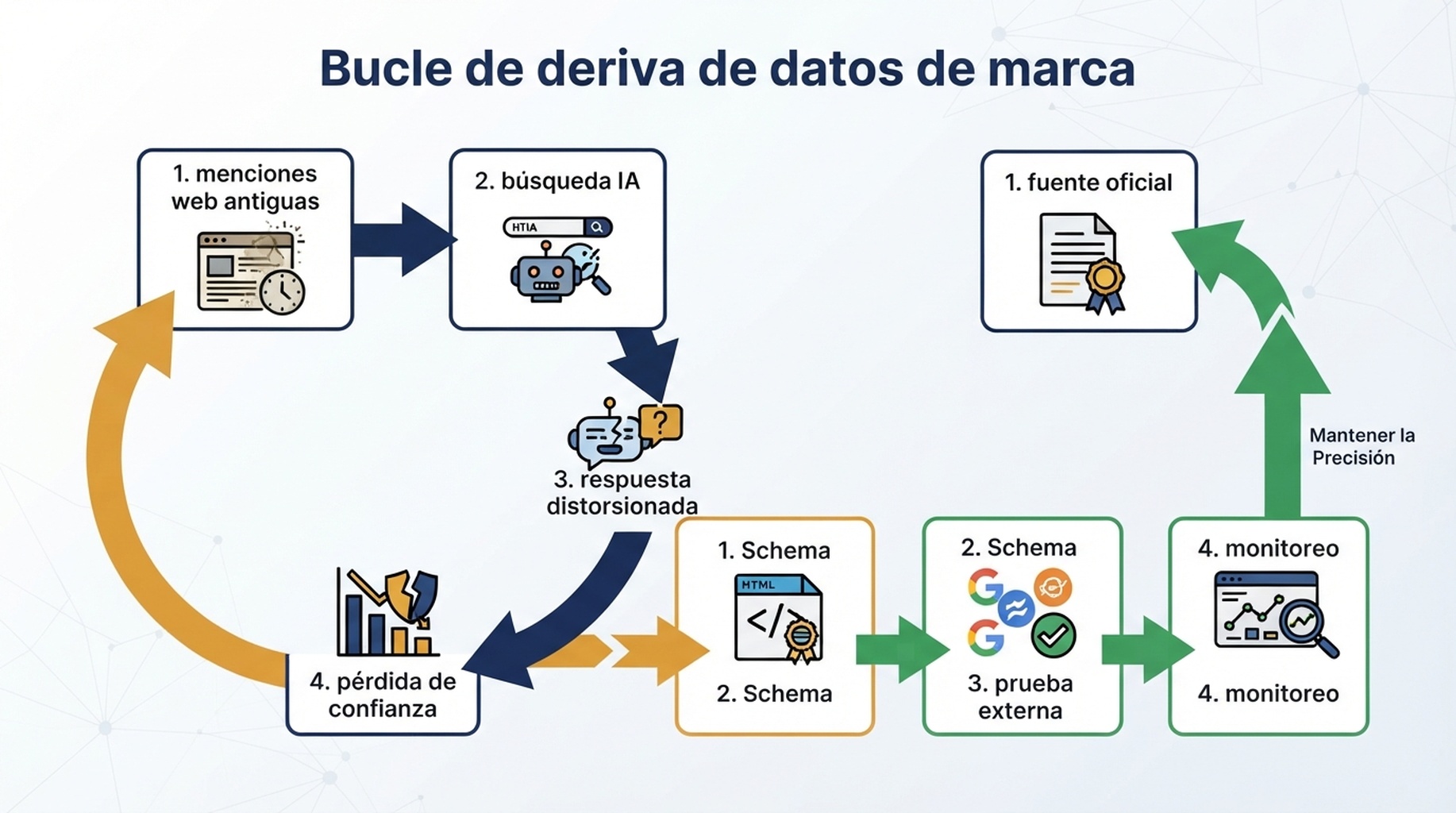
El bucle de deriva de hechos de marca
La contaminación de datos de IA suele seguir un bucle repetible.
Leyenda: La deriva se agrava cuando páginas antiguas, jerarquía débil de fuentes y respuestas de IA sin monitoreo se refuerzan entre sí.
El bucle en lenguaje simple:
- La marca cambia más rápido que la web. Producto, precios, empaquetado, integraciones, cumplimiento y segmentos de cliente evolucionan.
- Las fuentes antiguas siguen siendo rastreables. PDFs, comparativas, perfiles, páginas de partners, menciones en medios y foros continúan circulando.
- La IA encuentra evidencia mezclada. Ve afirmaciones actuales y obsoletas sin entender siempre recencia o autoridad.
- La respuesta comprime matices. Hechos contradictorios se convierten en una frase confiada.
- El comprador actúa sobre esa síntesis. Excluye la marca, hace la pregunta equivocada o elige un competidor.
- La respuesta contaminada crea contenido descendente. La gente copia el resumen en documentos, posts, notas de ventas y reseñas.
Romper el bucle requiere más que publicar un artículo correctivo. Necesitas un sistema de reparación repetible.
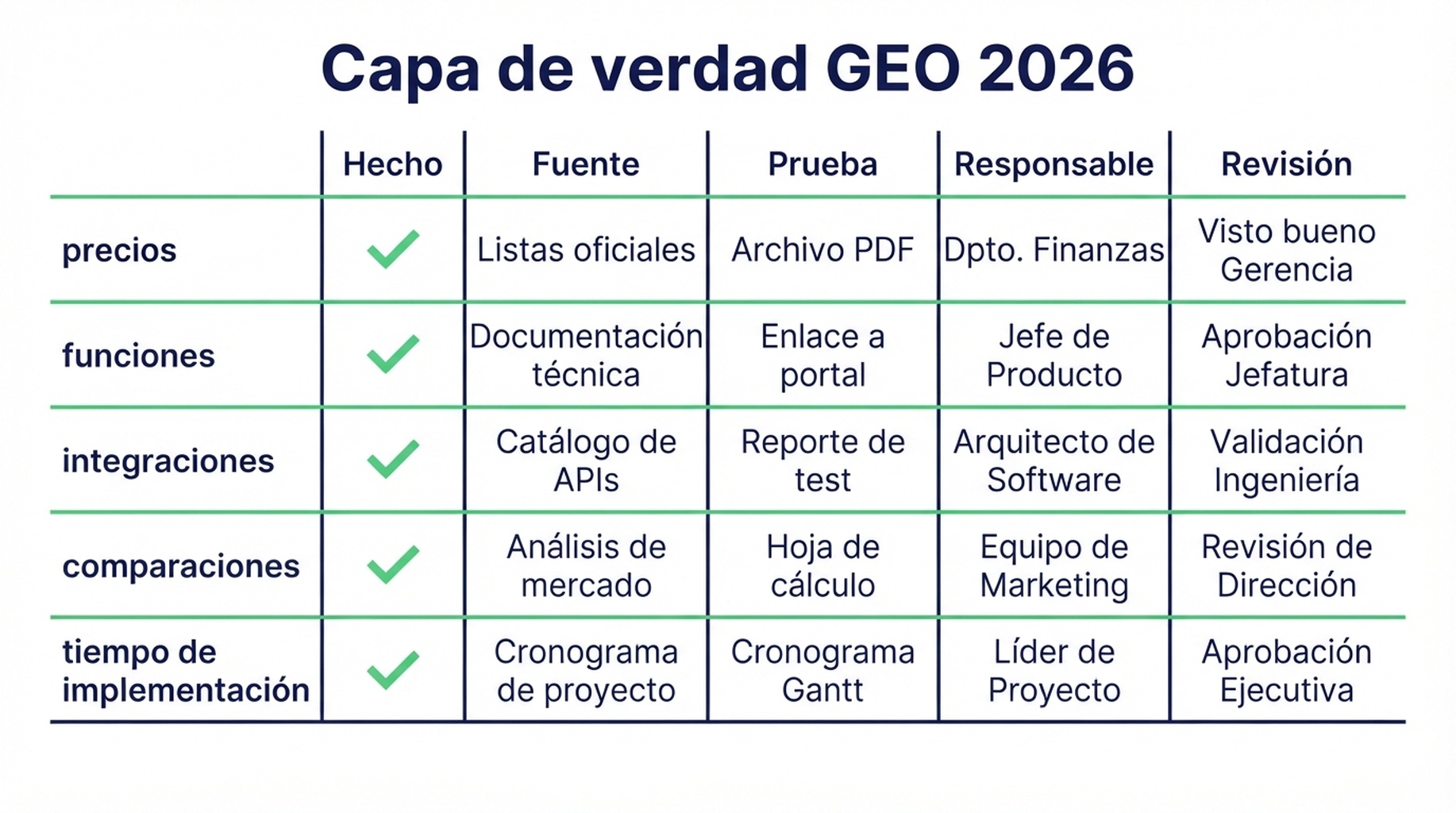
Construye una capa de verdad GEO 2026
Una capa de verdad GEO es un activo operativo: una fuente actual, estructurada y verificable de hechos de marca que humanos y sistemas de IA pueden entender.
No debe vivir solo en una presentación. Debe reflejarse en web, documentación, Schema, páginas comparativas, perfiles de partners, descripciones en reseñas, boilerplates de PR, help center y materiales de ventas.
Una capa práctica incluye cinco partes:
| Activo | Qué controla | Campos de ejemplo |
|---|---|---|
| Registro de hechos de marca | Versión canónica de afirmaciones importantes | Categoría, usuarios objetivo, casos de uso, límites de precio, modelo de despliegue |
| Páginas oficiales de prueba | Páginas que la IA puede recuperar y citar | Producto, docs, seguridad, integraciones, historias de clientes |
| Datos estructurados y entidades claras | Contexto legible por máquinas | Organization schema, Product schema, FAQ schema, sameAs, autor/editor |
| Corroboración externa | Evidencia fuera de tu sitio | Partners, analistas, perfiles de reseñas, respuestas de comunidad |
| Monitoreo y cola de corrección | Flujo para detectar y corregir distorsión | Checks de prompts, fuentes citadas, owner, prioridad, estado |
Una hoja de cálculo ligera basta para empezar. La clave es la propiedad: cada hecho crítico necesita URL fuente, tipo de prueba, responsable y cadencia de revisión.
Cinco correcciones pequeñas que suelen mejorar la precisión
No necesitas reconstruir todo el sitio antes de actuar. Empieza por los hechos que cambian decisiones de compra.
1. Crea una página de “hechos actuales” para tu categoría
Crea una página que diga qué es el producto, para quién es, qué hace, qué no hace y cuándo se revisaron esos datos. Usa lenguaje directo, no copy de folleto.
Incluye:
- Qué hace el producto en una frase
- Casos de uso principales
- Cliente ideal
- Notas de despliegue e integración
- Explicación de precio o límites de precio
- Enlaces de seguridad y cumplimiento
- Malentendidos comunes
- Fecha de última revisión
Esta página puede convertirse en referencia para equipos internos y correcciones externas.
2. Reescribe comparativas con criterios verificables
La IA usa comparativas en prompts de evaluación. Si tus comparativas son vagas, defensivas o promocionales, sirven menos como fuente.
Hazlas más extractables:
- Declara criterios antes de la conclusión.
- Separa hechos de opiniones.
- Enlaza docs oficiales para funciones, integraciones, precios y cumplimiento.
- Incluye “cuándo no elegirnos” cuando sea honesto.
- Evita atacar competidores con afirmaciones no verificables.
Las comparativas claras reducen el riesgo de que la IA repita el encuadre de un competidor como si fuera neutral.
3. Añade bloques de malentendidos en páginas de alta intención
Si la IA repite el mismo error, contéstalo directamente en la página relevante.
Ejemplo:
Malentendido común: algunas fuentes antiguas describen Product X como adecuado solo para equipos pequeños. En la línea 2026, Product X admite SSO enterprise, control de acceso por roles, logs de auditoría y despliegue privado. Consulta la documentación de seguridad y la guía de despliegue enterprise.
Funciona porque da una corrección clara, una fecha actual y enlaces de soporte.
4. Limpia perfiles de terceros antes de publicar más contenido
Muchos equipos publican contenido GEO nuevo mientras ignoran perfiles antiguos en reseñas, marketplaces, directorios de partners, GitHub, app stores, mirrors de docs y media kits.
Lista las 20 páginas con más probabilidad de recuperarse para prompts de marca y comparación. Actualízalas antes de crear otro artículo genérico.
Prioriza páginas que ya posicionan, se citan o aparecen como fuentes de respuestas de IA.
5. Mide precisión, no solo menciones
Un tracker de prompts no debe registrar solo si aparece la marca. Añade etiquetas de precisión.
Sistema simple:
| Puntuación | Significado | Acción |
|---|---|---|
| 0 | Marca ausente | Añadir o fortalecer contenido fuente |
| 1 | Marca mencionada pero incorrecta | Identificar afirmación falsa y ruta de fuente |
| 2 | Marca mencionada pero incompleta | Añadir pruebas o secciones más claras |
| 3 | Marca precisa pero débilmente posicionada | Mejorar criterios comparativos y casos de uso |
| 4 | Marca precisa y útil comercialmente | Monitorear y preservar consistencia |
Así GEO pasa de reporte de vanidad a flujo operativo.
Sprint de 14 días para reparar información distorsionada
Si sospechas que la IA representa mal tu marca, ejecuta un sprint de dos semanas.
Días 1-2: reúne prompts
Recoge 30-50 prompts de llamadas de ventas, SEM, soporte, búsquedas comparativas y objeciones. Incluye marca, categoría, funciones, precio, integración, implementación y competidores.
Días 3-4: captura respuestas
Prueba los prompts en las superficies de IA que usan tus compradores. Registra respuesta, posición de marca, citas disponibles, afirmaciones incorrectas e impacto comercial.
Días 5-6: rastrea fuentes contaminadas
Para cada afirmación incorrecta, identifica la familia de fuente probable: página oficial, PDF antiguo, reseña, comparativa, partner, foro, marketplace o competidor.
Días 7-9: repara fuentes oficiales
Actualiza primero lo que controlas. Añade definiciones claras, fechas, Schema, FAQ, secciones de malentendidos y enlaces de prueba.
Días 10-11: repara perfiles externos
Actualiza perfiles de autoridad, textos de partners, reseñas y marketplaces. Si no puedes editar, publica una referencia mejor y pide a partners que la usen.
Días 12-13: publica pruebas corroborables
Crea una o dos piezas de evidencia: caso de cliente, guía de integración, explicación de seguridad, guía de implementación, benchmark o comparativa. Hazla factual y citable.
Día 14: vuelve a probar y prioriza
Ejecuta el set de prompts otra vez. Algunas respuestas no cambiarán al instante, pero verás qué problemas son brechas de fuente, retrasos de rastreo o contaminación externa.
Para una línea base más rápida, usa una herramienta como AI Search Visibility Checker de Auspia para convertir prompts, respuestas y presencia de marca en una revisión repetible.
Qué medir después de la limpieza
No esperes que todas las respuestas cambien de un día a otro. Cada sistema usa recuperación, índices, citas, navegación y reglas de generación distintas. Mide tendencia, no una captura perfecta.
Mide semanalmente:
| Métrica | Qué indica |
|---|---|
| Tasa de precisión de respuestas de marca | Si la IA refleja hechos actuales |
| Frecuencia de afirmaciones falsas | Qué distorsiones se repiten |
| Concentración de fuentes | Si se citan fuentes oficiales y de calidad |
| Cobertura de prompts de alta intención | Si la marca aparece en preguntas de compra |
| Utilidad comercial | Si la respuesta ayuda a evaluar, comparar o contactar |
| Latencia de corrección | Cuánto tarda una fuente reparada en influir en la IA |
Los mejores programas GEO crean un bucle: auditoría de respuestas, reparación de fuentes, pruebas, corrección externa, retest y aprendizaje para ventas.
Errores comunes
Error 1: tratar GEO como distribución de PR. Publicar más artículos no corrige hechos contaminados si la jerarquía de fuentes está desordenada.
Error 2: corregir solo el sitio oficial. Las respuestas de IA suelen venir de fuentes externas. Reseñas, partners y comparativas antiguas también importan.
Error 3: usar posicionamiento vago. “Plataforma de IA todo en uno” no es un hecho. La IA necesita casos de uso, entidades, integraciones, industrias y límites concretos.
Error 4: esconder hechos en PDFs o imágenes. Si importa para respuestas de IA, debe estar en HTML rastreable y extraíble.
Error 5: medir solo share of voice. Una respuesta visible pero falsa puede dañar más el viaje de compra que la ausencia.
FAQ
¿Qué es la contaminación de datos de IA en GEO?
Es la presencia de información pública antigua, incorrecta, sesgada, duplicada o inconsistente que los sistemas de búsqueda con IA pueden recuperar y sintetizar en respuestas de marca. Se vuelve un problema GEO cuando afecta visibilidad, confianza o conversión.
¿Por qué las herramientas de IA dan información de marca incorrecta?
Porque las fuentes públicas discrepan, las páginas oficiales son poco claras, las páginas antiguas siguen accesibles, los perfiles de terceros están desactualizados o las comparativas son más fáciles de recuperar que la documentación actual. La respuesta puede sonar segura aunque la evidencia esté mezclada.
¿Cómo se corrigen hechos de marca distorsionados en búsqueda con IA?
Audita prompts de alta intención, registra afirmaciones falsas, rastrea familias de fuentes, actualiza páginas oficiales, limpia perfiles externos, añade datos estructurados, publica pruebas corroborables y vuelve a probar los mismos prompts de forma recurrente.
¿Debe un equipo GEO priorizar citas o precisión?
Para prompts críticos de marca, la precisión va primero. Más citas no ayudan si la información citada es falsa u obsoleta. Cuando la capa de verdad está estable, el crecimiento de citas es más seguro y valioso.
¿Con qué frecuencia se debe monitorear la precisión en 2026?
En B2B, SaaS, salud, finanzas, ecommerce y categorías técnicas de alto crecimiento, el monitoreo semanal de prompts de alta intención es una base práctica. En categorías evergreen de menor riesgo puede bastar mensual, pero cualquier cambio grande de producto, precio o posicionamiento exige una nueva auditoría.
Conclusión
El detalle GEO olvidado en 2026 no es si la IA puede mencionar tu marca. Es si puede repetir la versión correcta de tu marca.
Si tu capa pública de información está contaminada, la búsqueda con IA puede amplificar la historia equivocada justo cuando el comprador evalúa proveedores. La solución es operativa: crea una capa de verdad, limpia fuentes de alto riesgo, estructura hechos importantes, corrobóralos en canales confiables y monitorea la precisión.
Así GEO pasa de “trabajo de visibilidad” a gobernanza de información de marca.
Author: Lydia Hart, estratega de entidades de marca en Auspia con más de 200 auditorías de entidad revisadas. Lydia escribe sobre hechos de marca, consistencia de entidades, páginas About, lenguaje de categoría y preparación para knowledge graphs.