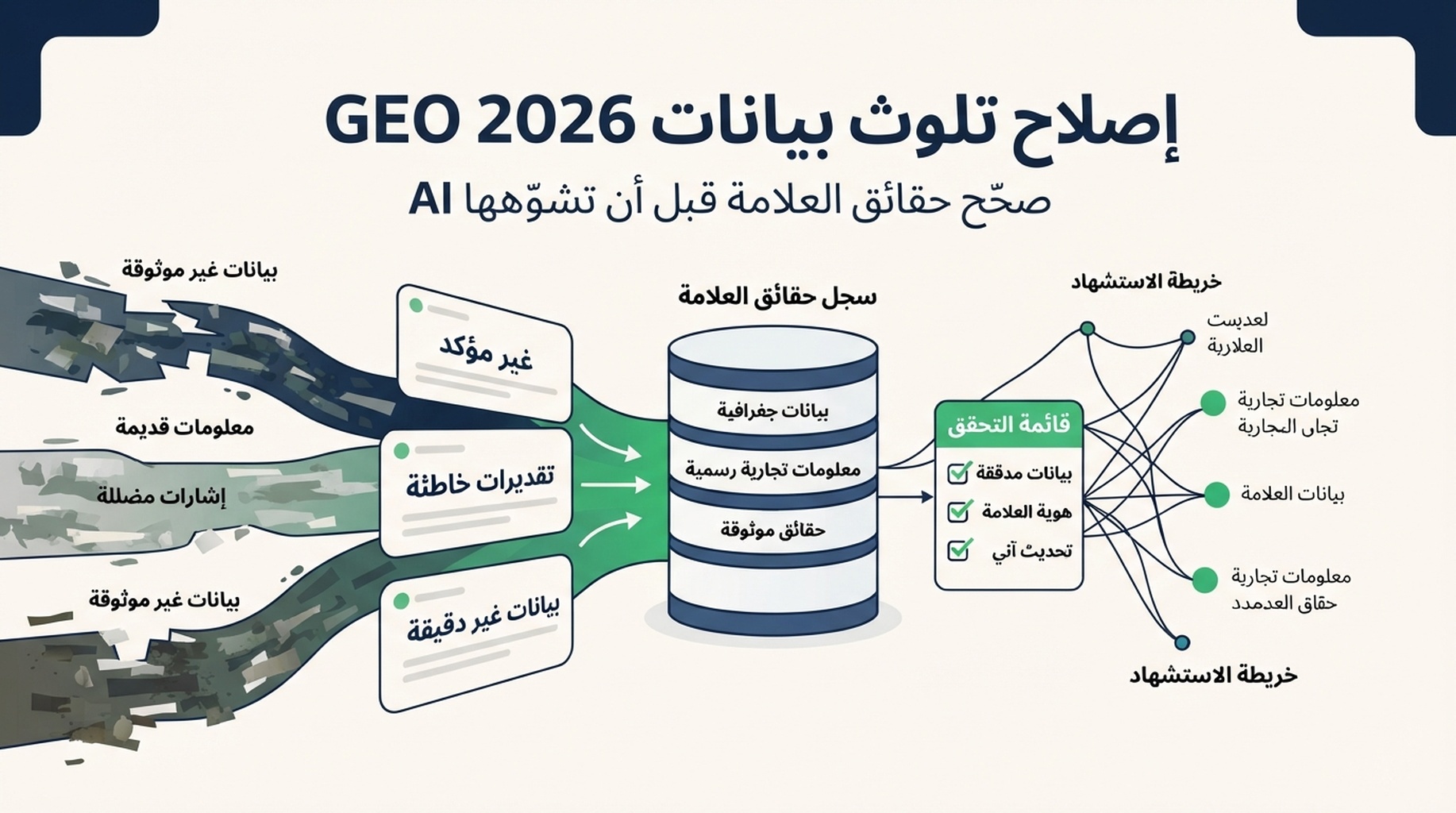
مشكلة 2026: قد تحوّل إجابات AI بيانات العلامة القديمة إلى خطر جديد على المشتري
في 2026، من أسهل تفاصيل GEO التي يمكن إغفالها ليست تغطية الكلمات المفتاحية، بل دقة حقائق العلامة التجارية.
عندما تجيب أنظمة البحث المدعومة بـ AI عن أسئلة المشترين، فهي غالبًا تجمع معلومات من صفحات كثيرة: موقعك، صفحات شركاء قديمة، أدلة غير محدثة، مقالات مقارنة، قواعد بيانات منتجات، منتديات، تغطيات إعلامية، مواقع مراجعات، ومحتوى المنافسين. حتى إذا تعارضت هذه المصادر، قد تبدو الإجابة واثقة. قد يرى المشتري مدة تنفيذ خاطئة، نطاق سعر قديم، تكاملًا مفقودًا، أو مقارنة متحيزة قبل أن يصل إلى موقعك.
هذا هو تلوث بيانات AI في سياق GEO: مصادر عامة ملوثة أو غير متسقة يتم استرجاعها وخلطها وتكرارها كأنها معرفة حديثة. بالنسبة لعلامات B2B وSaaS، ليست هذه مشكلة سمعة فقط. إنها تؤثر في نية طلب demo، واعتراضات المبيعات، وثقة فرق الشراء، ودخول العلامة في shortlist.
الحل العملي هو بناء طبقة حقيقة GEO 2026: حقائق علامة محدثة، صفحات منظمة، أدلة من طرف ثالث، مسارات تصحيح، ومراقبة متكررة لإجابات AI. لم يعد GEO يعني مجرد الظهور. يجب أن تكون الإشارة دقيقة بما يكفي لتدفع المشتري إلى الخطوة التالية.
التعليق: يجب أن يتعامل برنامج GEO في 2026 مع إجابات AI غير الدقيقة كمسألة جودة مصادر قابلة للإصلاح، لا كمشكلة ظهور فقط.
كيف يظهر تلوث بيانات AI في GEO
يبدأ التلوث عادة بانحراف صغير. تغير العلامة باقاتها أو أسعارها أو تموضعها أو قدرات المنتج. يتم تحديث الموقع الرسمي، لكن الصفحات القديمة تبقى في أماكن أخرى. يستخدم بعض الشركاء النص القديم. يلخص موقع مراجعات المنتج بشكل خاطئ. تصف صفحة مقارنة لمنافس العلامة من زاوية ضعف قديمة. يحتفظ مركز المساعدة بمصطلحات قديمة. بعد ذلك تسترجع أنظمة AI أجزاء من هذا السجل المختلط.
النتيجة هي انحراف حقائق العلامة: طبقة المعلومات العامة تبتعد تدريجيًا عن واقع العمل الحالي.
| إشارة ملوثة | كيف تظهر في إجابات AI | لماذا تضر النمو |
|---|---|---|
| أسعار قديمة | يذكر AI خططًا قديمة أو قواعد trial خاطئة أو نطاقات enterprise غير دقيقة | يستبعد المشتري نفسه قبل التواصل مع sales |
| نطاق ميزات خاطئ | يقول AI إن ميزة موجودة غير موجودة أو يعد بميزة غير موجودة | يتعامل sales مع اعتراضات كان يمكن منعها |
| لغة فئة ضعيفة | يصف AI العلامة بتموضع عام أو قديم | تفقد العلامة تميزها في prompts المقارنة |
| مقارنة منافسين متحيزة | يكرر AI claims قديمة من صفحات خارجية | ينتقل traffic التقييم إلى المنافسين |
| بيانات تنفيذ غير متسقة | وقت setup أو integration أو compliance خاطئ | تفقد فرق الشراء والتقنية الثقة |
| هرمية مصادر غير واضحة | يقتبس AI مصادر ثانوية بدل الوثائق الرسمية | لا تصبح الصفحات الصحيحة مرجعًا موثوقًا |
لذلك قد تملك العلامة زيارات SEO جيدة وتفشل في AI search إذا كانت الحقائق المسترجعة مليئة بالضجيج.
لماذا يتم إغفال هذا التفصيل
تبدأ برامج GEO كثيرة بتتبع prompts: هل يذكرنا ChatGPT؟ هل يقتبسنا Perplexity؟ هل نظهر في AI Overviews؟ هذه أسئلة مهمة، لكنها قد تخفي مشكلة ثانية.
قد تكون إشارة العلامة سلبية أو خاطئة أو ناقصة أو قديمة أو غير مفيدة تجاريًا.
مثلًا، قد يظهر مزود في إجابة عن “أفضل أدوات workflow automation لفرق finance”، لكن الإجابة نفسها تقول إنه مناسب للفرق الصغيرة فقط، أو لا يملك API، أو أن وثائق security غير واضحة. إذا كان ذلك غير صحيح، تتحول visibility إلى تسرب في conversion.
المشكلة الأعمق أن إجابات AI تُبنى على الثقة بالمصادر، لا على تفضيل العلامة. تبحث النماذج وأنظمة retrieval عن معلومات متكررة وسهلة الوصول وواضحة ومؤكدة. إذا كانت الحقائق الخاطئة أسهل من الحقائق المصححة، قد تنتصر.
رأي Auspia: في 2026، يجب أن تقيس فرق GEO ثلاث طبقات معًا:
- الحضور: هل تظهر العلامة في الإجابات ذات الصلة؟
- الدقة: هل تعكس الإجابة الحقائق الحالية؟
- الاتجاه التجاري: هل تساعد الإجابة مشتريًا مؤهلًا على التقدم؟
تقيس فرق كثيرة الحضور أكثر من اللازم، والدقة أقل من اللازم.
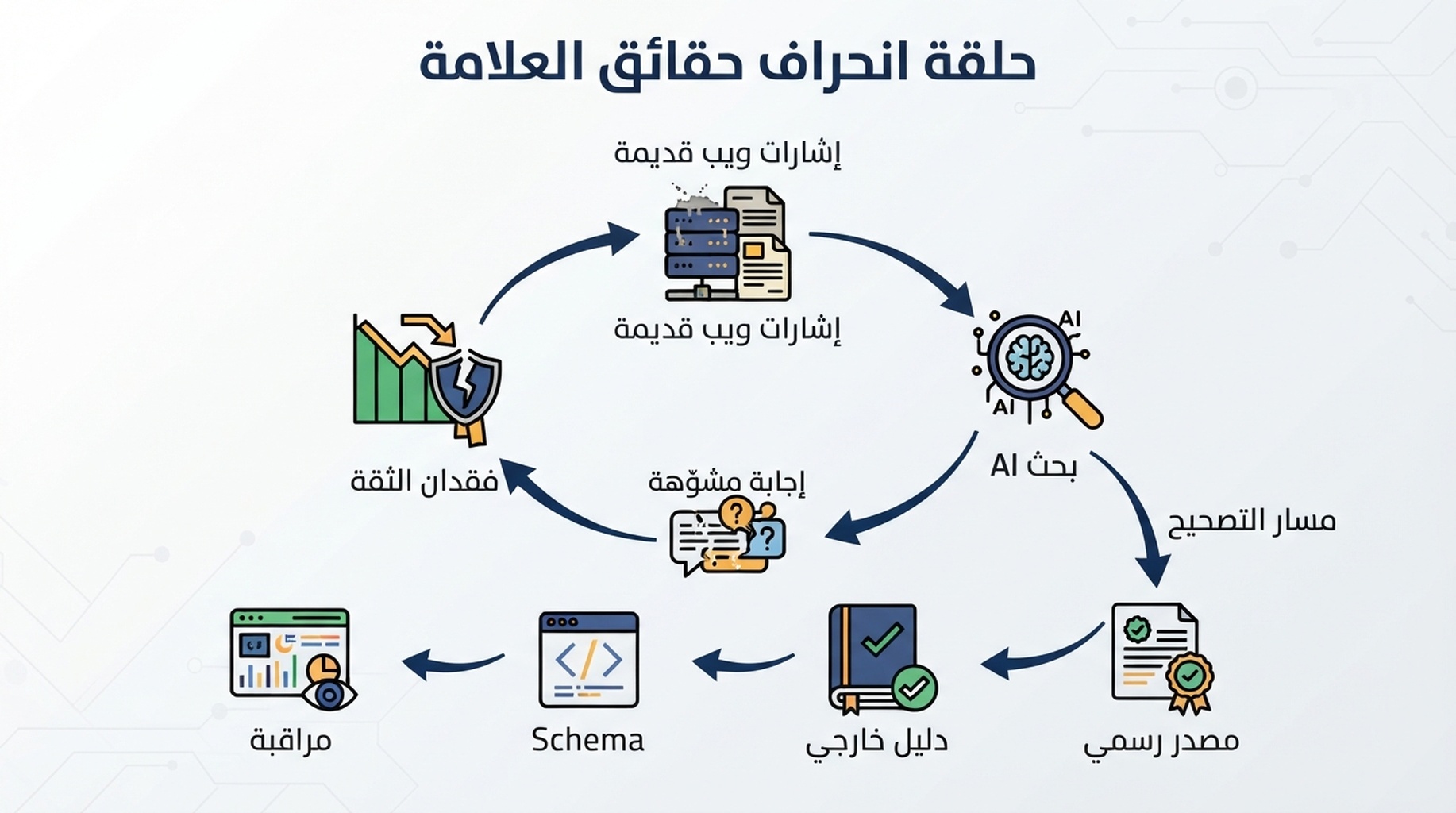
حلقة انحراف حقائق العلامة
يتبع تلوث بيانات AI غالبًا حلقة قابلة للتكرار.
التعليق: الصفحات القديمة، وضعف هرمية المصادر، وإجابات AI غير المراقبة تضخم انحراف حقائق العلامة.
- تتغير العلامة أسرع من الويب. المنتج والأسعار والتكاملات والامتثال وشرائح العملاء تتطور.
- تبقى المصادر القديمة قابلة للزحف. PDF ومقارنات وprofiles وصفحات partners وmedia وforums تستمر في التداول.
- يعثر AI على أدلة مختلطة. يرى ادعاءات حديثة وقديمة دون فهم كامل للحداثة أو السلطة.
- تضغط الإجابة الفروق الدقيقة. تتحول الحقائق المتعارضة إلى جملة واثقة.
- يتصرف المشتري بناء عليها. يستبعد العلامة أو يسأل سؤالًا خاطئًا أو يختار منافسًا.
- تخلق الإجابة الملوثة محتوى لاحقًا. تُنسخ الملخصات إلى documents وposts وsales notes وreviews.
كسر الحلقة يحتاج نظام إصلاح متكررًا، لا مقال تصحيح واحدًا.
بناء طبقة حقيقة GEO 2026
طبقة حقيقة GEO هي أصل تشغيلي: مصدر حديث ومنظم وقابل للتحقق لحقائق العلامة، يفهمه البشر وأنظمة AI.
يجب أن تظهر في الموقع والوثائق وSchema وصفحات المقارنة وprofiles الشركاء ومواقع المراجعات وPR boilerplate وhelp center ومواد sales.
| الأصل | ما يتحكم به | أمثلة |
|---|---|---|
| سجل حقائق العلامة | النسخة الرسمية من claims المهمة | الفئة، المستخدمون، use cases، حدود السعر، deployment |
| صفحات دليل رسمية | صفحات يمكن لـ AI استرجاعها واقتباسها | المنتج، docs، security، integrations، قصص العملاء |
| بيانات منظمة وentities | سياق تقرأه الآلة | Organization schema، Product schema، FAQ schema، sameAs، الكاتب/الناشر |
| تأكيد خارجي | دليل خارج موقعك | partners، analysts، reviews، community |
| مراقبة وقائمة تصحيح | workflow ضد التشويه | prompts، cited sources، owner، priority، status |
تكفي spreadsheet خفيفة للبدء. كل حقيقة حرجة تحتاج URL مصدر، نوع دليل، مسؤولًا، وإيقاع مراجعة.
خمس إصلاحات صغيرة تحسن دقة AI غالبًا
1. أنشئ صفحة “الحقائق الحالية” للفئة
اشرح ما المنتج، لمن هو، ماذا يفعل، ماذا لا يفعل، ومتى تمت مراجعة الحقائق. أضف تعريفًا من جملة واحدة، use cases، العميل الأنسب، deployment، integrations، السعر، security، سوء الفهم الشائع، وتاريخ المراجعة.
2. أعد كتابة صفحات المقارنة بمعايير قابلة للتحقق
اذكر المعايير قبل الخلاصة. افصل الحقائق عن الرأي. اربط الوثائق الرسمية للميزات والتكاملات والأسعار والامتثال. اذكر متى لا يجب اختياركم. تجنب claims غير مثبتة ضد المنافسين.
3. أضف كتل تصحيح سوء الفهم في الصفحات عالية النية
إذا كرر AI الخطأ نفسه، صححه مباشرة.
سوء فهم شائع: تصف بعض المصادر القديمة Product X كحل مناسب للفرق الصغيرة فقط. في خط 2026، يدعم Product X enterprise SSO وRBAC وaudit logs وprivate deployment. راجع وثائق security ودليل enterprise.
4. نظف profiles الخارجية قبل نشر محتوى أكثر
حدّث مواقع المراجعات وmarketplaces وأدلة partners وGitHub وapp stores وmirrors الوثائق وmedia kits القديمة. اكتب قائمة بأكثر 20 صفحة يحتمل استرجاعها في prompts العلامة والمقارنة، وابدأ بما يظهر في ranking أو citations.
5. قِس الدقة لا مجرد الإشارات
| الدرجة | المعنى | الإجراء |
|---|---|---|
| 0 | العلامة غائبة | أضف أو قوِّ مصادر المحتوى |
| 1 | مذكورة لكن خاطئة | حدد claim الخاطئ ومسار المصدر |
| 2 | مذكورة لكن ناقصة | أضف دليلًا أو أقسامًا أوضح |
| 3 | دقيقة لكن التموضع ضعيف | حسّن المعايير وuse cases |
| 4 | دقيقة ومفيدة تجاريًا | راقب وحافظ على الاتساق |
هكذا يتحول GEO إلى workflow تشغيلي، لا تقرير vanity.
Sprint من 14 يومًا لإصلاح معلومات العلامة المشوهة
اليومان 1-2: اجمع prompts. اجمع 30-50 prompt من sales calls وSEM وsupport وعمليات المقارنة والاعتراضات.
اليومان 3-4: سجّل إجابات AI. اختبر على المنصات التي يستخدمها المشترون. سجل الإجابة، موضع العلامة، citations، الأخطاء، والأثر التجاري.
اليومان 5-6: تتبع المصادر الملوثة. صنف كل خطأ: صفحة رسمية، PDF قديم، review، comparison، partner، forum، marketplace، أو competitor.
الأيام 7-9: أصلح المصادر الرسمية. أضف definitions وتواريخ وSchema وFAQ وكتل سوء فهم وروابط دليل.
اليومان 10-11: أصلح profiles الخارجية. حدّث المصادر الخارجية القوية ونصوص partners وreviews وmarketplaces. إذا تعذر التعديل، انشر مرجعًا عامًا أفضل.
اليومان 12-13: انشر أدلة. أنشئ case study أو integration guide أو security explainer أو implementation guide أو benchmark أو comparison مبنيًا على حقائق.
اليوم 14: أعد الاختبار ورتب الأولويات. شغّل prompts نفسها لتمييز فجوات المصادر وتأخر الزحف والتلوث الخارجي.
لإنشاء baseline أسرع، يمكن استخدام AI Search Visibility Checker من Auspia لتحويل prompts والإجابات وحضور العلامة إلى مراجعة متكررة.
ما الذي يجب قياسه بعد التنظيف
لا تتوقع تحديث كل الإجابات فورًا. تختلف الأنظمة في retrieval وindex وcitations وbrowsing وgeneration. قِس الاتجاه.
| المقياس | ما يوضحه |
|---|---|
| دقة إجابات العلامة | هل يعكس AI الحقائق الحالية |
| تكرار claims الخاطئة | ما التشويهات التي تستمر |
| تركّز المصادر | هل تُقتبس مصادر رسمية وعالية الجودة |
| تغطية prompts عالية النية | هل تظهر العلامة في أسئلة الشراء |
| الفائدة التجارية | هل تساعد الإجابة على التقييم أو المقارنة أو التواصل |
| زمن التصحيح | كم يلزم لتؤثر المصادر المصححة في AI |
أفضل برامج GEO تبني حلقة: audit للإجابات، إصلاح مصادر، محتوى دليل، تصحيح خارجي، retest، وتعلّم لفريق sales.
أخطاء شائعة
الخطأ 1: اعتبار GEO توزيع PR. نشر مقالات أكثر لا يصلح حقائق ملوثة إذا كانت هرمية المصادر فوضوية.
الخطأ 2: تصحيح الموقع الرسمي فقط. تأتي إجابات AI غالبًا من مصادر خارجية.
الخطأ 3: استخدام تموضع غامض. “منصة AI شاملة” ليست حقيقة.
الخطأ 4: إخفاء الحقائق في PDF أو الصور. يجب أن تكون المعلومات المهمة في HTML قابل للزحف والاستخراج.
الخطأ 5: قياس share of voice فقط. إجابة مرئية لكنها خاطئة قد تضر أكثر من الغياب.
FAQ
ما هو تلوث بيانات AI في GEO؟
هو وجود معلومات عامة قديمة أو خاطئة أو متحيزة أو مكررة أو غير متسقة يمكن لأنظمة AI search استرجاعها وصياغتها في إجابات عن العلامة.
لماذا تخطئ أدوات AI في معلومات العلامة؟
لأن المصادر العامة تتعارض، أو الصفحات الرسمية غير واضحة، أو الصفحات القديمة ما زالت متاحة، أو profiles الخارجية قديمة، أو المقارنات أسهل في الاسترجاع من الوثائق الحديثة.
كيف نصلح حقائق العلامة المشوهة؟
ابدأ بتدقيق prompts عالية النية، وسجل claims الخاطئة، وتتبع عائلات المصادر، وحدّث الصفحات الرسمية، ونظف profiles الخارجية، وأضف structured data، وانشر أدلة، وأعد الاختبار دوريًا.
هل تأتي citations أم الدقة أولًا؟
في prompts الحرجة للعلامة، تأتي الدقة أولًا. المزيد من citations لا يفيد إذا كانت المعلومات المقتبسة خاطئة أو قديمة.
كم مرة يجب المراقبة في 2026؟
لفئات B2B وSaaS والصحة والتمويل وecommerce والتقنية سريعة النمو، المراقبة الأسبوعية لـ prompts عالية النية baseline عملي. أي تغيير كبير في المنتج أو السعر أو التموضع يجب أن يطلق audit جديدًا.
الخلاصة
التفصيل المنسي في GEO لعام 2026 ليس ما إذا كان AI يستطيع ذكر علامتك. بل ما إذا كان يستطيع تكرار النسخة الصحيحة من علامتك.
إذا كانت طبقة المعلومات العامة ملوثة، فإن AI search قد يضخم القصة الخاطئة في لحظة تقييم المشتري للموردين. الحل تشغيلي: طبقة حقيقة، تنظيف مصادر عالية المخاطر، هيكلة الحقائق، تأكيدها في قنوات موثوقة، ومراقبة الدقة باستمرار.
هكذا ينتقل GEO من عمل visibility إلى حوكمة معلومات العلامة.
Author: Lydia Hart، Strategist لكيانات العلامة في Auspia عملت على أكثر من 200 audit للكيانات. تكتب Lydia عن حقائق العلامة، اتساق الكيانات، صفحات About، لغة الفئة، والاستعداد لـ knowledge graph.